
图:提升模型压缩率的几种方法
视觉信息是知识的富矿:从文本走向多模态既然大语言模型发展的目标,是不断提升对有效信息的压缩率。那么自然地,如何获取尽可能多的有效信息,就成为了一个重要命题。
人类是一种拥有语言能力的视觉动物,我们大脑皮层中约有三分之一的区域是用于视觉信息解析的。因此,视觉信息是人类知识的富矿。
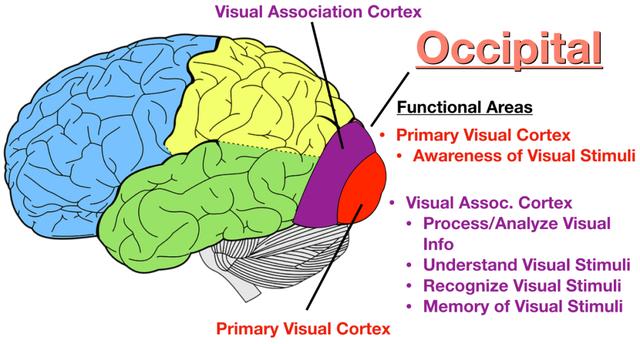
图:大脑皮层中的视觉信号中枢
举个例子,我们都知道“太阳从东边升起,西边落下”,这是一个常识。但如果分析一下我们是如何学到这个知识的,我相信绝大多数人是通过眼睛亲眼看到的,而不仅仅是通过书本学习到的。
推而广之, 视觉信息往往是人类知识的源头。由于人类具备语言和写作能力,人们会把通过视觉获取到的信息慢慢地转变为文本形态传播出来。
因此,如果把人类已获得的全部知识看作一座冰山,那么以“文本”为载体的数据只是冰山一角,而以“图像”、“视频”为载体的数据才是人类知识真正的富矿。这也是OpenAI的GPT-5会基于海量互联网视频进行学习的原因。
具体而言,如果给模型看大量的天文观测视频,模型有可能学习出一个隐式的开普勒定律;给模型看大量的带电粒子运动轨迹,模型可能会学习出洛伦兹力的数学表达;当然,我们也可以更大胆一些,如果给模型学习强子对撞机的海量实验数据,模型是否可以解开希格斯玻色子的秘密,从而解答物质的“质量”之谜,这一切都相当值得期待。
图:基本粒子模型与上帝粒子
大数据时代的数据荒:运用合成数据破局虽然人类社会早已进入了大数据时代,全球经济活动产生了大量数据资产,但是LLM所需的训练集膨胀速度更快。根据预测,到2026年文本数据将被训练完,图像数据将在2040年左右用完。
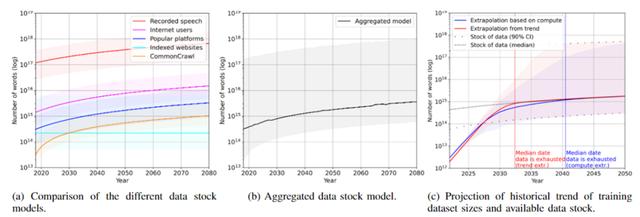
图:Gartner对合成数据发展的预测
OpenAI在GPT-4的技术文档中重点提到了合成数据的应用,可见OpenAI对该领域的重视。

图:GPT-4技术报告中对合成数据应用的探讨
更进一步来看,如果合成数据的质量能够全面超越人类标注的质量,那么未来AGI便可以 自我迭代,进化的速度会大幅提升。到这时,人类可能就成为AGI的启动脚本(Boot Loader)了。
这不禁让我联想到马斯克曾在2014年做出的预言。他认为从“物种进化的尺度”来看, 以人类为代表的“碳基生命”可能只是以“AI”为代表的“硅基生命”的启动脚本。
这个预言令人毛骨悚然。放在14年那会儿,绝大部分人会认为这是危言耸听。但是当下我们再回头审视这个判断,不难发现这与“合成数据”的发展目标不谋而合。
合成数据领域的突破,可能成为AGI跨过奇点的重要里程碑,让我们拭目以待。

图:Musk在14年对AI发展的判断
AGI对人类社会经济活动影响:展望与思考在刚结束的GTC大会上,NVIDIA的CEO黄仁勋将ChatGPT的诞生类比为移动互联网的iPhone时刻。但从人类科技发展史的尺度来看,我认为 ChatGPT的诞生更像是拉开了“第四次工业革命”的序幕,会带来社会生产力和生产关系的质变。
虽然有点不恰当,但如果把人类看作一台“生物化学计算机”,我们不妨比较一下人类与AGI的效率异同:
首先,从 “通信效率”的角度来看,人类之间的数据传输主要依靠交流,而交流的本质是以空气为媒介的机械波。与此相对,AGI之间的数据传输则主要通过GPU之间的NVLink,数据传输的带宽显著提升。
其次,从 “工作效率”的角度来看,人类受限于生物体内复杂的免疫机制、神经元修复机制等原理,需要保持充足的睡眠,才可以换取白天良好的工作状态。但是AGI只需要有充足的能源供给,便可以做到7*24的高强度作业,工作效率显著提升。
再次,从 “协作效率”的角度来看,由100个人组成的团队整体的工作效率往往会低于10人小组产出总量的10倍。随着组织人员规模的增加,人均产出不可避免的下降,需要通过“富有经验的管理艺术”才能激发团队协作的活力。相反,对于AGI来说,增加运算节点便可以扩大产能,并不会出现边际效用递减的管理与协作难题。
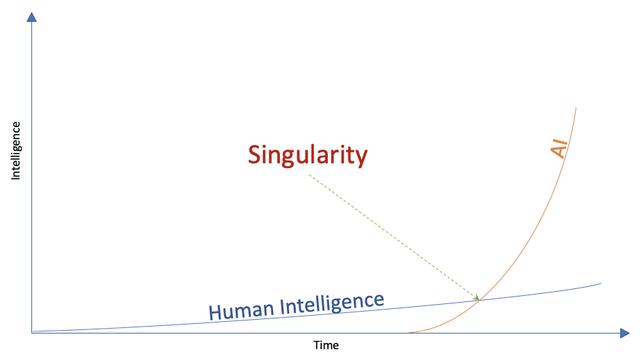
图:人工智能与人类智能的发展曲线
以上分析了相比于人类而言,AGI的生产力优势。但是人类在以下几个重点方面依然具备着不可替代的价值:
首先,虽然AGI在知识的广度上会远超人类,但是在具体领域的知识深度上,人类目前依然占据优势。
以金融投资为例,一位资深的投资经理可以根据不完整的市场信息做出模糊推断,从而获得超额收益;以科学研究为例,一位优秀的科学家可以从看似无关紧要的实验误差中推断出全新的理论体系。这些都是当前AGI难以企及的。
其次,社会经济活动的运转,高度依赖于人与人之间的“信任”,这种信任是AGI难以取代的。比如当你去医院看病的时候,即使AGI能够根据你的症状描述做出相当准确的诊断,你依然大概率会拿着诊断结果去咨询边上的人类医生,寻求一个值得信任的诊疗建议。类似的“信任机制”构成了医疗、教育、金融等领域中经济活动的重要基石。
随着AGI的发展,许多经济活动的游戏规则会悄然发生改变,而这个规则改变的契机,则会以AGI在该领域超过人类中的最强者作为分界线,正如AlphaGo的诞生彻底改变了围棋界的规则一样。
结语这是最好的时代,也是最坏的时代。悲观者可能永远正确,但确实毫无意义。
纵观历史,人类科技史的发展并不是连续的,而是跳跃的。或许我们正在经历的正是一次人类科技水平的跳跃,无论如何,能够亲眼见证并参与其中,我们都是幸运的。
最后,分享一句我特别喜欢的话,这是OpenAI的CEO Sam Altman在30岁生日时给自己的人生建议:
The days are long but the decades are short.
参考文献
[1] Power, Alethea, et al. "Grokking: Generalization beyond overfitting on small algorithmic datasets." arXiv preprint arXiv:2201.02177 (2022).
[2] Bubeck, Sébastien, et al. "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023).
[3] Eloundou, Tyna, et al. "Gpts are gpts: An early look at the labor market impact potential of large language models." arXiv preprint arXiv:2303.10130 (2023).
[4] Wu, Shijie, et al. "BloombergGPT: A Large Language Model for Finance." arXiv preprint arXiv:2303.17564 (2023).
[5] Liang, Percy, et al. "Holistic evaluation of language models." arXiv preprint arXiv:2211.09110 (2022).
[6] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[7] Kaplan, Jared, et al. "Scaling laws for neural language models." arXiv preprint arXiv:2001.08361 (2020).
[8] Zhou, Yongchao, et al. "Large language models are human-level prompt engineers." arXiv preprint arXiv:2211.01910 (2022).
[9] Wei, Jason, et al. "Emergent abilities of large language models." arXiv preprint arXiv:2206.07682 (2022).
[10] Zellers, Rowan, et al. "HellaSwag: Can a machine really finish your sentence?." arXiv preprint arXiv:1905.07830 (2019).
[11] Barocas, Solon, Moritz Hardt, and Arvind Narayanan. "Fairness in machine learning." Nips tutorial 1 (2017): 2017.
[12] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[13] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
本文来自微信公众号“熵简科技Value Simplex”(ID:Shangjian-Tech),作者:熵简CEO|费斌杰,36氪经授权发布。
相关文章







关于作者

猜你喜欢































