ChatGPT 无疑是最近网络中最靓的仔,小汪哥通过这段时间的使用,加上对一些资料的查阅,了解了一些背后的原理,试图讲解一下ChatGPT应用的底层原理。如果有不正确的地方,欢迎指正。
阅读本文可能为会您解答以下问题:
为什么有的ChatGPT 收费,有的不收费?
为什么ChatGPT是一个字一个字地回答的?
为什么中文问题的答案有时候让人啼笑皆非?
为什么你问它今天是几号,它的回答是过去的某个时间?
为什么有的问题会拒绝回答?
“ChatGPT 国内版” 运行原理
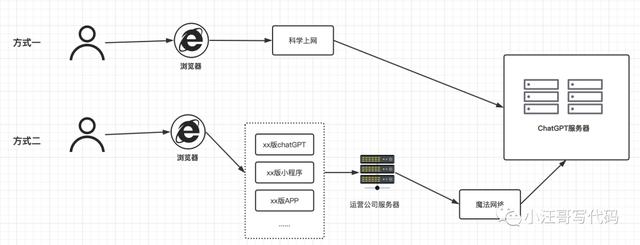
随着ChatGPT的爆火,出现了很多国内版,这种版本免费是使用次数和后续收费方式都是不同的。小汪哥画了一个草图,试着来帮忙理解。
它会礼貌地拒绝回答。与 Tay 和 Galactica 不同,ChatGPT 的训练是在源头使用审核 API 进行审核的,这允许在训练期间推迟不适当的请求。尽管如此,误报和漏报仍然会发生并导致过度节制。审核 API 是由 GPT 模型基于以下类别执行的分类模型:暴力、自残、仇恨、骚扰和性。为此,OpenAI 使用了匿名数据和合成数据(零样本),尤其是在数据不足的情况下。
最后
ChatGPT 模拟真实对话的能力非凡。即使我们知道它是一台机器,一种算法,我们也只能陷入向它提出许多问题的游戏中,以至于机器因其超大的知识而显得神圣。
但当仔细观察它时,它仍然是一个句子生成器,没有像人类那样的理解和自我批评。我更加好奇接下来会发生什么,以及他们将在这种类型的架构上取得多大的成功。
参考:
Model Index: https://beta.openai.com/docs/model-index-for-researchers
InstructGPT: https://openai.com/blog/instruction-following/
ChatGPT : https://openai.com/blog/chatgpt/
BLOOM: https://bigscience.huggingface.co/blog/bloom
Y Combinator: https://fr.wikipedia.org/wiki/Y_Combinator
相关文章








关于作者

猜你喜欢































