《科创板日报》4月10日讯(编辑 郑远方)短短一周不到,视觉领域接连迎来新模型“炸场”,图像识别门槛大幅降低——
这场AI热潮中鲜见动静的Meta终于出手,推出Segment Anything工具,可准确识别图像中的对象,模型和数据全部开源;
国内智源研究院视觉团队也提出了通用分割模型SegGPT(Segment Everything in Context),这也是首个利用视觉上下文完成各种分割任务的通用视觉模型。
其中,Meta的项目包括模型Segment Anything Model(SAM)、数据集Segment Anything 1-Billion mask dataset(SA-1B),公司称后者是有史以来最大的分割数据集。
引起业内轰动的便是这一SAM模型:
1. 正如名字“Segment Anything”一样,该模型可以用于分割图像中的一切对象,包括训练数据中没有的内容;
2. 交互方面,SAM可使用点击、框选、文字等各种输入提示(prompt),指定要在图像中分割的内容,这也意味着,用于自然语言处理的Prompt模式也开始被应用在计算机视觉领域。
3. 对于视频中物体,SAM也能准确识别并快速标记物品的种类、名字、大小,并自动用ID为这些物品进行记录和分类。

西部证券指出,Meta此次推出SAM,预示着大模型在多模态发展方面更进一步,布局计算机视觉/视频的厂商有望持续受;还有券商补充称,SAM模型突破了机器视觉底层技术。
国盛证券预计,预计1-5年内,多模态发展将带来AI泛化能力提升,通用视觉、通用机械臂、通用物流搬运机器人、行业服务机器人、真正的智能家居会进入生活;5-10年内,结合复杂多模态方案的大模型有望具备完备的与世界交互的能力,在通用机器人、虚拟现实等领域得到应用。
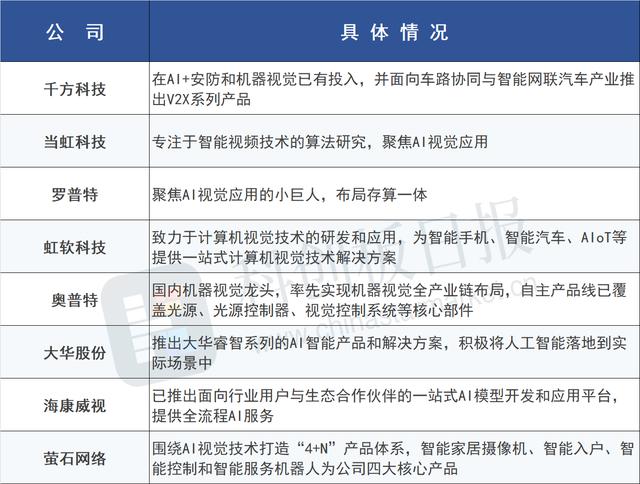
据《科创板日报》不完全统计,A股中有望受益于多模态发展的公司有:
相关文章









关于作者

猜你喜欢































