最有希望超越GPT-4的模型来了——美国硅谷时间12月6日上午,谷歌CEO劈柴正式宣布,“大杀器”Gemini 1.0,正式上线。
Gemini是一个原生多模态大模型,谷歌在今年5月的I/O大会宣布开始研发后,Gemini的传说不断:将谷歌大脑和DeepMind部门合并,数百人攻坚,几乎耗尽谷歌内部计算资源……如此种种,只为和OpenAI一战。
但一直等到大半年后,OpenAI的GPT-4上线,GPT商店也把硅谷炸了一圈,Gemini才在千呼万唤中面世。

△图源:谷歌
一个月前,英伟达的资深科学家Jim Fan就为Gemini捏了把汗:“人们对谷歌Gemini的期望高得离谱!”
他表示,Meta要惊艳世界的话,只要让Llama 3开源就好了。但谷歌想要重夺当年AlphaGo的辉煌,Gemini不仅要100%达到GPT-4的能力,还要在成本或速度上比GPT-4更好。

△图源:谷歌
在通用的文字聊天场景里,Gemini聪明了不少。在演示视频里,Gemini挺像《Her》里的高级人工智能,可以与人类自如地进行交互。
在一个实例中,演示者向Gemini询问关于女儿生日派对的灵感。Gemini先是询问演示者:“可以告诉我她对什么东西感兴趣吗?”
得到足够的信息后,Gemini自行撰写了PRD(产品需求)文档,并且开始不再以文本形式回复——而是迅速写代码,帮用户定制了一个图文并茂的小组件。上面包含建议的派对主题、活动、食品建议等,让演示者在上面滑动,查看自己最感兴趣的选项。
辨认环境、物体等等场景,Gemini也不在话下。给它一张充满阳光的房间照片,Gemini还可以推理出来这个房间是朝南朝北,甚至告诉你房间里的植物应该要怎么照顾。

△ Gemini识别房间朝向
之所以能够做到更自然的交互,和Gemini的原生多模态架构密不可分。
Google解释了部分的训练细节。比如,Gemini的团队从一开始就针对不同的模态进行预训练,然后再使用额外的多模态数据对其进行微调,以进一步提升其能力。
在性能上,Gemini相当强悍。Google放出了一系列测试结果,从自然图像、音频和视频理解到数学推理,在大型语言模型 (LLM) 研发中使用的32个广泛使用的学术基准上,Gemini Ultra的性能在30项上都超过了当前最先进的模型。
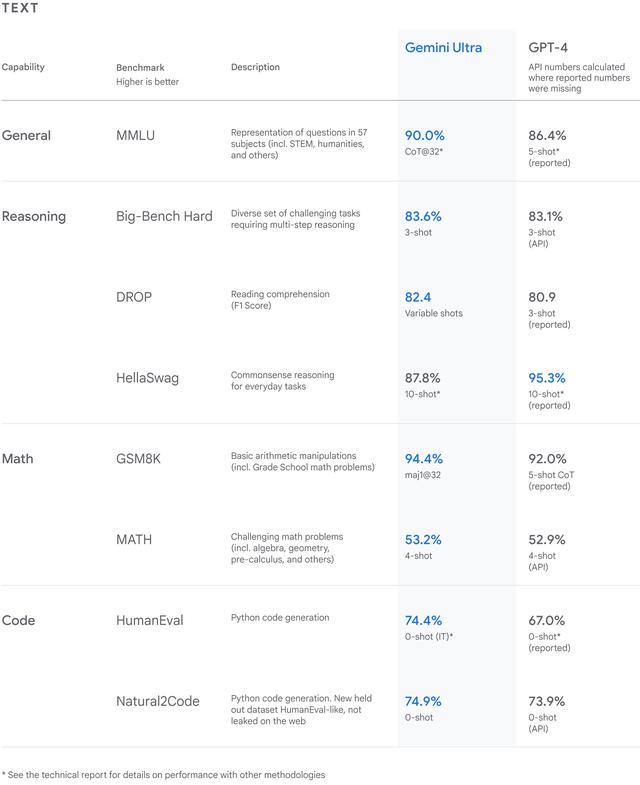
△图源:谷歌
这次发布,谷歌一口气提供了Gemini的三个尺寸模型:Ultra、Pro和Nano,分别对其进行了优化:
Ultra是性能最强的模型,适用于高度复杂的任务,在云上运作;Pro是可扩展各种任务的最佳通用模型;Nano是针对端侧设备的小模型,比如在手机、家电等各类消费设备上跑。Nano还细分了两种型号尺寸:Nano-1(18 亿参数)和 Nano-2(32.5 亿参数),分别针对低内存和高内存设备。谷歌先将Nano搬到了自家的终端上。现在,Gemini Nano已经可以跑在谷歌Pixel 8 Pro手机,Pixel 8 Pro 是为Gemini Nano设计的首款谷歌智能手机,不用联网,就可以离线调用。
Pixel 8 Pro先上了两个自带功能,一是把手机录音内容自动归纳总结;二是在WhatsApp上聊天时,谷歌键盘可以根据聊天内容,自动给出推荐回复的文字。

△键盘自动生成回复语
Gemini Pro就先被用在谷歌聊天机器Bard的升级上。谷歌称,这是Bard“自推出以来最大的升级”——在理解、总结、推理、编码和规划等方面的能力更强。Bard集成Gemini Pro之后,已经在超过170个国家和地区提供英语服务。
为了展现升级后的Bard有多强,谷歌甚至请了一个油管教育博主Mark Rober,全程使用Bard作为辅助工具,从零开始画图纸,最后真的造出了一架巨大的纸飞机!

△来源:谷歌
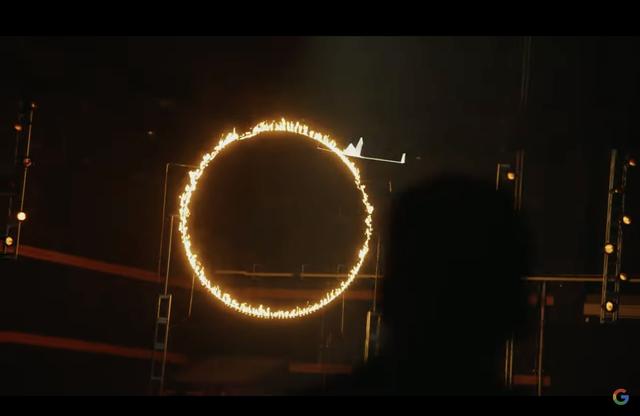
△纸飞机穿越火环,挑战成功
Google根据许多行业标准基准,对Pro版本进行了测试。结果显示,在8个基准测试中的6个里,Gemini Pro的表现优于 GPT-3.5。
不过,性能最强的Ultra还要再等等。谷歌表示,他们还要先给客户、开发者、合作伙伴以及安全和责任专家进行早期实验和反馈,预计在2024年初,Ultra版本会先向开发者和企业客户提供服务。
谷歌还给大家画了个饼。2024年初,谷歌还将计划推出Bard Advanced,会由Gemini Ultra提供支持,能够快速理解文本、图像、音频、视频等多模态输入并采取行动。看起来,和现在火热的AI Agent(智能体)初级形态就非常类似了。
AI技术上限再提高,AI竞赛仍充满变数Gemini的发布无疑是AI界又一个里程碑,这意味着AI大模型浪潮进入到一个全新阶段。
比起大语言模型,多模态模型的运作模式,才是人类最自然的和世界交互的方式:用眼睛看到东西,用耳朵听到声音,再把这个东西的语义用声音/文字输出,再做出决策。
Gemini的发布,只是掀起了多模态领域的一角。
多模态领域还在技术探索初期,技术路径还未确定。比起大语言模型,多模态模型增加了音频、视频、图片这些数据,训练难度也很大。
值得注意的是,视频内容已经是信息时代的主流,据思科的年度互联网报告——视频已经占据互联网超过80%的流量。
这些数据的训练还远未到头,意味着大模型的天花板上限还很高。如果AI领域的尺度定律(Scaling law)一直奏效,随着训练规模不断扩大,我们还有许多可以期待的能力涌现。
“长期以来,我们一直希望从人们理解世界和与世界互动的方式中汲取灵感,建立新一代 AI 模型,”Google DeepMind CEO和联合创始人Demis Hassabis表示,“今天,当我们推出Gemini时,我们离这一愿景又近了一步。”
站在现在这个时间节点,距离ChatGPT震撼世界的发布刚好过去一年。这一年里,全世界的AI公司夜以继日地奋斗,或多或少都为了回答一个问题:到底还能有谁,可以超越OpenAI?
Meta旗下的Llama试图以开源路线,集众人之力;而在和OpenAI一样的闭源路线上,谷歌是当仁不让的最强大对手。
谷歌是这轮大模型技术突破的先驱,GPT模型的核心Transformer架构正是出自谷歌之手。但在今年的AI大战中,谷歌一直被称为“起个大早赶个晚集”。
和OpenAI的对线中,谷歌的回应总慢一拍,对标ChatGPT的聊天机器人Bard匆忙上线,此前并没有获得很大的市场声量,客户拓展也很缓慢。
痛定思痛的谷歌,将AI研究原来的PaLM 2,全线切换到Gemini,并开始调遣精兵强将反击。今年8月,谷歌将谷歌大脑(Google Brain)和DeepMind两路人马合并,数百名AI精兵开始疯狂冲刺,才有了Gemini的诞生。
从如今公布的参数和使用效果来看,谷歌的“AI家底”还是不菲。Gemini发布后,谷歌算是可以扬眉吐气了。
而Gemini发布的当下,全球的AI大模型竞赛进入了新一轮竞争,战局又变得面目模糊。
虽然OpenAI占有先机,通过ChatGPT获得了大量训练数据反馈,谷歌也依然有着自己的优势。The Information此前报道,Gemini至少在一个方面比GPT-4强:除了来自网络的公共信息之外,Gemini还利用了来自旗下产品的大量Google专有数据。因此,在理解用户特定查询的意图时更准确,而且错误答案(即幻觉)也似乎更少。
不过,即使Gemini放出来的效果惊人,但现在的谷歌还不是特别有底气,Gemini的实际应用效果也有待验证。
据CNBC,Gemini发布前,谷歌还是犹豫不定,曾多次推迟发布日期,如今又因为市场压力突然决定发布。谷歌的高管们在媒体沟通会上表示,Gemini Pro的性能优于OpenAI的GPT-3.5,但回避了有关Gemini与GPT-4相比的问题。
TechCrunch更是直言:“Gemini并不是我们所期待的大模型”,表示谷歌有点吹嘘过度。虽然Gemini在30项测试中都获得了最好成绩,但实际上,很多项都是略略高于GPT-4和GPT-4 with Vision等模型而已。
作为大公司,谷歌要想继续追赶,困难还有很多。The Information表示,谷歌正在努力解决在非英语查询等任务上的困难,并且内部对Gemini的提前发布意见不一,对Gemini的盈利策略也没定下来,商业化难办。
而在OpenAI那边,因为董事会解雇CEO又回归的戏码,公司尚在艰难的“灾后重建”中,刚推出的GPT高级版无限期暂停,GPT商店更是延后到了明年。此前,OpenAI还放弃过一个重要大模型项目Arrakis的训练,侧面反映了还有不少技术难题等待解决。
如今,一些新势力也悄然冒头。比如马斯克的xAI就进展飞快,正在计划融资10亿美元,接下来一周内,还会向订阅会员上线使用权限。
在欧洲,也出现了立志再造OpenAI、“开源一切”的Kyutai,以及Mistral AI等公司,后者也同样是由来自Google、Meta、Hugging Face,曾经深度参与过Llama研发的尖端人才参与创立。
这场AI新势力的竞赛,真是越来越精彩了。
相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234328 电子证书1033 电子名片60 自媒体46877































