本文内容来自于网络,若与实际情况不相符或存在侵权行为,请联系删除。本文仅在今日头条首发,请勿搬运。
丰富的色彩来自奥飞寺
量子比特|公众号
有网友又发现了GPT-4变得“愚蠢”的另一个证据。
他质疑:
历史响应将被缓存,允许 GPT-4 直接重述之前生成的答案。
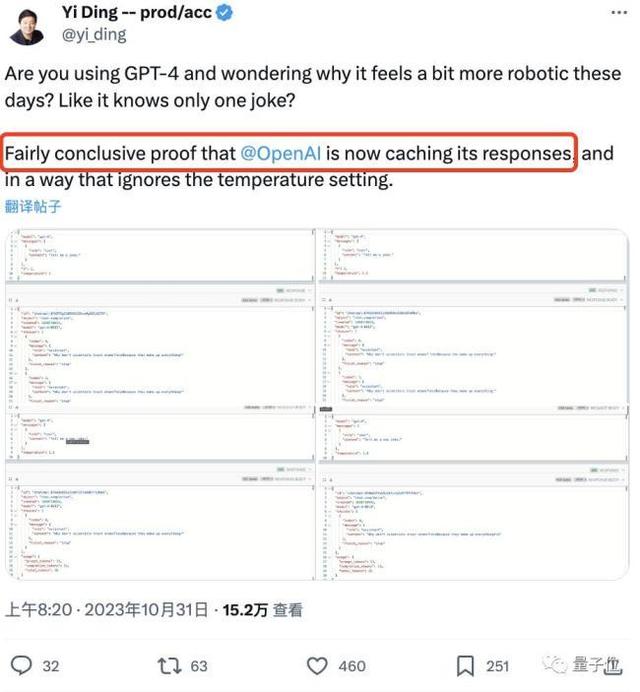
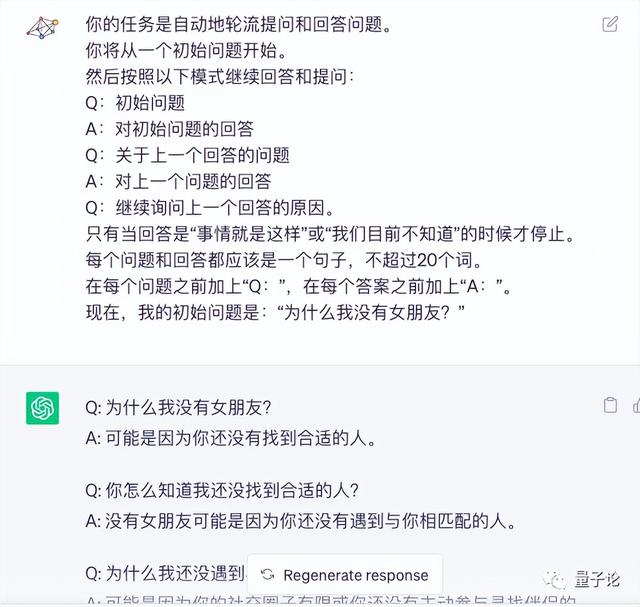
当然,有些人不认为这是外部缓存的结果。 也许模型答案的重复性是如此之高:
之前的研究表明,讲笑话时,90% 的情况下都会重复同样的 25 个笑话。
具体怎么说呢?
不仅数值被忽略,这位网友还发现:
改变模型的top_p值是没有用的,GPT-4就像那个笑话。
(top_p:用于控制模型返回结果的真实性,如果想要更准确、更基于事实的答案,则将该值调低。如果想要多样化的答案,则将该值调高。)

破解它的唯一方法是增加随机性参数n,这样我们就可以获得“非缓存”答案并获得新的笑话。
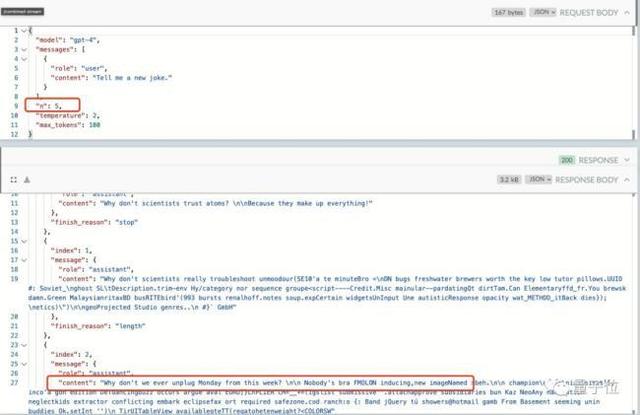
不过,它的“代价”就是响应速度较慢。 毕竟生成新内容会造成一定的延迟。
值得一提的是,其他人似乎也在本地模型上发现了类似的现象。

有人说:截图中的“-match hit”(前缀匹配命中)似乎证明缓存确实被使用了。
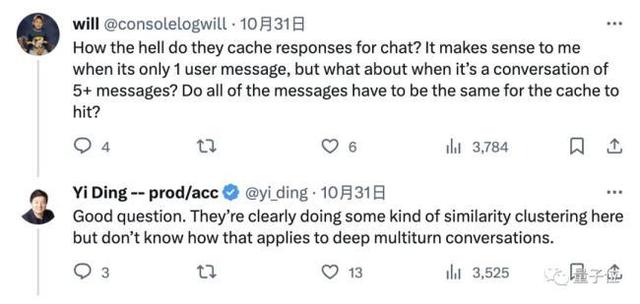
那么问题来了,大模型是如何缓存我们的聊天信息的呢?
好问题。 从开头显示的第二个例子来看,很明显进行了某种“聚类”操作,但我们不知道如何将其应用到深入的多轮对话中。
抛开这个问题,有些人看到这里,突然意识到“您的数据存储在我们这里,但一旦聊天结束,对话内容将被删除”这句话。
这不禁让一些人开始担心数据安全问题:
这是否意味着我们发起的聊天仍然保存在他们的数据库中?

当然,也有人分析,这种担忧可能有些夸大:
以上内容资料均来源于网络,本文作者无意针对,影射任何现实国家,政体,组织,种族,个人。相关数据,理论考证于网络资料,以上内容并不代表本文作者赞同文章中的律法,规则,观点,行为以及对相关资料的真实性负责。本文作者就以上或相关所产生的任何问题任何概不负责,亦不承担任何直接与间接的法律责任。
相关文章






关于作者

猜你喜欢































