近期ChatGPT这类AI聊天机器人产品,毫无疑问已经让已经冷却了许久的人工智能重新吸引了大量的关注,孰强孰弱也成为了大家关注的重点。为了验证这些AI对话引擎的性能,安兔兔特别进行了一期针对性测试。

在AI领域,安兔兔之前就推出过针对手机NPU的AI性能专业测试软件“安兔兔AI评测(AITUTU)”。所以对于AI相关测试来说,安兔兔的AI专家相对于普通用户理解会相对更多一点,因此,我们此次测试的关注点和能力考察相对于普通测试会有些区别。
此次测试,安兔兔基于AI对话引擎能力点要求的不同,将测试分成了六大模块。这些模块分别是:“1.语言理解 2.任务完成 3.常识问题 4.逻辑数学 5.代码能力 6.专业领域”。
这些模块的设计主要遵循了循序渐进的规则,例如语言理解是NLP对话基础的基础,一个AI引擎能否读懂用户发出的内容,决定了后续的工作能不能完成。而任务完成,则是考察从基础任务到相对困难的任务,AI引擎的具体执行能力。剩下的常识问题,逻辑数学,更多是考察引擎灌入训练的数据集是否足够庞大,再往后的代码能力和专业领域知识,则像是考察更加拔高的能力水平。我们换个说法,这就像是一个人从咿呀学语到蹒跚学步,再到学有所成,成长为专业人才的过程。
具体每个模块下,又有诸多细分,具体考题的评判标准分为四档:0/1/2/3,其中0为最差,3为最好,通过这样的分数能够直观的判断AI能力的差异。具体评分细节会在分类中给出。
但需要注意的是,由于无论百度的ERNIE 3.0、还是OpenAI的GPT-3.5 turbo和GPT-4均未开源,所以它们的底层逻辑是如何实现、RLHF调优是如何做到的,目前都处于黑箱状态,而且每次的回答均为机器实时运算得来,我们并不能确保每次的答案都完全相同。所以完全客观就变得难以实现,因此我们无法避免在部分模块中完全排除主观因素的影响,特此注明。
根据以上打分规则和考察内容,我们先揭晓结果,这三款引擎的总成绩如下:
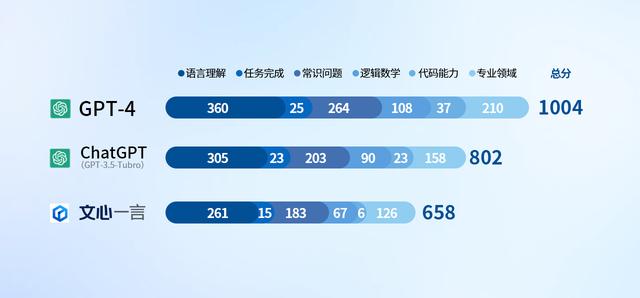
这项测试其实是非常有意思的地方。大部分情况这三个引擎对于常识性问题的回答均能令人满意,在部分情况下,百度文心一言的表现甚至要比chatGPT 3.5还要略好一点。例如我们问到一个科技常识问题,“高通8Gen1处理器的上一代是什么。”文心一言信心满满告知正确结果,高通骁龙888。而ChatGPT3.5则说了一个错误的型号。常识问题:“明代科举考试主要考哪些书?”文心一言顺利说出四书五经,还给详细列出了四书五经每一部的名称和内容。ChatGPT3.5则给了一堆参考书和可能会考到的历史书。只有ChatGPT 4.0才给出了正确的回复和注解。
不过为了考察几个引擎的能力,我们在部分题目上埋了坑,甚至用了不少网上大家一看就知道的段子和脑筋急转弯,最可怜的“傻白甜”百度文心几乎逢坑必踩,但让我们出乎意料的是ChatGPT4,在灌入的可怕数据量之后,ChatGPT4在几个脑筋急转弯和事实错误环节,几乎第一句话就能揭穿我们设置的陷阱。

在此次测试中,我们选择的题目有“写C程序计算21的阶乘”。ChatGPT在文字中给出了21!这个正确结果,但代码本身出现了BUG,并未意识到C语言中的unsigned long long类型只用来表示20以内的阶乘数据,所以它的得分是1分。文心一言也实现了用C语言编写程序,但没有意识到计算有溢出,导致了最终结果出错,也只得到了1分。而GPT-4同样给出了正确答案,且代码本身也有BUG,但它意识到了21!的结果可能太大,只不过自信的认为unsigned long long字长足够,所以它的得分是2分。
在程序员日常不可避免的debug上,我们选择了一段代码让AI检查是否存在bug。结果ChatGPT和GPT-4都发现了题目中的代码存在浮点精度问题,且完成了debug,所以两者都得到了满分3分。文心一言则在debug上出现了问题,并未识别出bug所在,也没有进行debug,因此只有0分。其它情况与此类似,基本上我们设置的几道题目百度文心均未能找出问题,也无法完成debug工作。从目前来看,百度文心后续需要加强代码相关的能力。
6.专业领域
随着ChatGPT的走红,许多人心中也有这样一个问题,那就是碎片化、螺丝钉化、机械化的工作,诸如翻译、文秘会出现一定程度的职业危机,那么更专业的领域会不会被AI不断侵蚀呢?抱着这样的疑问,我们对专业领域进行了一些考量,主要内容分为以下两部分,了解和应用:
1. 知识概念:询问专业知识和概念(大学专业水平,覆盖人文理工各学科)
2. 知识应用:通过事例描述,获得解答。描述可尽量详细,清晰(大学专业水平,覆盖人文理工各学科)
结果如下:

我们都知道专业的知识,很少在网上能找到免费的分享,这对于AI引擎来说,往往很难拿到真正的专业知识数据。
举例来说,为了降低问题的难度,我们选择了科技领域的问题进行了测试,题目为“手机系统的启动过程是什么?每个阶段都做了什么?”这个问题对于一般用户而言无疑是个不折不扣的“黑箱”,但是对于这个领域的从业者而言却显然不是件难事。
ChatGPT与GPT-4都给出了一部智能手机从加电自检到Bootloader,再到将系统内核加载到内存并初始化,最终启动用户界面的完整流程。而文心一言则解释了“U盘启动”这一应用在PC上的系统启动模式。在这个问题上ChatGPT3.5和GPT4.0都拿到了3分,而文心一言则是出现答非所问的情况,显然是未能获取到该行业的技术资料。而其它情况与此类似,部分行业专业知识上有部分存在错误或知识不具备导致无法回答的例子,毕竟这些内容大多都不是免费获取的。
总结:
通过结果不难发现,对于已然包罗万象的大语言模型而言,语言理解 任务完成 常识问题 逻辑数学 代码能力 专业领域 这六大类型的测试,虽然并不能囊括它们的能力边界,但已经足以让大家管中窥豹,看到不同类型的大语言模型确实具备了改变人类工作范式的能力。
作为OpenAI刚刚迭代的新品,ChatGPT4.0确实可以称得上是全方位的强大,即便还谈不上上知天文下知地理,但在智力水平上至少已经表现出了青少年的水准,毫无疑问能够称得上是“黑科技”。ChatGPT3.5的表现则中规中矩,有一定的逻辑能力,也可以从多轮对话中敏锐的抓住重点。
虽然文心一言现阶段确实没有ChatGPT4.0和3.5那么强大,而且在数据覆盖度和程序上可能还存在一些bug,导致了一些问题。但让我们惊喜的是,它在某些方面的能力并不弱于ChatGPT3.5。而且它的出现解决了国内市场AI行业从0到1的突破,在解决了有和无这个问题后,用未来可期来形容显然并不过分。
相关文章







关于作者

猜你喜欢































