
GPT-4是一个多模态大模型,具有更强大的创造性、更长的上下文处理能力,可支持图像输入,还可以自定义GPT-4的语言风格。在OpenAI短短24分钟的发布会中,有这样一个场景:在草稿本上用纸笔画出一个非常粗糙的草图,拍照并上传,GPT-4在10秒左右直接生成了网站代码。
著名经济学家朱嘉明表示:GPT-4是OpenAI创造出的又一个重大科技事件,达到了AI历史上前所未有的、不可逆转的新高度。
过去两年,OpenAI重建了整个深度学习堆栈,并与微软Azure一起从头开始共同设计了一台超级计算机。一年前,OpenAI训练GPT-3.5(即ChatGPT)作为系统的第一次“试运行”,发现并修复了一些错误并改进了理论基础。
OpenAI花了6个月的时间来迭代调整GPT-4,取得了有史以来最好的结果,并且成为第一个能够提前准确预测其训练性能的大型模型。这意味着大模型的训练方法将会从过去的纯粹“暴力美学”进化出更高的可控性与预期性。
这次OpenAI并没有公布论文,只有一份技术报告,并且不提供架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等细节。换句话说,其他AI公司不可能再像过去一样,走一条模仿、复现、超越的道路了。
压力来到了国内公司,尤其是明天即将发布文心一言的百度。
1.比ChatGPT更强大GPT-4比以往任何时候都更具创造性和协作性。它可以承担文本、音频、图像的生成、编辑任务,并能与用户一起迭代创意和技术写作任务,例如创作歌曲、编写剧本或学习用户的写作风格等。

GPT-4能够处理超过25000个单词的文本,允许使用长格式内容创建、扩展对话以及文档搜索和分析等用例。

左边是ChatGPT,右边是GPT-4
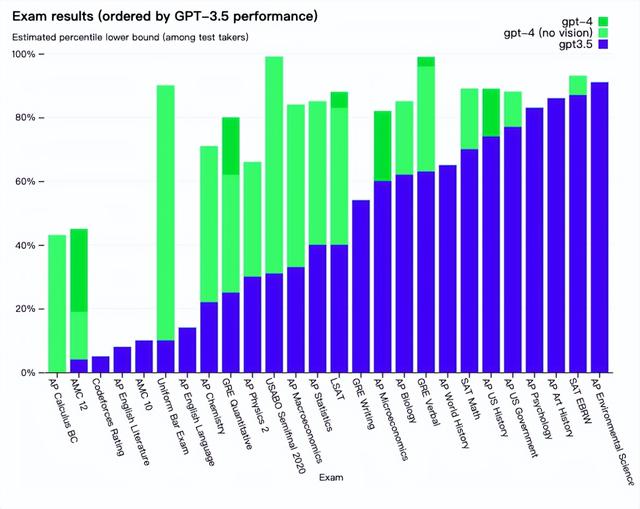
为了解这两种模型之间的区别,OpenAI在各种基准测试中进行了测试,包括人类的模拟考试,比如GRE。OpenAI并没有针对这些考试进行专门培训,但GPT-4的排名依然名列前茅。例如,它通过模拟律师考试,分数在应试者的前10%左右;相比之下,GPT-3.5的得分在倒数10%左右。



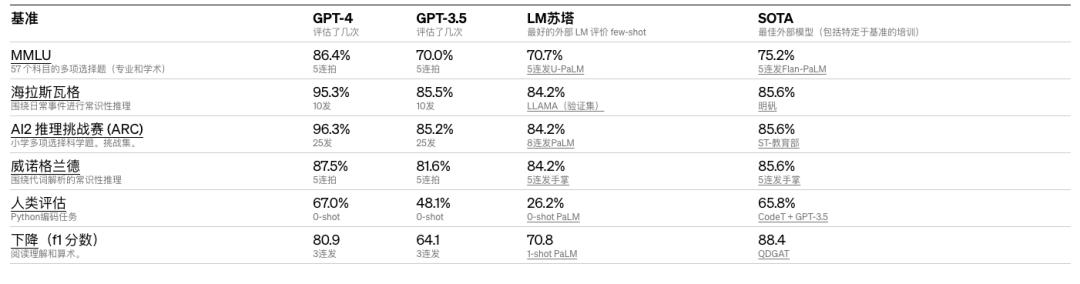
OpenAI在为机器学习模型设计的传统基准上评估了GPT-4,大大优于现有的大型语言模型,以及大多数最先进的 (SOTA) 模型:
GPT-4还能读懂“梗图”,理解幽默
GPT-4甚至可以直接阅读并分析带有图片的论文:


GPT-4项目的主要焦点之一是构建可预测扩展的深度学习框架,主要原因是对于像GPT-4这样非常大的训练任务,进行大量的模型特定调整是不可行的。
OpenAI开发了基础设施和优化方法,能够在多个规模下表现出非常可预测的行为。为了验证这种可扩展性,OpenAI通过对使用相同方法进行训练但计算量少10000倍的模型进行推断,在内部代码库(不是训练集的一部分)上准确预测了GPT-4的最终损失。
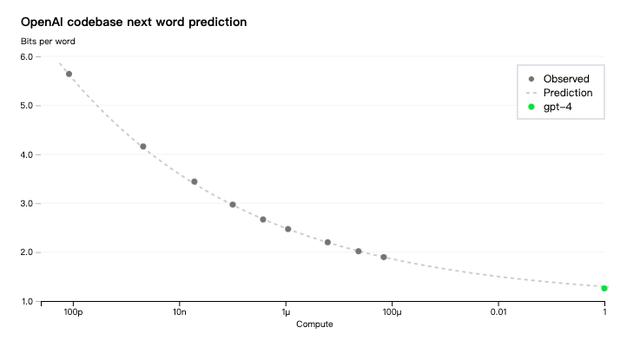
现在OpenAI可以准确预测OpenAI在训练期间优化的指标(损失),开始开发方法来预测更多可解释的指标。例如,OpenAI成功预测了HumanEval数据集子集的通过率,从计算量减少 1000 倍的模型推断。
OpenAI认为,准确预测未来的机器学习能力是安全的重要组成部分,但相对于其潜在影响而言,它并没有得到足够的重视。OpenAI正在加大力度开发方法,为社会提供更好的未来系统预期指导,希望这成为该领域的共同目标。
4.如何尝鲜GPT-4?目前有两种办法可以体验GPT-4。
如果你是普通用户,此前订阅了ChatGPT Plus,将会直接获得GPT-4的访问权限。不过,ChatGPT Plus只能用美国信用卡开通。
OpenAI将根据实践中的需求和系统性能调整使用上限,但预计会受到严重的容量限制。
根据OpenAI看到的流量模式,OpenAI可能会为更高容量的GPT-4使用引入新的订阅级别;OpenAI也希望在某个时候提供一些免费的GPT-4查询,这样那些没有订阅的人也可以尝试一下。
如果你是开发者,要访问GPT-4 API(使用与GPT-3.5-turbo相同的ChatCompletions API),需要像等待New Bing一样加入OpenAI的候补名单。
OpenAI今天将开始邀请一些开发人员,并逐步扩大规模以平衡容量与需求。
OpenAI也公布了定价策略——每1000个prompt tokens 0.03美元,每1000个completion tokens 0.06美元。默认速率限制为每分钟4万个token和每分钟200个请求。
GPT-4的上下文长度为8192个token。OpenAI还提供了32768 个tokens上下文(约50页文本)版本的有限访问,该版本也将随着时间自动更新(当前版本GPT-4-32k-0314,支持到6月14日)。定价为每1000个prompt token 0.06美元和每1000个completion token 0.12美元。
此外,OpenAI宣布开源其软件框架OpenAI Evals,用于创建和运行基准测试以评估GPT-4等模型。
OpenAI使用Evals来指导OpenAI模型的开发,OpenAI的用户可以应用它来跟踪模型版本的性能,并不断发展产品集成。例如,Stripe使用Evals来补充他们的人工评估,以衡量其基于GPT的文档工具的准确性。
由于所有代码都是开源的,Evals支持编写新的类来实现自定义评估逻辑。然而,在OpenAI自己的经验中,许多基准测试都遵循几种“模板”的其中之一,因此OpenAI还包括了最有用的模板,包括一个“模型评估模板”——OpenAI发现GPT-4出人意料地能够检查自己的工作。
OpenAI希望Evals成为分享和众包基准测试的工具,代表着最广泛的失败模式和困难任务。作为一个示范,OpenAI创建了一个逻辑谜题评估,其中包含GPT-4失败的十个提示。Evals也与实施现有基准测试兼容;OpenAI包括了几个实施学术基准测试和几个(小的子集)CoQA集成的笔记本作为示例。
GPT-4已经积累了部分商业客户。比如,Stripe使用GPT-4扫描商业网站并向客户支持人员提供摘要,Duolingo将 GPT-4构建到新的语言学习订阅层中。摩根士丹利正在创建一个由GPT-4驱动的系统,该系统将从公司文件中检索信息并将其提供给金融分析师。可汗学院正在利用GPT-4构建某种自动化导师。
GPT-4将大模型推向了一个新的高度,甚至是“断崖式”领先。包括谷歌、百度在内的海内外科技公司,不可避免地将面对自家产品“发布即落后”的尴尬局面,而微软则躺在OpenAI背后“赚麻了”。
明天我们将报道百度的文心一言。
参考资料:
关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237569 电子证书1052 电子名片60 自媒体51116








































