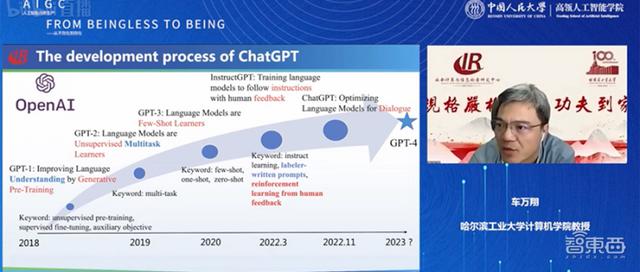
预训练阶段是从2018年到2022年,相比之前的最大变化是加入自监督学习,张俊林认为这是NLP领域最杰出的贡献,将可利用数据从标注数据拓展到了非标注数据。该阶段系统可分为预训练和微调两个阶段,将预训练数据量扩大3到5倍,典型技术栈包括Encoder-Decoder、Transformer、Attention等。
总体而言,ChatGPT有四个关键技术:
1、大规模预训练模型:只有模型规模足够大,才可能具备推理能力。中国人民大学高瓴人工智能学院长聘副教授严睿谈道,智能涌现不是故意设计出来的,而是大模型规模大到一定程度后,天然具备这样的特性。
2、在代码上进行预训练:可能代码把解决一个大的问题分解成若干个小的问题,这种分布解决问题的方式有助于自然语言推理。和自然语言模型相比,代码语言模型需要更长的上下文的依赖。
3、Prompt/Instruction Tuning:GPT-3模型太大,已经没办法去精调了,只能用prompt,但是如果不精调,模型相当于还是一个语言模型,没办法适应人,只能由人去适应模型。让人适应模型只能用指令的方式,再进行精调,这相比预训练代价要小的多。所以指令上精调就可以把一些不太多的数据,把语言模型的任务掰到适应人类的回答问题。
4、基于人类反馈的强化学习(RLHF):这对于结果好坏的影响不是特别大,甚至会限制语言模型生成的能力,但这种方式可能更好地和人类在安全性、无毒无害等等方面的价值观对齐。当模型上线后,它可以收集到更多用户的反馈。
严睿认为Human-in-the-Loop可能是大型语言模型成功的一个重要因素,通过RLHF不断获得人类反馈,将人的指令与机器的理解逐渐对齐,实现智能的不断演化。
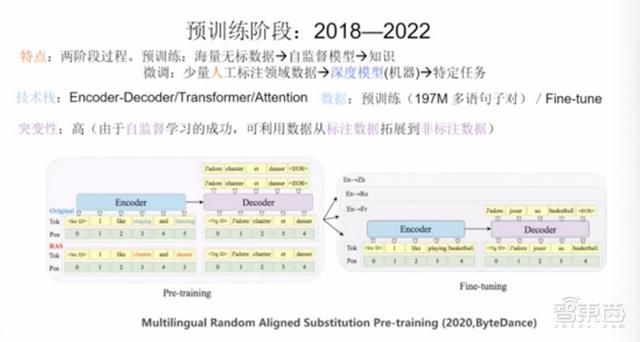
展望未来,ChatGPT能发展多久?车万翔发现了一个有意思的规律。如图所示,每个箭头长短代表技术发展的时间长度,可以看到,新技术的发展时间大约是旧技术的一半,以此推演,预训练模型可能发展五年到2023年,再往后可能到2025年左右会有新技术产生。
 五、大模型的未来:多模态、具身智能、社会交际
五、大模型的未来:多模态、具身智能、社会交际车万翔认为,ChatGPT可以说是继数据库和搜索引擎后的全新一代知识表示和检索的方法。

从知识表示和运用角度来看,知识在计算机内如何表示是人工智能最核心的问题之一。早期是通过关系型数据库的方式,精度较高,因为数据库中每行每列的语义都非常明确,问题是调用的自然度极低,必须由人去学习机器的语言,早期这些存储方式产生了Oracle、微软等科技巨头。
后来互联网上存储了人类全部的知识,这种知识表达方式不如数据库精确,但存储量大、信息多,调取这些知识需要借助搜索引擎、通过关键词的方式,关键词和SQL语句比起来就更为广大用户所接受,表达自然度更好,但仍然不及自然语言,产生谷歌、百度等科技巨头。
到大模型时代,可以认为大模型也是一种知识存储的方式,不是以人能看懂的方式来存储,而是以参数的方式来存储,可读性、精度相对较低,但调用方式非常自然,通过自然语言就能调出大模型中的知识。车万翔相信和前两次革命一样,大模型时代会出现新的科技巨头,现在看来OpenAI非常具有这样的潜力,领先优势明显。
谈到大型语言模型研究的重心,车万翔和张俊林都认为除了语言外,还需要更多知识。
关于NLP的过去、现在、未来,科学家们在2020年提出了一个world scope概念,将NLP的发展进程分为语料库、互联网、多模态、具身智能、社会交际这五个world scope。

早期NLP基于文本,再往后发展要走向多模态、具身认知、社会交际。ChatGPT已经似乎有与人类社会互动的意思,相当于是跳过了中间两步,但车万翔认为,要真正实现通用人工智能,中间这两步是不能跳的,不然就像盲人在学语言。据传GPT-4会是一个多模态大模型,如果解决了多模态这一步,那就只剩下具身了。
多模态大型语言模型的目标是增强更多的现实环境感知能力,包括视觉输入(图片、视频)、听觉输入(音频)、触觉输入(压力)等等。张俊林认为,目前阻碍多模态大模型发展的一个障碍是其很大程度上依赖于人工整理的大数据集,图像处理的自监督技术路线尚未走通,如果走通可能会是又一大技术突破,一些图像理解类任务大概率会被融入大型语言模型,不再单独存在。
多模态大模型是具身智能的基础,相当于大脑,它还需要身体,才能与物理世界的交互。因此下一步就是将大脑与身体(如机器人等)结合的具身智能,利用强化学习,从真实世界获得真实反馈、学习新的知识。
另一个值得探讨的话题是大型语言模型的规模,做大还是做小?
张俊林谈道,一方面,Scaling Law说明了模型规模越大,数据越多,训练越充分,大型语言模型的效果越好;另一方面,训练成本太高了,Chinchilla证明了如果在数据充足的前提下,目前大型语言模型的规模比应有的合理大小更大些,似乎存在参数空间浪费。因此应该是:先把模型做小,充分利用模型参数后,再将模型做大。
除此之外,张俊林认为大型语言模型的复杂推理能力未来将进一步提升。大型语言模型如何与专用工具结合也是非常有前景的方向,但技术尚不成熟,他判断OpenAI应该不会走这条路。

大型语言模型还有很多问题有待克服,包括构建中文评测数据集、优化新知识的获取、优化旧知识的修正、探索私域领域知识的融入、优化更好理解命令的能力、降低训练推理成本等等。
结语:大模型与生成式AI驶入快车道自然语言处理被誉为人工智能皇冠上的明珠,而其最新代表之作ChatGPT凭借卓越的多轮对话和内容生成能力,正掀起新一轮人工智能研究、商用及创业热潮。
ChatGPT仍有很多问题,比如事实检索性和复杂计算性效果差,无法实现一些实时性、动态变化性的任务等。但优化这些问题以及提升大模型能力的研究正在飞速推进。
如果上周微软德国公司CTO兼AI部门主管Andreas Braun透露的信息为真,那么本周OpenAI将发布更强大的GPT-4多模态大模型,打通认知与感知的连接。百度基于文心大模型研发的生成式对话产品“文心一言”也将于本周四3月16日正式发布。微软将在周五举行主题为“与AI一起工作的未来”的在线活动。大模型与生成式AI领域正变得愈发热闹。
相关文章







关于作者

猜你喜欢































