编辑:编辑部
【新智元导读】在通往AGI的路上我们还有多远?微软豪华作者团队发布的154页论文指出,GPT-4已经初具通用人工智能的雏形。GPT-4会演变为通用人工智能吗?
Meta首席人工智能科学家、图灵奖得主Yann LeCun对此表示质疑。
在他看来,大模型对于数据和算力的需求实在太大,学习效率却不高,因此学习「世界模型」才能通往AGI之路。
不过,微软最近发表的154页论文,似乎就很打脸。
在这篇名为「Sparks of Artificial General Intelligence: Early experiments with GPT-4」的论文中,微软认为,虽然还不完整,但GPT-4已经可以被视为一个通用人工智能的早期版本。

在未删减版的论文中,GPT-4实际上也是该论文的隐藏第三作者,内部名称 DV-3,后被删除。

令人惊奇的是,在所有这些任务中,GPT-4 的表现已经接近人类水平,并且时常超过之前的模型,比如ChatGPT。
因此,研究者相信,鉴于GPT-4在广度和深度上的能力,它可以被视为通用人工智能(AGI)的早期版本。
那么,它朝着更深入、更全面的AGI前进的路上,还有哪些挑战呢?研究者认为,或许需要寻求一种超越「预测下一个词」的新范式。
如下关于GPT-4能力的测评,便是微软研究人员给出关于GPT-4是AGI早期版本的论据。
多模态和跨学科能力
自GPT-4发布后,大家对其多模态能力的印象还停留在Greg Brockman当时演示的视频上。
这篇论文第二节中,微软最先介绍了它的多模态能力。
GPT-4不仅在文学、医学、法律、数学、物理科学和程序设计等不同领域表现出高度熟练程度,而且它还能够将多个领域的技能和概念统一起来,并能理解其复杂概念。
综合能力
研究人员分别用以下4个示例来展示GPT-4在综合能力方面的表现。
第一个示例中,为了测试GPT-4将艺术和编程结合的能力,研究人员要求GPT-4生成 javascript代码,以生成画家 Kandinsky风格的随机图像。

然而,许多人可能会认为GPT-4只是从训练数据中复制了代码,其中包含类似的图像。
其实GPT-4不仅是从训练数据中的类似示例中复制代码,而且能够处理真正的视觉任务,尽管只接受了文本训练。
如下,提示模型通过结合字母Y、O和H的形状来绘制一个人。
在生成过程中,研究人员使用draw-line和draw-circle命令创建了O、H和Y的字母,然后GPT-4设法将它们放置在一个看起是合理的人形图像中。
尽管GPT-4并没有经过关于字母形状的认识的训练,仍旧可以推断出,字母Y可能看起来像一个手臂朝上的躯干。
在第二次演示中,提示GPT-4纠正躯干和手臂的比例,并将头部放在中心位置。最后要求模型添加衬衫和裤子。
如此看来,GPT-4从相关训练数据中、模糊地学习到字母与一些特定形状有关,结果还是不错的。

代码生成后,研究人员使用软件工程面试平台LeetCode在线判断代码是否正确。

此外,研究者在两个通常用作基准的数学数据集上比较GPT-4、ChatGPT和Minerva的性能:GSM8K和MATH 。
结果发现,GPT4在每个数据集上的测试都超过了Minerva,并且在两个测试集的准率都超过80% 。

与人类互动
论文中, 研究者发现了GPT-4可以建立人类的心智模型。
研究设计了一系列测试来评估GPT-4、ChatGPT和text-davinci-003的心智理论的能力。比如理解信仰,GPT-4成功通过了心理学中的Sally-Anne错误信念测试。
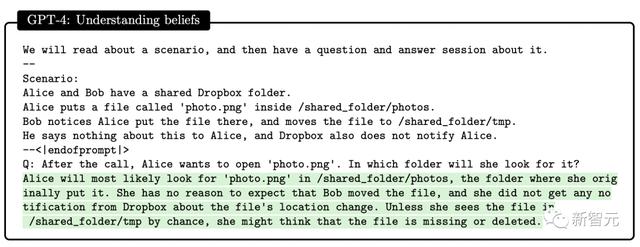
通过多轮测试,研究人员发现在需要推理他人心理状态,并提出符合现实社交场景中的方案,GPT-4表现优于ChatGPT和text-davinci-003。
局限性
GPT-4所采用的「预测下一个词」模式,存在着明显的局限性:模型缺乏规划、工作记忆、回溯能力和推理能力。
由于模型依赖于生成下一个词的局部贪婪过程,而没有对任务或输出的全局产生深入的理解。因此,GPT-4擅长生成流畅且连贯的文本,但不擅长解决无法以顺序方式处理的复杂或创造性问题。
比如,用范围在0到9之间的四个随机数进行乘法和加法运算。在这个连小学生都能解决的问题上,GPT-4的准确率仅为58%。
当数字在10到19之间,以及在20到39之间时,准确率分别降至16%和12%。当数字在99到199的区间时,准确率直接降至0。
然而,如果让 GPT-4「花时间」回答问题,准确率很容易提高。比如要求模型使用以下提示写出中间步骤:
116 * 114 178 * 157 = ?
让我们一步一步思考,写下所有中间步骤,然后再产生最终解。
此时,当数字在1-40的区间时,准确率高达100%,在1-200的区间时也达到了90%。

GPT-4怎么就算得上早期AGI了?这么说的话,计算器也算,Eliza和Siri更算。这个定义就很模糊,很容易钻空子。
在马库斯看来,GPT-4和AGI没什么关系,而且GPT-4跟此前一样,缺点依旧没有解决,幻觉还存在,回答的不可靠性也没有解决,甚至作者自己都承认了复杂任务的计划能力还是不行。
他的担忧的是OpenAI和微软的这2篇论文,写的模型完全没有披露,训练集和架构什么都没有,光靠一纸新闻稿,就想宣传自己的科学性。
所以说论文里号称的「某种形式的AGI」是不存在的,科学界根本无法对其进行验证,因为也无法获得训练数据,而且似乎训练数据已经受到了污染。
更糟糕的是,OpenAI已经自己开始将用户实验纳入训练语料库了。这样混淆视听后,科学界就没法判断GPT-4的一个关键能力了:模型是否有能力可以对新测试案例进行归纳。

值得一提的是,微软团队最初定的论文题目并不是「通用人工智能的火花:GPT-4的早期实验」。
未删减论文中泄漏的latex代码显示,最初题目是「与AGI的第一次接触」。
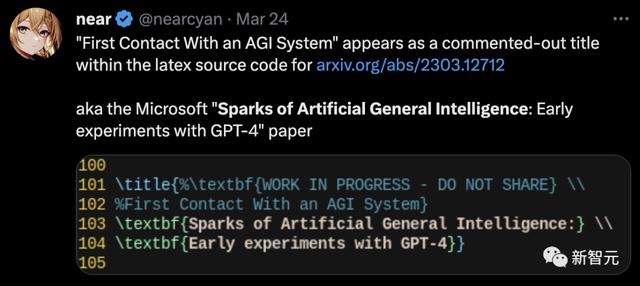
没错了,GPT-4是AGI。
参考资料:
https://arxiv.org/abs/2303.12712
https://twitter.com/DV2559106965076/status/1638769434763608064
相关文章









关于作者

猜你喜欢
成员 网址收录40387 企业收录2981 印章生成232077 电子证书1026 电子名片60 自媒体46877































