萧箫 发自 凹非寺量子位 报道 | 公众号 QbitAI
还在担心大语言模型“啥都吃”,结果被用假信息训练了?
放在以前,这确实是训练NLP模型时值得担心的一个难题。
现在,谷歌从根本上解决了这个问题。
他们做了个名为TEKGEN的AI模型,直接将知识图谱用“人话”再描述一遍,生成语料库,再喂给NLP模型训练。

这是因为,知识图谱的信息来源往往准确靠谱,而且还会经过人工筛选、审核,质量有保障。
目前,这项研究已经被NAACL 2021接收。

整体来看,用TEKGEN生成语句的流程是这样的:

生成后的语句,就能用来放心地训练大语言模型了。
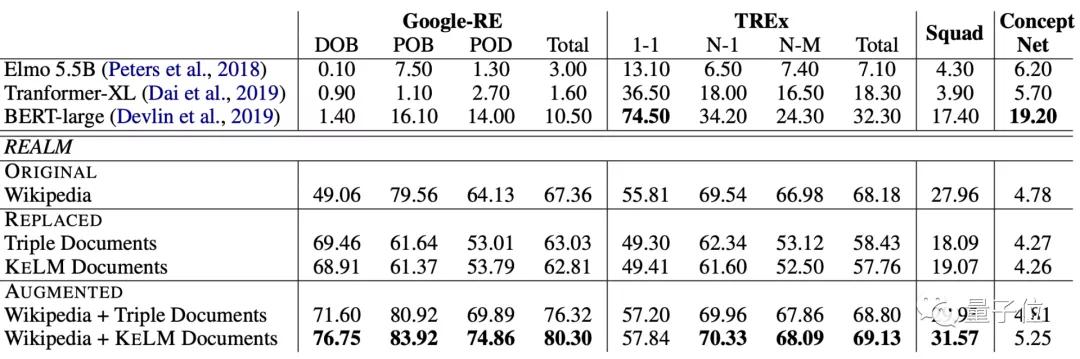
这份生成的语料库,由4500万个三元组生成,组合起来的句子有1600万句。

当然,这里面也用LAMA(LAnguage Model Analysis) probe,来对用这个语料库训练的模型进行了评估。
在Google-RE和TREx两个数据集上,经过预训练的模型,在各项任务上均取得了非常好的效果。
说不定,将来真能让AI去试试高考语文的“图文转换”题:
论文一作小姐姐Oshin Agarwal,是宾夕法尼亚大学的计算机系在读博士生,研究方向是自然语言处理中的信息抽取。
这篇论文,是她在谷歌实习期间完成的。
来自谷歌的Heming Ge、Siamak Shakeri和Rami Al-Rfou也参与了这项工作。
目前,作者们已经将这个用知识图谱生成的语料库放了出来。
想要训练NLP模型的小伙伴,可以用起来了~
论文地址:https://arxiv.org/abs/2010.12688
用知识图谱生成的语料库:https://github.com/google-research-datasets/KELM-corpus
参考链接:https://ai.googleblog.com/2021/05/kelm-integrating-knowledge-graphs-with.html
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
相关文章








关于作者

猜你喜欢
成员 网址收录40400 企业收录2981 印章生成237624 电子证书1052 电子名片60 自媒体52521































