机器之心报道
机器之心编辑部
在 NLP 领域,pretrain-finetune 和 prompt-tuning 技术能够提升 GPT-3 等大模型在各类任务上的性能,但这类大模型在零样本学习任务中的表现依然不突出。为了进一步挖掘零样本场景下的模型性能,谷歌 Quoc Le 等研究者训练了一个参数量为 1370 亿的自回归语言模型 Base LM,并在其中采用了全新的指令调整(instruction tuning)技术,结果显示,采用指令调整技术后的模型在自然语言推理、阅读理解和开放域问答等未见过的任务上的零样本性能超越了 GPT-3 的小样本性能。
大规模语言模型(LM)已经被证明可以很好的应用到小样本学习任务。例如 OpenAI 提出的 GPT-3 ,参数量达 1,750 亿,不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力等。在不进行微调的情况下,可以在多个 NLP 基准上达到最先进的性能。
然而,像 GPT-3 这样的大规模语言模型在零样本(zero-shot)学习任务中表现不是很突出。例如,GPT-3 在执行阅读理解、问答和自然语言推理等任务时,零样本的性能要比小样本(few-shot)性能差很多。
本文中,Quoc Le 等来自谷歌的研究者探索了一种简单的方法来提高大型语言模型在零样本情况下的性能,从而扩大受众范围。他们认为 NLP 任务可以通过自然语言指令来描述,例如「这部影评的情绪是正面的还是负面的?」或者「把『how are you』译成汉语」。
该研究采用具有 137B 参数的预训练模型并执行指令调整任务,对 60 多个通过自然语言指令表达的 NLP 任务进行调整。他们将这个结果模型称为 Finetuned LANguage Net,或 FLAN。
 论文地址:https://arxiv.org/pdf/2109.01652.pdfGitHub 地址:https://github.com/google-research/flan.
论文地址:https://arxiv.org/pdf/2109.01652.pdfGitHub 地址:https://github.com/google-research/flan.为了评估 FLAN 在未知任务上的零样本性能,该研究根据 NLP 任务的任务类型将其分为多个集群,并对每个集群进行评估,同时在其他集群上对 FLAN 进行指令调整。如下图 1 所示,为了评估 FLAN 执行自然语言推理的能力,该研究在一系列其他 NLP 任务(如常识推理、翻译和情感分析)上对模型进行指令调整。由于此设置确保 FLAN 在指令调整中未见自然语言推理任务,因此可以评估其执行零样本自然语言推理的能力。

FLAN:用指令调整改进零样本学习
指令调整的动机是提高语言模型响应 NLP 指令的能力,旨在通过使用监督来教 LM 执行以指令描述的任务。语言模型将学会遵循指令,即使对于未见过的任务也能执行。为了评估模型在未见过的任务上的性能,该研究按照任务类型将任务分成多个集群,当其他集群进行指令调整时,留出一个任务集群进行评估。
任务和模板
该研究将 62 个在 Tensorflow 数据集上公开可用的文本数据集(包括语言理解和语言生成任务)聚合到一起。下图 3 显示了该研究使用的所有数据集;每个数据集被归类为十二个任务集群之一,每个集群中的数据集有着相同的任务类型。

训练细节
模型架构和预训练。在实验中,该研究使用密集的从左到右、仅解码器、137B 参数的 transformer 语言模型。该模型在一组网络文档(包括含计算机代码的文档)、对话数据和 Wikipedia 上进行预训练,这些文档使用 SentencePiece 库 (Kudo & Richardson, 2018),被 tokenize 为 2.81T BPE token 和 32K token 的词表。大约 10% 的预训练数据是非英语的。这个数据集不像 GPT-3 训练集那么干净,而且还混合了对话和代码。
实验结果
研究者分别在自然语言推理、阅读理解、开放域问答、常识推理、共指消解和翻译等多项任务上对 FLAN 的性能进行了评估。对于每一项任务,他们报告了在所有模板上性能的平均和标准误差,这代表了给定典型自然语言指令时 FLAN 的预期性能。
自然语言推理任务
下表 1 展示了不同模型自然语言推理测试的结果,其中给定一个前提与假设——模型必须确认在给定前提为真的情况下假设也为真。可以看到,FLAN 在所有情况下均表现出强大的性能。
尽管在 CB 和 RTE 的不同模板的结果中存在高方差,但 FLAN 在没有任何 prompt 工程时依然在四个数据集上显著优于零样本和小样本 GPT-3。在具有最佳 dev 模板时,FLAN 在五个数据集上优于小样本 GPT-3。FLAN 甚至在 ANLI-R3 数据集上超越了监督式 BERT。

阅读理解和开放域问答任务
在阅读理解任务上,模型被要求回答关于给定文章段落的问题,结果如下表 2 所示。FLAN 在 BoolQ 和 OBQA 数据集上显著优于 GPT-3。在使用最佳 dev 模板时,FLAN 在 MultiRC 数据集上略优于小样本 GPT-3。
对于开放域问答任务,FLAN 在 ARC-easy 和 ARC-challenge 数据集上显著优于零样本和小样本 GPT-3。在 Natural Questions 数据集上,FLAN 优于零样本 GPT-3,弱于小样本 GPT-3。

翻译
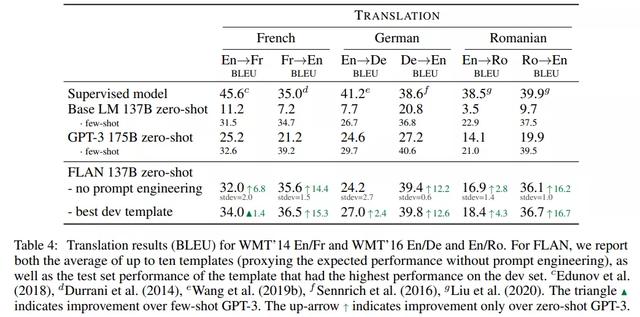
研究者还在 GPT-3 论文中评估的三个数据集上测试了 FLAN 的机器翻译性能,这三个数据集分别是 WMT’14 法语 - 英语以及 WMT’16 的德语 - 英语和罗马尼亚语 - 英语。
测试结果如下表 4 所示,Base LM 的零样本翻译性能弱,但小样本翻译结果媲美 GPT-3。FLAN 在六个评估指标中的五个上优于小样本 Base LM。与 GPT-3 类似,FLAN 在翻译成英语任务上展示出了强大的性能,并且与监督式翻译基线相比具有优势。
其他实验
由于该论文的核心问题是指令调整如何提高模型在未见过任务上的零样本性能,因此该研究的第一个消融实验研究了指令调整中使用的集群和任务数量对性能的影响。
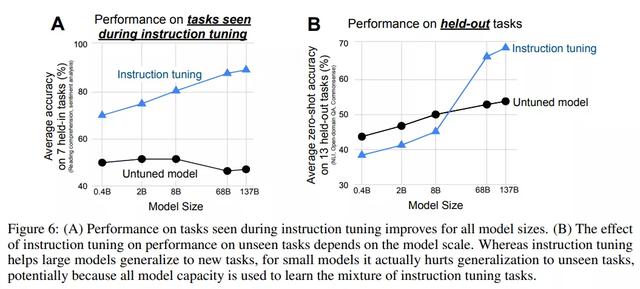
图 5 显示了实验结果。与预期一致,研究者观察到 3 个 held-out 集群的平均性能随着向指令调整添加额外的集群和任务而提高(情感分析集群除外),证实了所提指令调整方法有助于在新任务上提升零样本性能。

下图 6 结果表明,对于较大规模的模型,指令调整填充了一些模型容量,但也教会了这些模型遵循指令的能力,允许模型将剩余的容量泛化到新任务。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成241049 电子证书1067 电子名片60 自媒体64547































