©原创作者 | LJ
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
https://arxiv.org/pdf/2112.06905.pdf
01 摘要这是上个月谷歌刚刚在arxiv发布的论文,证明了一种能scale GPT-3但又比较节省耗能的架构。
GPT-3自问世以来在多项自然语言处理的任务上都有超强的表现。但是训练GPT-3这样庞大的模型非常耗费能源。
在这篇论文中,作者开发了以Mixture of Experts为基础的GlaM (Generalist Language Model)。它虽然参数量有GPT-3的7倍之多,但训练起来只需GPT-3三分之一的能耗,而且在NLP任务的表现上相比GPT-3持平甚至更优。
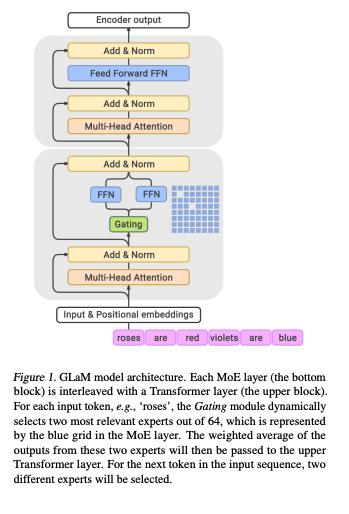
02 什么是Mixture of Experts Model (MoE)MoE这个概念其实已经提出很久了。这个概念本身非常容易理解,有点类似ensemble:与其训练一个模型,我们训练数十个独立的“专家模型”(expert model)。
与简单的ensemble不同的是,在做训练或推断(inference)的时候,我们用一个gating network来“挑选专家” — 在几十个专家模型中挑选出几个适合的专家模型用来计算。通俗的讲,这些专家“术业有专攻”,根据所长而分工。
那么,为什么MoE可以省能耗呢?因为无论是训练或者推算的时候,每次真正的计算只有几个专家被激活。所以,虽然参数量很大,但每次用到的参数只是很小的一部分。
这个团队在2017年在一篇ICLR的论文[1]里已经把MoE的概念应用在了当时NLP state-of-the-art的RNN model上,并且超越了当时的state of the art。

这次,因为GPT-3的发布,作者又将MoE的概念应用在GPT-3这样以transformer为基础的模型上。
GLaM在29个自然语言的任务上总的来说相比GPT-3略胜一筹。最重要的是训练的总能耗仅仅是GPT-3的三分之一。
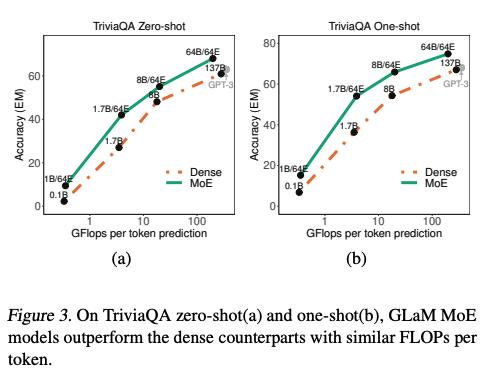
以TriviaQA任务举例,上图中Dense指的是类似GPT-3架构的单个模型。Dense和MoE model的准确率都会因为参数量增长而增长。但是在相同的运算量下(横轴),MoE总是表现得更好。
4.2. 需要多少专家模型
相比于dense model,MoE如果想scale的话不仅可以将模型变得更宽更深,还可以增加专家的数量。只要每次被激活的专家数量不变,增加专家并不增加prediction时的运算量。
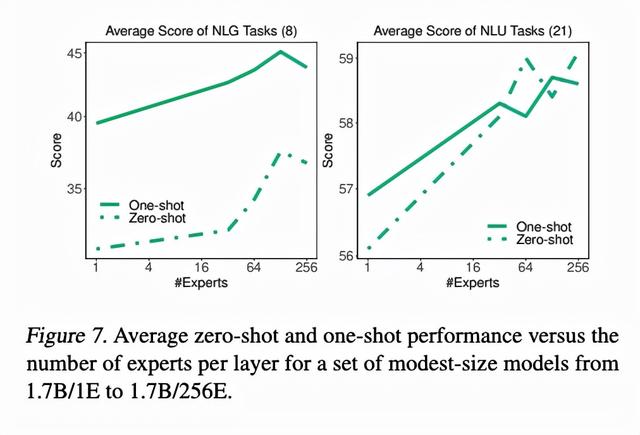
上图中,作者控制每次prediction的计算量不变,调整不同的专家数量。一般看来,专家越多,模型表现越好。
05 总结总的来说,作者开发了以MoE为基础的GLaM模型。虽然模型参数量很多,但通过激活少量的专家,这类的模型训练和推算的能耗更低,而且结果比GPT-3更好。
相关文章








关于作者

猜你喜欢































