去年11月以来,一款名为“ChatGPT”的聊天机器人程序开始在海外爆火,到今年2月份,ChatGPT更成为几乎每天都能见到相关热搜的“顶流”。
热烈的讨论声中,很多人惊呼:“《流浪地球2》里那个不断自我学习,最终演化出自主思维的‘MOSS’,或许离我们已经不远。”
也有人认为,ChatGPT与Siri、小爱同学、小度等人们熟悉的智能助手没有本质区别,不值得过多关注。
网友让它写诗、写小说、写工作简报、写朋友圈文案,甚至用它写代码、写论文……ChatGPT究竟是一款怎样的产品?它缘何突然爆火?它能做到哪些事情?会有人因此被“抢饭碗”吗?未来发展将走向何方?我们采访到业界专家和多位ChatGPT使用者,试图解答这些问题。
“不是新东西”的ChatGPT
突然就火了?
ChatGPT,全称是“Chat Generative Pre-trained Transformer”,可直译为“作交谈用的生成式预先训练变换器”。它是美国公司OpenAI研发的聊天机器人程序,能用于问答、文本摘要生成、机器翻译、分类、代码生成和对话AI。
到今年1月,ChatGPT仅用不到两个月时间,就累计了超过1亿用户,打破了此前Tik Tok用九个月时间将用户数累计到1亿的速度。
南开大学计算机学院、网络空间安全学院副院长刘晓光表示,虽然ChatGPT进入大众视野的时间并不长,但OpenAI的GPT产品几年前就已在从业者中产生巨大影响。从技术层面来说,ChatGPT并不是个新东西。
“2016—2020年,OpenAI陆续发布了GPT的1.0、2.0、3.0版本,去年11月底发布的ChatGPT可以视作GPT-3.5。虽然大多数普通人是最近才知道‘GPT’这种利用大数据的预训练大模型,但更早的GPT-3已经在计算机学界和业界产生很大的影响。国内一些互联网公司早在这波热潮前,就拥有自己的预训练大模型项目。”
刘晓光认为,ChatGPT之所以能够突然爆火,可能有这样几个原因:“一是此前几代GPT更多是面向商界提供技术支持,而ChatGPT则是直接面向大众,谁都可以提问,回答也只需等几秒,更多的人能简单而直观地了解它的作用;二是它发布时正值国外的大学考试季,很多学生拿它写论文、交作业,而ChatGPT能给出相对完整的回答,解决了学生的实际问题,由此迎来用户快速增长。当然,它火热到一定程度后,也不排除有科技巨头企业、科技媒体的过度关注和一些炒作现象。”
“好得吓人”?
ChatGPT突破了怎样的难点?
去年12月,埃隆·马斯克曾公开表示ChatGPT“好得吓人”(scary good),并认为强大到危险的人工智能已经离我们不远。微软联合创始人比尔·盖茨接受媒体采访时表示:“ChatGPT将改变我们的世界。”近日,京东集团副总裁何晓冬接受媒体采访时表示:“ChatGPT是第一款真正意义上的人工智能原生的产品,就像第一款iPhone,一出来就展现出高完整度,高体验性,高平台性。”
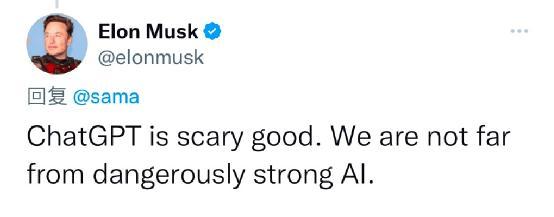
内嵌了ChatGPT的Bing搜索,直接制订了提问者想要的训练计划
但刘晓光同时表示,正如前面所指出ChatGPT尚存在缺陷,其回答仍时常表现出不可靠性:“就拿ChatGPT所呈现的文字表达来说,要将它应用于实际场景,还离不开人的指导、检查与验证。”
从社会分工的角度来说,面对ChatGPT的冲击,首当其冲的是重复性劳动较多的、不需要太多创造力的工作。而创造力,正是当前如何拼算力、烧财力,也无法让AI轻易跨越的一道鸿沟。
“人为什么会拥有创造力?迄今为止,这个问题连人类自己都无法说清,更遑论把创造力教给机器了。到目前为止,AI最擅长的仍然是‘照章办事’,本质上还突破不了‘创造力’这一关,ChatGPT也不例外。”刘晓光说道,“如果哪天AI突破了创造力这一关,那么人们要担心的,也不仅仅是某几个行业的就业岗位问题了——届时整个人类社会都会面临翻天覆地的变化。”
预训练大模型
未来将走向何方?
早在2015年奥特曼、彼得·泰尔、里德·霍夫曼和埃隆·马斯克等一群科技领袖创立OpenAI时,OpenAI还是一家非营利企业。公司创始人们认为,要避免人工智能技术垄断在少数巨头手中,要通过开源促进技术开放。
但随着项目进展,训练机器学习模型所需的资金越来越庞大,OpenAI开始成立一家营利性分支机构。2019年,风险投资人微软入局。时至今日,微软和OpenAI 之间的财务命运和技术变得越来越融合,今年1月份,随着ChatGPT的爆火,微软又向OpenAI追加了100亿美元的投资。
当前,ChatGPT仍处于免费试用状态,但不断有消息称其将很快推出收费版本。同时,Bing搜索已内嵌ChatGPT,更有消息称微软或将把ChatGPT嵌入Office办公软件中,这不啻将是对办公生态的又一次革新。
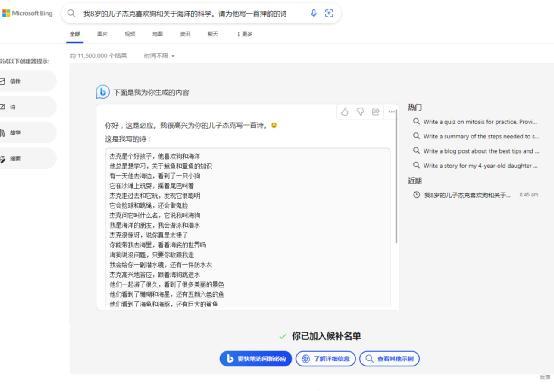
内嵌了ChatGPT的Bing搜索在写诗
“预训练大模型”类软件将走向何方?在业内人士看来,虽然ChatGPT的核心理论已不算新鲜,但开发同类产品所需的资金和人力,某种程度上已构成了新的门槛。
“早在前一代GPT中,模型训练一次的花费就高达千万乃至上亿美元,非常昂贵。OpenAI预计将在今年内发布GPT-4,那将是万众期待的进一步升级,同时也意味着它需要更多数据和更高计算力,这些都需要大量资金和人力。因此,开发同类产品的门槛在不断变高。”刘晓光说道。
大势之下,国内计算机业界有哪些机遇和挑战?刘晓光认为,当前国内外公司在开发预训练大模型产品的核心理论上,存在的差距并不算很大,但在数据采集、数据分析处理的能力上,“后来者”们仍有要追赶的距离。
“如果把机器赖以训练、学习的数据比作食材,那这种食材就需要通过收集、处理变成适合吸收的样子,这不是一项简单的工作。无论文字还是图片、视频,它们一般都需要进行人工标注,这不是短时间投入大量资金就能立刻见效的事,而是需要很多人力和时间的积累。因此业内也有说法称,数据才是互联网企业最重要的资产,甚至有人将数据比作企业的‘护城河’。”刘晓光说道。
“预训练大模型”类软件未来将如何发展?刘晓光认为或许将指向三个特征:“一是数据量越来越大,计算力越来越强,包罗万象;二是向专业化领域进军,在某一细分领域把信息精度做向极致,如医疗、法律、体育、编程等垂直分类;三是与具体应用场景深度结合,不仅仅停留在‘chat’,而是与虚拟人表演、电商营销、售后客服、陪护老幼人群、文艺创作等场景相结合。ChatGPT所展现的潜力,预示着它有能力在这些领域大有作为。”
来源: 天津日报
相关文章









关于作者

猜你喜欢
成员 网址收录40408 企业收录2984 印章生成248981 电子证书1108 电子名片64 自媒体77267































