梦晨 发自 凹非寺量子位 | 公众号 QbitAI
炼ChatGPT需要高质量对话数据。
在以前这可是稀缺资源,但自从有了ChatGPT,时代就变了。
加州大学圣迭戈分校(UCSD)与中山大学、MSRA合作团队提出最新方法:
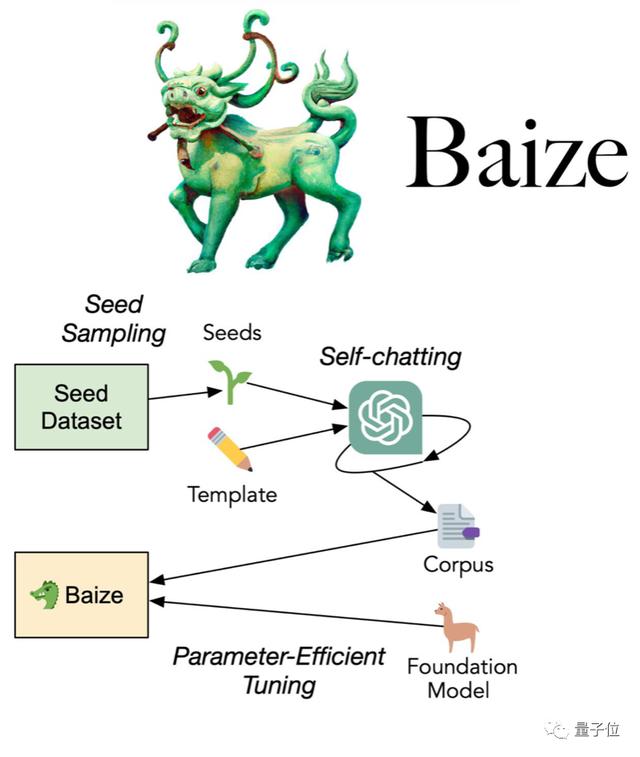
使用少量“种子问题”,让ChatGPT自己跟自己聊天,并自动收集成高质量多轮对话数据集。
团队不仅把使用此法收集的数据集开源,还进一步开发了对话模型白泽,模型权重和代码也一并开源。
(供研究/非商业用途)
 100美元搞出ChatGPT平替?
100美元搞出ChatGPT平替?具体来说,团队从美国知乎Quora,最大的编程问答社区StackOverflow等处收集到种子问题。
然后让ChatGPT自我对话,收集了11万条多轮对话,使用OpenAI的API大约花费100美元。
在此基础上使用LoRA(Low-Rank Adaption)方法微调Meta开源大模型LLaMA得到白泽。
与同样基于LLaMA的斯坦福Alpaca相比,新方法收集的数据不再仅限于单轮对话,可以达到3-4轮。

至于最后效果究竟如何,不妨就用Alpaca和ChatGPT来对比。
先来看最基本的常识问答。
常识问答坦桑尼亚的首都是哪?
这个问题出自斯坦福Alpaca的发布博客,用来说明Alpaca能力的局限性。
 生成、修改代码
生成、修改代码由于训练数据中有来自StackOverflow的5万条对话,团队也测试了白泽在多轮对话中生成代码的能力。
如何用Python把数据保存在json文件里。
对这个问题,白泽可以给出基本代码,还可在进一步对话中改写成函数形式。
不过这个结果是团队从模型的多个回答中挑选出来的。

通过上面的例子可以看出,白泽给出的回答虽然通常比ChatGPT要少一些细节,但也能满足任务要求。
对于写代码之外的自然语言任务,基本可以看成是ChatGPT的一个不那么话痨版的平替。
还可炼垂直对话模型这套自动收集对话-高效微调的流程,不仅适用于通用对话模型,还可以收集特定领域数据训练出垂直模型。
白泽团队使用MedQA数据集作为种子问题收集了4.7万条医学对话数据,训练出白泽-医疗版,同样也开源在GitHub上。
另外团队表示,中文模型也已经安排上了,敬请期待~
在线试玩:https://huggingface.co/spaces/project-baize/baize-lora-7B
GitHub仓库:https://github.com/project-baize/baize
论文地址:https://arxiv.org/abs/2304.01196
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章









关于作者

猜你喜欢
成员 网址收录40404 企业收录2983 印章生成239487 电子证书1065 电子名片60 自媒体60907































