《科创板日报》3月8日讯在接连推出AI聊天机器人Bard、发布通用语音模型(USM)API与研究成果之后,谷歌再度推出一个新AI模型。
当地时间3月7日,谷歌与柏林工业大学团队发布PaLM-E,这也是史上最大的“通才”AI模型,最终参数量高达5620亿,是GPT-3参数量(1750亿)的3倍有余。
PaLM-E是PaLM-540B语言模型与ViT-22B视觉Transformer模型的结合体。它主要基于谷歌现有的PaLM大语言模型,并添加了感官信息和机器人控制。
这是人机互动领域的一项重大飞跃——PaLM-E会将图像信息、传感器数据等编码为一系列与语言标记大小相同的向量,从而以与处理语言相同的方式“理解”感官信息。换言之,PaLM-E证明了,在视觉、文本等多模态输入下,大型语言模型也可作出具体决策,并执行复杂任务。
谷歌指出,其具备多模态思维链推理(允许模型分析包括语言和视觉信息的一系列输入)、只接受单图像提示训练的多图像推理(使用多个图像作为输入来做出推理或预测)等多种涌现能力。
▌强在何处?
PaLM-E作为视觉语言模型,识别图片内容并给出相关信息自然不在话下。此外,它还可以:
(一)针对带有手写数字的图像,执行数学运算。例如,根据下图中手写的餐馆菜单,PaLM-E可直接算出2份披萨的价钱。
 图|机器人抓取米饼过程
图|机器人抓取米饼过程而这一系列操作的强大之处在于,上述过程中,PaLM-E无需预先处理的场景,因此也不用人类对相关数据进行预处理或注释,并可实现更为自主的机器人控制。
更重要的是,PaLM-E生成的行动计划还具有“弹性”,即可对周围环境变化作出相应反应。在谷歌给出的视频中,研究人员从机器人的机械手中拿走了米饼并放在另一处,而机器人重新找到并抓取了那一袋薯片。
(三)得益于PaLM-E的大型语言模型核心,其还表现出了“正迁移”能力,即可以将一项任务中学到的知识和技能迁移到另一项任务中,从而与单任务机器人模型相比具有“显着更高的性能”。
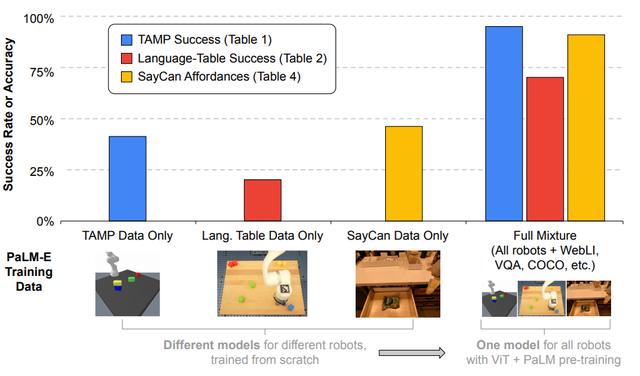
谷歌研究人员计划探索PaLM-E在现实世界场景中的更多应用,例如家庭自动化或工业机器人。他们希望PaLM-E能够激发更多关于多模态推理和具身AI的研究。
 图|PaLM-E应用示意
图|PaLM-E应用示意值得注意的是,灾难性遗忘常常是预学习模型必须面对的一大挑战,即当一个训练好的模型被进一步训练时,现有任务性能便将显著下降。
谷歌本次给出的研究结果表明,一方面,冻结语言模型是通向完全保留其语言能力的通用具身多模态模型的可行之路;同时,扩大语言模型的规模也可显著减少灾难性遗忘。
相关文章




关于作者

猜你喜欢
成员 网址收录40405 企业收录2984 印章生成241717 电子证书1079 电子名片61 自媒体64547































