梦晨 发自 凹非寺量子位 | 公众号 QbitAI
“取消今晚所有计划!”,许多AI开发者决定不睡了。
只因首个开源MoE大模型刚刚由Mistral AI发布。
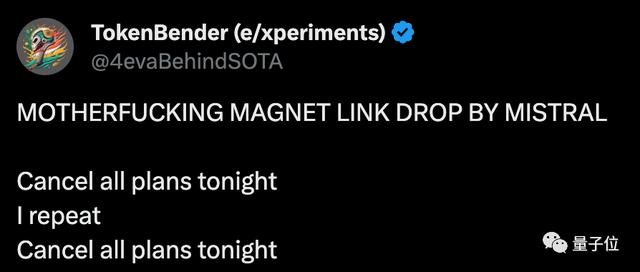
AlpacaEval上,也排到第15。
目前这个新的MoE模型连个正式名字都还没有,社区一般称呼它为Mistral-7Bx8 MoE。
但在大家期待的期待中,新MoE模型对比单体Mistral-7B的提升幅度,就应该像GPT-4对比GPT-3.5那样。
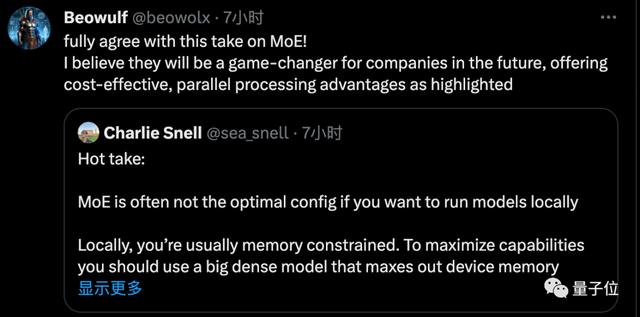
但是注意了,有人提醒大家MoE对于本地运行来说不是太友好,因为更占内存
但更适合部署在云端,跨设备专家并行,给公司处理并发需求带来成本优势。
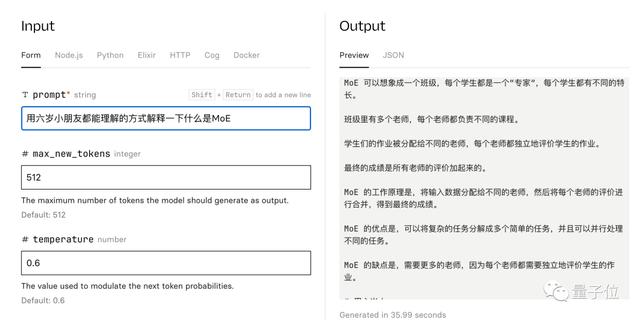
Replicate上也有了可试玩版本,简单试用发现中文水平也不错。
三位联合创始人中,CEO Arthur Mensch此前在DeepMind巴黎工作。
CTO Timothée Lacroix和首席科学家Guillaume Lample则在Meta共同参与过Llama系列的研发,Lample是通讯作者之一。
Arthur Mensch曾在接受采访时谈到,让模型变小是支持Agent发展的路径之一。
如果能把计算成本降低100倍,就能构建起更多有意思的应用。
不少人都拿来和最近谷歌的过度宣传做对比。
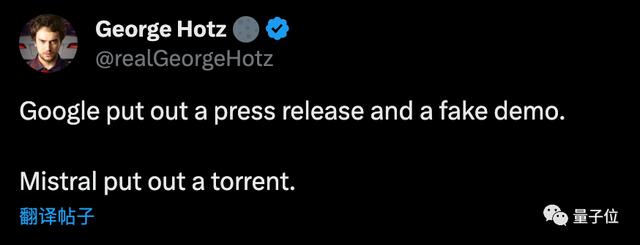
最新的梗图:磁力链接就是新的arXiv。

参考链接:[1]https://x.com/MistralAI/status/1733150512395038967?s=20[2]https://github.com/mistralai/megablocks-public[3]https://replicate.com/nateraw/mixtral-8x7b-32kseqlen
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢































