古谚道:“熟读唐诗三百首,不会作诗也会吟。” 这句话放在目前的人工智能语言模型中也非常适用。
此前,OpenAI 的研究人员开发出 “GPT-3”,这是一个由 1750 亿个参数组成的 AI 语言模型,堪称有史以来训练过的最大的语言模型,可以进行原始类比、生成配方、甚至完成基本代码编写。
如今,这一记录被打破了。近日,谷歌研究人员开发出一个新的语言模型,它包含了超过 1.6 万亿个参数,这是迄今为止最大规模的人工智能语言模型,比之前谷歌开发的语言模型 T5-XXL 的规模大了 4 倍。
参数是机器学习算法的关键所在,它们是从历史训练数据中学习到的模型的一部分。一般而言,在语言领域中参数的数量和复杂度之间的相关性非常好。这一点类似于 GPU 中晶体管的数量,在同样的制程工艺下,晶体管越多其算力便越强,而语言模型包含的参数愈多就愈接近人类自然语言。
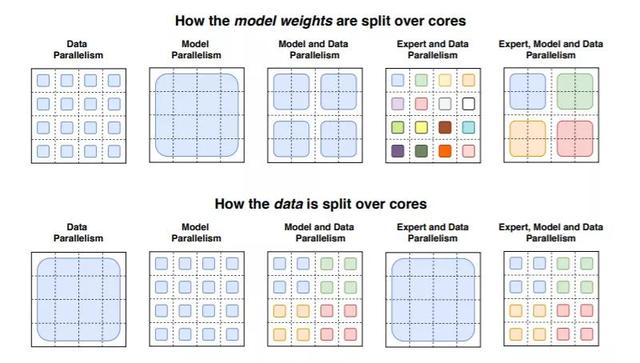
正如研究人员在一篇论文中指出的那样,大规模的训练是通向强大模型的有效途径,在大数据集和参数计数的支持下,简单的体系结构远远超过了更复杂的算法。但是,有效的大规模培训在计算上非常密集。这就是为什么研究人员热衷于他们所说的 “开关变压器”,这是一种 “稀疏激活” 技术,它只使用模型权重的一个子集或者在模型中转换输入数据的参数。
“开关变压器” 是早在 90 年代初首次提出的一种人工智能模型范例,大体意思是将多个专家或专门处理不同任务的模型放在一个更大的模型中,并有一个 “门控网络” 来选择为任何给定数据咨询哪些专家。
在一项实验中,研究人员使用 32 个 TPU 内核对几个不同的 “开关变压器” 模型进行了预训练,这些 TPU 内核位于一个从 Reddit、Wikipedia 和其他网络资源中搜集的 750GB 大小的文本数据语料库中,任务则是让这些模型预测段落中 15% 的单词被遮住的缺失单词,以及其他挑战,比如检索文本来回答一系列越来越难的问题。
研究人员称,包含了 1.6 万亿参数和 2048 名专家的模型 Switch-C 显示 “完全没有训练不稳定性”。然而,在桑福德问答数据集的基准测试中,Switch-C 的得分居然比仅包含 3950 亿个参数和 64 名专家的模型 Switch-XXL 还要低一点,对此,研究人员认为是因为微调质量、计算要求和参数数量之间的不透明关系所致。
在这种情况下,“开关变压器” 导致了一些下游任务的收益。例如,研究人员称在使用相同数量的计算资源的情况下,它可以使训练前的加速速度提高 7 倍以上。他们还证明 “稀疏激活” 技术可以用来创建更小、更密集的模型,这些模型可以对任务进行微调,其质量增益为大型模型的 30%。
对此他们表示:虽然这项工作主要集中在超大模型上,但我们也发现只有两名专家的模型可以提高性能,同时很容易适应通用 GPU 或 TPU 的内存限制。另外,通过将稀疏模型提取为稠密模型,可以实现 10 到 100 倍的压缩率,同时获得专家模型约 30% 的质量增益。
在另一个测试中,“开关变压器” 模型被训练在 100 多种不同语言之间进行翻译,研究人员观察到 101 种语言的 “普遍改善”,91% 的语言受益于比基线模型快 4 倍以上的速度。未来,研究人员还计划将 “开关变压器” 应用于新的领域,比如图像和文本。他们认为,模型稀疏性可以赋予优势,在一系列不同的媒体以及多模态模型。
美中不足的是,研究人员的工作没有考虑到这些语言模型在现实世界中的影响,比如模型通常会放大一些公开数据中的偏见。对此,OpenAI 公司指出,这可能导致在女性代词附近放置 “淘气”;而在 “恐怖主义” 等词附近放置 “伊斯兰” 等。根据米德尔伯里国际研究所的说法,这种偏见可能被恶意行为者利用,通过散布错误信息、造谣和谎言来煽动不和。
而路透社也曾报道称,谷歌的研究人员现在被要求在研究人脸和情绪分析以及种族分类等话题之前,先咨询法律、政策和公关团队,性别或政治派别。
综上所述,尽管谷歌训练的 1.6 万亿参数的人工智能语言模型还没办法做到真正意义上的人工智能,存在一些不足之处需要完善和优化,但随着在摩尔定律下电子设备算力的不断提升,近些年 AI 语言模型参数量级呈指数倍发展,相信在不久的将来,或许真的会出现一个无限接近熟读人类历史所有文明记录的超级模型,能够和人类完全实现自然语言交流,不妨让我们好好期待一下吧!
相关文章






关于作者

猜你喜欢































