
作 者丨白杨、肖潇
编 辑丨骆一帆、王俊
图 源丨新华社
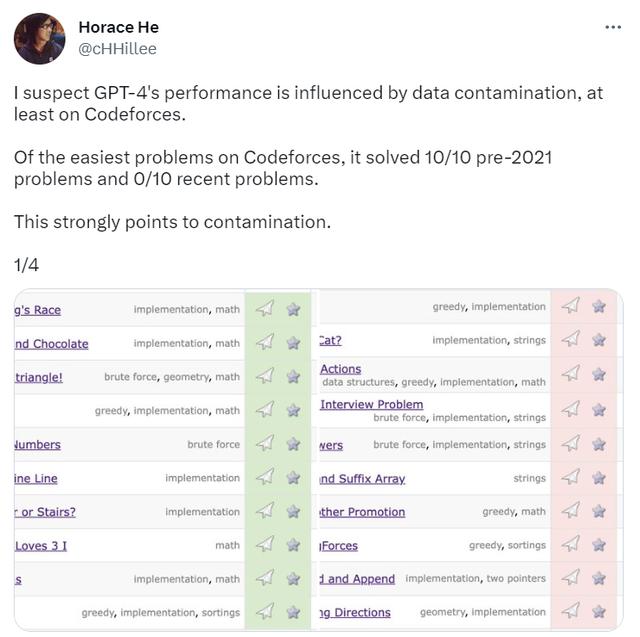
传闻中谷歌重点研发的Gemeni模型,终于正式露面。
美国时间12月6日,谷歌正式发布了Gemini大模型。谷歌CEO桑达尔·皮查伊 (Sundar Pichai) 称:“这是谷歌迄今为止功能最强大、最通用的模型。”
距离ChatGPT发布,已经过去一年零一周。伴随着ChatGPT的发布,OpenAI成为了人工智能领域最耀眼的公司,尤其是在大模型领域,它也是其他所有科技公司的追赶目标,其中包括谷歌。
过去八年,谷歌一直把AI-first作为公司战略,2016年打败人类围棋冠军的AlphaGo便是出自谷歌之手。毫不夸张地说,是谷歌掀起的一股AI浪潮,改变了整个AI行业的发展,但现在,它亟需在大模型领域证明自己。
桑达尔·皮查伊表示,Gemini的发布,是人工智能发展的一个重要里程碑,也是谷歌新时代的开始。
30项性能测试得分超过GPT-4
据悉,在Gemini 1.0版本中包含三个不同尺寸:
Gemini Ultra:谷歌参数量最大、性能最强的模型,适用于高度复杂的任务;对于功能最强悍的Gemini Ultra,谷歌称目前正在进行信任和安全检查,以及通过微调和基于人类反馈的强化学习(RLHF)进一步完善模型,预计明年初向开发人员和企业客户推出。
Gemini Pro:可扩展各种任务的模型,适用于在各种任务中扩展,谷歌便计划用Gemini Pro来升级旗下的聊天机器人Bard,以及包括搜索、广告、Chrome等在内的更多谷歌产品中。
Gemini Nano:高效的设备端任务模型。主要应用于设备端,Pixel 8 Pro将是第一款搭载Gemini Nano的智能手机;
Gemini系列模型主打多模态、灵活性两个能力。官网将Gemini定义为一款“原生多模态”(natively multimodal)模型。可以理解为,Gemini的出厂设置就是“全科发展”,多种感官在模型内统一学习,而不是单独学习再拼接到一起——后者是GPT等模型采用的标准做法,有可能带来“偏科”问题,也就是更擅长处理文字或者图片。
这就意味着Gemini可以直接理解不同类型的信息,包括文本、代码、音频、图像和视频,不需要额外的转换,各种模态的性能也更为平衡。
官网介绍,原生多模态能力让Gemeni能够“回答更复杂的问题”,“特别擅长解释数学和物理等复杂学科的推理”。
值得一提的是,在性能测试上,Gemini Ultra在32个大语言模型基准测试中的30个中超过了当前最优成绩,另外在MMLU(大规模多任务语言理解)中,Gemini Ultra的得分为90%,成为首个超越人类专家的大模型。据悉,MMLU通过结合数学、物理、历史、法律、医学和伦理学等57个科目,来测试大模型对世界知识和解决问题的能力。此前,GPT-4在该测试中的成绩为86.4%,而人类专家的成绩为89.8%。
而在MMMU基准测试中,Gemini Ultra取得了59.4%的最高得分,GPT-4V的成绩为56.8%,该项测试由跨越不同领域的多模态任务组成。
黛米斯·哈萨比斯称,在测试图像基准过程中,Gemini Ultra在没有来自图像字符识别(OCR)系统的帮助下,就超越了此前最先进的模型。这些基准测试凸显了Gemini的多模态能力,也展现出其具有更复杂推理能力的早期迹象。
目前,创建多模态模型的标准方法主要是通过训练不同模态的单独组件,然后将它们拼接在一起。但这样操作的结果是,这些模型有时在执行某些任务(如描述图像)方面表现良好,但往往难以处理更复杂的推理。
“我们将Gemini设计为原生多模态,它从一开始就针对不同模态进行了预训练,然后我们使用额外的多模态数据对其进行微调,以进一步提高其效果。”黛米斯·哈萨比斯介绍道,“这帮助Gemini从头开始就能无缝理解和推理各种输入,远远优于现有的多模态模型,而且其能力在几乎所有领域都达到了最先进的水平。”
比如在推理方面,Gemini 1.0可以理解复杂的书面和视觉信息,它通过阅读、筛选和理解信息,能够从数十万份文档中提取见解。
另外,Gemini 1.0经过训练,可以同时识别和理解文本、图像、音频等,因此它能更好地理解微妙的信息,并能回答涉及复杂主题的问题,比如进行数学和物理等复杂学科的推理。
而在编码方面,Gemini 1.0能够理解、解释和生成世界上最流行的编程语言(如Python、Java、C 和Go)的高质量代码。两年前,谷歌曾推出AI代码生成平台AlphaCode,现在在Gemini 的助力下,该平台迭代到 AlphaCode 2,性能也得到大幅提升,可以解决之前几乎两倍数量的问题。
仍在持续优化安全性
桑达尔·皮查伊表示,现在已经有数百万人正在使用谷歌产品中的生成式AI,做一年前还做不到的事情,从回答更复杂的问题到使用新工具进行协作和创造。与此同时,开发人员正在使用谷歌的模型和基础架构构建新的生成式AI应用程序,全球的初创公司和企业也正在利用谷歌的AI工具不断成长。
在其看来,这种趋势已经有些令人难以置信,但是,这还仅仅是开始。
“我们正在大胆而负责任地开展这项工作。这意味着我们的研究要有雄心壮志,追求能够为人类和社会带来巨大利益的能力,同时也要建立保障措施,并与政府和专家合作,以应对随着AI变得更加强大而产生的风险。”桑达尔·皮查伊称。
因此在Gemini的开发过程中,谷歌也加强了安全审查工作。黛米斯·哈萨比斯介绍,在谷歌的AI原则和产品安全政策基础上,谷歌团队正为Gemini的多模态能力添加新的保护措施。
不仅如此,黛米斯·哈萨比斯还强调,在开发的每个阶段,谷歌都会考虑潜在风险,并努力测试和减轻它们。
据悉,Gemini 具有到目前为止所有谷歌AI模型中最全面的安全评估,包括对偏见和有害信息的评估。同时,为了识别内部评估方法中的盲点,谷歌还在与各种外部专家和团队合作,对Gemini 模型在各种问题上进行压力测试。另外值得关注的是,Gemini的训练是基于谷歌自己的张量处理单元(TPUs)——v4 和 v5e。在这些TPUs上,Gemini比谷歌之前的模型运行速度更快、成本更低。所以除了新模型外,谷歌还宣布将推出新的TPU系统——Cloud TPU v5p,这是专为训练尖端AI模型而设计的,也将用于Gemini的开发。
有业内人士向记者表示,谷歌此次发布的Gemini虽然在很多性能上超越了GPT-4,但是它与OpenAI仍存在时间差,GPT-4发布已经半年多,新一代模型应该也在开发过程中。
“所以对谷歌而言,与GPT-4进行各种基准测试的比较,只是展现其现阶段能力的一方面,能否依靠自身积累以及强大的资源,缩短与OpenAI的时间差才是关键。”该人士指出。另外,Gemini作为谷歌在大模型时代构建的全新基础设施,比起测试数据,能否满足日常用户以及企业客户,才是检验Gemini能力的真正标准。
黛米斯·哈萨比斯表示,谷歌已经开始在搜索中试验Gemini,它使用户的搜索生成体验变得更快,在美国的英语搜索中,延迟减少了40%,同时在质量方面也有所提升。
而接下来,在加速Gemini 1.0落地应用的过程中,谷歌也在进一步扩展其未来版本的功能,包括增加上下文窗口以处理更多信息,进而提供更好的响应。
SFC
本期编辑 刘巷 实习生 赵凤铃
五月天阿信深夜发文:回应“假唱风波”!
卷入300亿惊天骗局,京东怒了!
刷屏!上海独生女继承2亿遗产,丈夫突然要离婚!经办律师独家回应
相关文章







关于作者

猜你喜欢































