Is Chatgpt the Ultimate Programming Assistant - How far is it?
HAOYE TIAN, University of Luxembourg
WEIQI LU, The Hong Kong University of Science and Technology
TSZ-ON LI, The Hong Kong University of Science and Technology
XUNZHU TANG, University of Luxembourg
SHING-CHI CHEUNG∗, The Hong Kong University of Science and Technology
JACQUES KLEIN, University of Luxembourg
TEGAWENDÉ F. BISSYANDÉ, University of Luxembourg
引用
Tian H, Lu W, Li T O, et al. Is ChatGPT the ultimate programming assistant--how far is it?[J]. arXiv preprint arXiv:2304.11938, 2023..
论文:https://arxiv.org/abs/2304.11938
摘要
最近,ChatGPT LLM备受关注:它可作为讨论源代码的机器人,提出更改建议、代码描述甚至生成代码。典型演示通常集中在现有基准上,可能已用于模型训练(即数据泄漏)。为评估LLM作为程序员有用助手机器人的可行性,我们需评估其对未见问题的实际能力及各种任务的能力。本文展示了ChatGPT作为完全自动编程助手的潜力的实证研究,侧重于代码生成、程序修复和代码摘要三个任务。研究探究了ChatGPT在常见编程问题上的表现,并将其与两个基准上的最新方法进行了比较。我们的研究显示ChatGPT在处理常见编程问题时有效。然而,实验也揭示了其注意力持续时间方面的限制:详细描述将限制ChatGPT的焦点,阻止其利用广泛知识解决实际问题。令人惊讶的是,我们发现了ChatGPT推理代码原始意图的能力。我们期待未来工作能基于此洞察力解决Oracle问题的开放性问题。我们的发现为LLM的编程辅助开发提供了有趣见解,尤其是通过展示提示工程的重要性,提供了ChatGPT在软件工程中的实际应用的更好理解。
1 引言
人工智能(AI)在自动化执行软件工程任务方面具有巨大潜力,包括代码生成、程序修复和代码摘要。AI模型能够根据自然语言描述或代码输入自动生成程序,减少手动调试工作量,提高软件的可靠性和安全性。此外,AI还能生成自然语言描述,帮助理解、维护和重用代码。
大规模语言模型(LLMs)在软件工程中引起了广泛关注,它们在理解代码结构和生成代码或文本方面表现出色。例如,OpenAI的Codex模型已成功应用于多种软件工程任务,包括生成代码、修复缺陷和提供代码摘要。尽管LLMs在软件开发领域展现出巨大潜力,但它们在实际应用中的性能仍有待进一步研究。
最近,ChatGPT这一新的LLM因其在自动修复软件方面的潜力而受到关注。事实上,现有的ChatGPT程序修复研究倾向于使用旧的公开可用的基准数据(2022年之前的)来评估其性能,这些数据可能已经泄露到ChatGPT的训练语料库中。这种实验偏差可能危及报告结果对新的和未见过的问题的泛化性。此外,ChatGPT的代码生成和摘要/解释能力在文献中尚未得到彻底研究。
为了填补这些空白,我们计划进行实证研究,评估ChatGPT作为自动化编程助手的潜力。研究将关注以下关键任务:
代码生成:我们首先评估ChatGPT在两个LeetCode编程数据集上的自然语言到代码(代码生成)能力。程序修复:我们将ChatGPT作为程序修复工具,修复编程作业基准中的大量多样化错误代码。由于作业通常是常见的编码问题,并且它们是代码片段,因此对这些作业的发现可能具有普遍性。代码摘要:探索ChatGPT是否能够准确解释学生作业基准中正确和错误代码样本的意图。我们将详细说明我们如何减轻实验中的数据泄露问题。以下是我们做出的贡献:
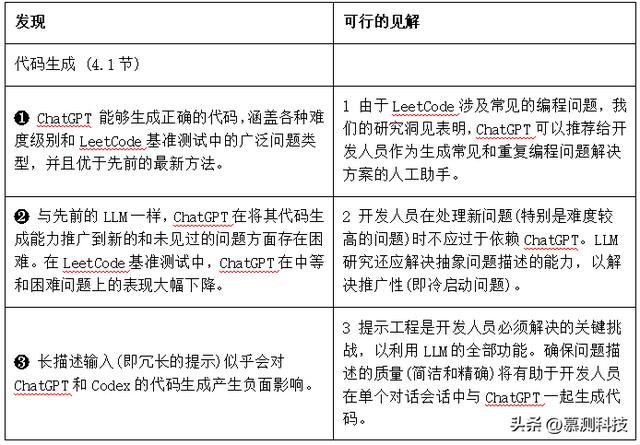
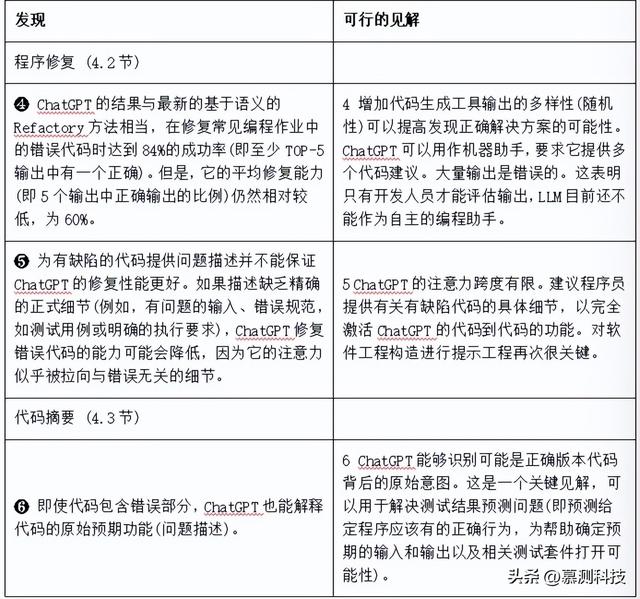
我们对ChatGPT在代码生成、程序修复和代码总结任务上的表现进行了实证研究,使用了两个基准测试。我们调查了ChatGPT在常见编程问题上的实际性能,并将其与最先进的方法进行了比较。我们在表1中分析了ChatGPT性能的有趣发现及其影响。这些发现为采用大型语言模型(LLMs)进行编程辅助提供了可操作的见解,并为软件工程社区中ChatGPT的实际应用提供了更好的理解。表1:关于 ChatGPT 在代码生成、程序修复和代码摘要任务上的关键发现和可行的见解
我们注意到,ChatGPT已经在一个广泛且多样的文本数据集上进行了训练,包括网页、书籍、文章和在线论坛等来源。这实际上给相关研究带来了潜在的数据泄露问题。因为在选择用于评估ChatGPT的实验基准测试集时,我们不确定ChatGPT是否已经提前学习了这些基准测试集中提供的解决方案参考。在这种情况下,ChatGPT的性能成果和洞见可能无法推广到新的或未见过的问题。为了评估ChatGPT的真实能力,并缓解ChatGPT可能存在的冷启动问题,我们详细说明了如何针对每个研究问题利用上述两个基准测试集。我们并不打算为ChatGPT构建全新的编程问题,因为这是不切实际的。类似的信息广泛存在于网上,这种现有知识对于有效地训练像ChatGPT这样的语言模型来预测和解决未来问题至关重要。
RQ-1: 代码生成。Refactory只包含5个编程问题,这些都可以由ChatGPT和Codex完成。因此,我们主要使用LeetCode编程问题来评估ChatGPT的代码生成能力。需要注意的是,ChatGPT的知识截止时间是2021年9月。我们首先评估ChatGPT在2016-2020年的120个(1043)LeetCode编程问题上的表现,因为这些问题的知识ChatGPT可能已经学习到了。然后,为了研究ChatGPT是否能将其能力推广到新的问题上,我们评估ChatGPT在2022年的另120个(1043)LeetCode编程问题上的表现。我们跳过2021年的LeetCode,因为它既包含可能已训练过的问题,也包含新问题,我们希望分别评估ChatGPT在这两类数据集上的表现。
RQ-2: 程序修复。为了评估ChatGPT的程序修复能力,我们使用Refactory基准测试中的1783个有bug的程序。选择的依据是: (1) 这些有bug程序的修复方案并不公开,因此ChatGPT很可能事先没有被训练过这些内容。(2) 这些有bug的作业代码非常多样化,涵盖了常见的编码问题(搜索/排序算法),它们是代码片段,在这些作业上得到的发现很可能是可推广的。虽然ChatGPT可以访问5个正确参考解决方案,但对于这样一个作业修复工具(ChatGPT在这个研究问题中的作用)来说,学习正确参考解决方案并不是问题。
RQ-3: 代码摘要。我们让ChatGPT完成为各种正确和错误代码生成代码摘要的任务。因此,我们从Refactory中找到2442个正确代码和1783个有bug代码。互联网上没有为它们提供自然语言解释。我们可以相对安全地要求ChatGPT为这些代码生成自然语言意图。
3.4 ChatGPT的应用
ChatGPT是OpenAI在2022年11月推出的一款基于大型语言模型的对话系统。对于使用ChatGPT的标准协议,目前还没有达成共识。在这一部分,我们介绍了我们在实验中如何应用ChatGPT。
ChatGPT API
OpenAI为其开发的几种模型(包括GPT-3和GPT-4)推出了ChatGPT API。其中,最新的GPT-4模型有着非常严格的请求率限制,给大规模实验带来了挑战。与此同时,最近也有报告指出GPT-4存在不稳定和不准确的问题,可能源自其彻底的重新设计。相比之下,GPT-3.5系列产生的结果更加可靠,被广泛使用。基于这一背景,我们选择了GPT-3.5模型,具体使用的是gpt-3.5-turbo-0613模型及其默认参数配置。
随机性
考虑到GPT模型固有的随机性,ChatGPT对于相同的提示输入可能会生成不同的响应,特别是在代码生成和程序修复方面。为了应对这种随机性,确保可靠的分析和结论,我们需要多次向ChatGPT请求相同的提示。我们参照之前的研究,为每个提示对ChatGPT进行五次独立的对话请求。我们用两种方式来评估性能:
(1) TOP-5,如果一种方法中至少有一次尝试成功,则该值为1,否则为0。这个指标反映了一种方法的稳健性。
(2) AVG-5,一种方法对编程问题的五次尝试的平均成功率。这个指标可以更好地表示LLM的平均性能,因为它们的TOP-1结果往往不太稳定。
prompt
prompt是利用ChatGPT和其他LLM的关键组成部分,因为它为文本或代码的生成提供了上下文和方向。我们介绍了我们在研究实验中应用的基线提示。
对于代码生成任务(RQ-1),该提示主要由LeetCode给出的编程任务描述组成,包括编程问题介绍(第1行:自然语言描述,第3-9行:示例,第11-12行:约束条件)和要完成的定义函数(第14-17行)。为了形成最终的Python代码生成提示,我们在最后添加了一个固定的请求语句:"请用Python实现上述任务。"
对于程序修复任务(RQ-2),我们遵循OpenAI设立的提示模板,如图2所示。
对于代码摘要任务(RQ-3), 我们希望获得ChatGPT关于代码语义意图的解释,而不是描述每行代码的作用,因此提示是一个固定的请求语句"你能在一句话内解释下面函数的意图吗?请不要包括任何对代码细节的解释。"

*"Correctness"列中的整数值表示这些方法在每种类型的十个编程问题中,能在五次尝试内生成正确解决方案的问题数量(TOP-5)。括号中的小数值表示五次尝试的总体平均成功率(AVG-5)。参见第3.4节中关于随机性的内容。
*"Average Rank"列中的百分比值代表生成的正确解决方案的平均排名百分位。排名越低越好。
表4提供了上述三种方法在LeetCode 2022数据集上的性能。ChatGPT和其他模型的表现都有所下降,尤其是在难题上。这表明它们在推广到新问题上仍存在一些局限性,即冷启动问题:模型无法对它还没有足够信息的问题做出任何推论。幸运的是,通过缓解数据泄露的影响,ChatGPT确实显示出了更好的性能和泛化能力。它可以解决大部分的易题(33/40)和仅2个难题。另一方面,ChatGPT生成代码的效率排名仍然在前50%的易题和中等难度问题中,但在难题中则不是。
表4:ChatGPT(GPT)、Codex(Dex)和CodeGen(Gen)在LeetCode 2022中代码生成任务上的性能表现。
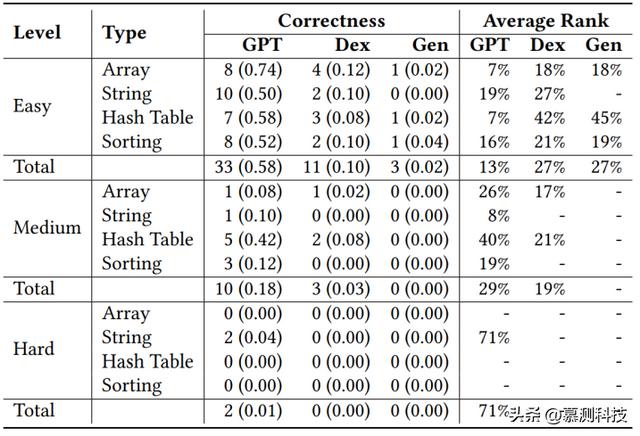
图7:ChatGPT 对重复消除问题错误实现的意图解释
总的来说,结果表明ChatGPT能够识别给定(正确或错误)代码的原始意图。这一发现使ChatGPT能够解决测试生成中的oracle问题:在没有测试套件的情况下,ChatGPT可以帮助推理代码的原始意图,进而帮助程序员确定测试期望输出并设计测试用例。我们通过分析39个错误代码样本验证了这一猜想,ChatGPT成功识别了其中30个错误的原因。
转述:吴德盛
相关文章









关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237627 电子证书1054 电子名片60 自媒体52752































