Pine 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT的热度稍有平息,蛰伏已久的Meta就迅速放出“大招”:
一次性发布四种尺寸的大语言模型LLaMA:7B、13B、33B和65B,用小杯、中杯、大杯和超大杯来解释很形象了有木有(Doge)。
还声称,效果好过GPT,偏向性更低,更重要的是所有尺寸均开源,甚至13B的LLaMA在单个GPU上就能运行。
消息一出,直接在网上掀起一阵热度,不到一天时间,相关推文的浏览量就已经快破百万。
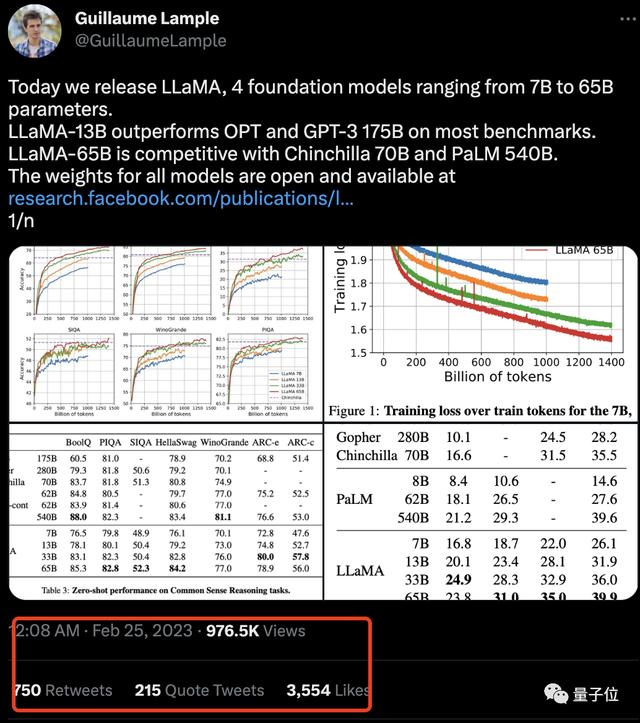
不过话说回来,这次Meta的LLaMA模型到底如何?
一起来一探究竟。
数学编程写求职信统统都能拿下Meta发布的LLaMA是通用大语言模型,原理就不多赘述,和以往的大语言模型一样:
将一系列单词作为输入,并预测下一个单词以递归生成文本。
这次,Meta之所以一次给出不同大小的LLaMA模型,论文中给出了这样的解释:
近来的研究表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由基于更多数据训练的更小的模型实现的。
论文的最后也给出了一些栗子:
比如说,给出几个数字,它直接就能找出其中的规律并续写,还balabala解释了一大通。


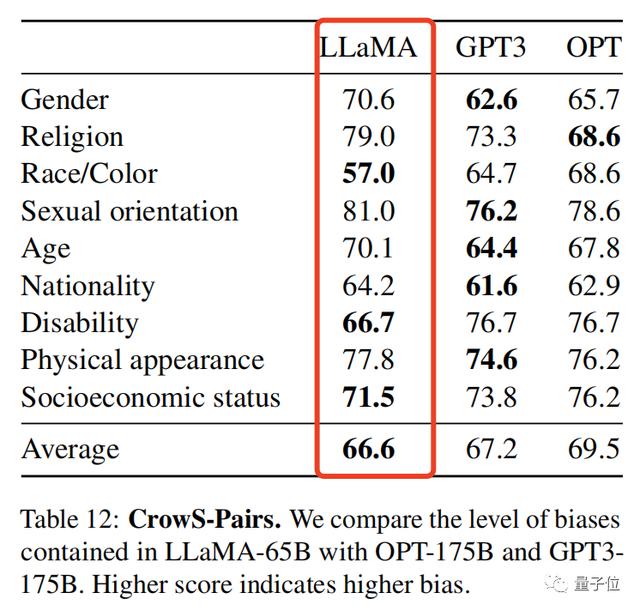
甚至,研究人员还提供了一组评估模型偏见性和毒性的基准,得分越高,偏见就越大:
LLaMA以66.6分险胜,偏见性略低于GPT-3。
你对Meta这次的LLaMA怎么看呢?如果还想了解更多可以戳文末链接~
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/参考链接:[1] https://ai.facebook.com/blog/large-language-model-llama-meta-ai/[2] https://twitter.com/GuillaumeLample/status/1629151231800115202[3] https://twitter.com/ylecun/status/1629243179068268548
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章






关于作者

猜你喜欢































