关注并星标
从此不迷路
计算机视觉研究院

对于普通研究者来说,这是一种切实可行的廉价微调方式,不过需要的运算量仍然较大(作者表示他们在 8 个 80GB A100 上微调了 3 个小时)。而且,Alpaca 的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
为了进一步降低微调成本,另一位来自斯坦福的研究者 ——Eric J. Wang 使用 LoRA(low-rank adaptation)技术复现了 Alpaca 的结果。具体来说,Eric J. Wang 使用一块 RTX 4090 显卡,只用 5 个小时就训练了一个和 Alpaca 水平相当的模型,将这类模型对算力的需求降到了消费级。而且,该模型可以在树莓派上运行(用于研究)。
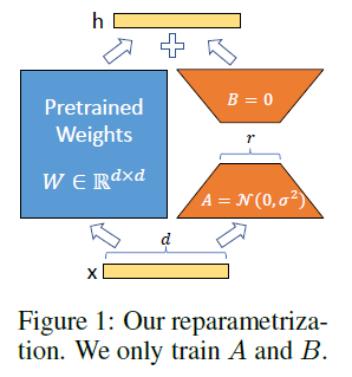
LoRA 的技术原理。LoRA 的思想是在原始 PLM 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵(引自:https://finisky.github.io/lora/)。LoRA 的最大优势是速度更快,使用的内存更少,因此可以在消费级硬件上运行。

下面是效果展示:

图源:https://twitter.com/nash_su/status/1639273900222586882
以下是训练过程和结果:
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
计算机视觉研究院
公众号ID|ComputerVisionGzq
相关文章







关于作者

猜你喜欢
成员 网址收录40402 企业收录2983 印章生成238541 电子证书1060 电子名片60 自媒体57329































