“智能之火,人类渴求已久的梦想,现在终于被AI点燃。”当ChatGPT问世时,全球媒体争相报道人工智能技术的日新月异。ChatGPT那流畅的语言表达,广博的知识面,强大的创作能力,让世人为之惊叹。“终于有AI通过图灵测试了!”很多人由衷地赞叹。
然而就在最近,来自加州大学圣地亚哥分校(UCSD)的研究人员对ChatGPT等新一代语言模型进行了图灵测试。结果令人震惊,现今最强AI ChatGPT,不仅没有通过测试,反而被一个60年前的老AI系统击败。这场看似AI之间的PK,其实更凸显了图灵测试本身的局限。

能过五关斩六将的ChatGPT,似乎无所不能,深谙人性,几乎达到了人类智能的高度。外界一致看好它通过图灵测试——那项被视为AI智能最终评判的考验。

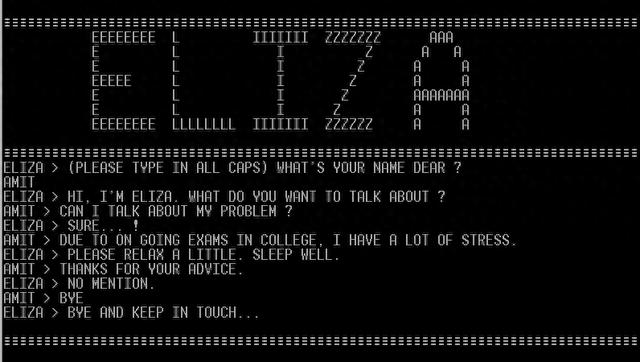
二、 60年前老AI系统ELIZA:规则AI的巅峰之作
在这场看似AI技术发展进程的大比拼中,鼎鼎大名的ChatGPT并非最终赢家。让所有参与者大跌眼镜的是,一个60年前基于规则的老AI系统ELIZA,在图灵测试中表现更胜一筹,成功骗过了27%的人类。

三、 图灵测试的局限:评判AI智能的金标准还需改进
这场看似前沿AI对决老AI的比试,突显了图灵测试本身的严重局限性。正如论文作者指出,测试结果“再次验证了一个结论:图灵测试并不是判断AI智能高低的测试”。
这里值得深究的是,测试人员判断ELIZA为人类的关键原因,居然是因为“我问它问题它都不回答,没有表现得很热情或者唠叨”。也就是说,违背常识的并不是ELIZA的能力,而是人类参试者关于什么是人工智能的先入为主观念。这种“ELIZA效应”严重影响了测试结果的客观性与有效性。

显然,任何测试都不可能在百分之百隔绝主观假设的影响,但这正是对测试方法不断优化的需要。图灵测试作为评价AI系统智能的金标准检验,必须面对自身显著的弊端,亟待提升科学性和适用范围。

目前看来,单一依赖主观人机交互结果的图灵测试,很难客观准确地Predict未来AI的进展。这场老AI反超新AI的图灵大战,正如敲响=(),提醒我们:要审视图灵测试,完善评价体系,拓宽研究视野。只有这样,才能与AI的实际发展步调一致,共同绘就美丽的未来。
相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234170 电子证书1033 电子名片60 自媒体46877































