上个月GPT-4发布时,我曾写过一篇文章分享过有关GPT-4的几个关键信息。
当时的分享就提到了GPT-4的一个重要特性,那就是多模态能力。
比如发布会上演示的,输入一幅图(手套掉下去会怎么样?)。

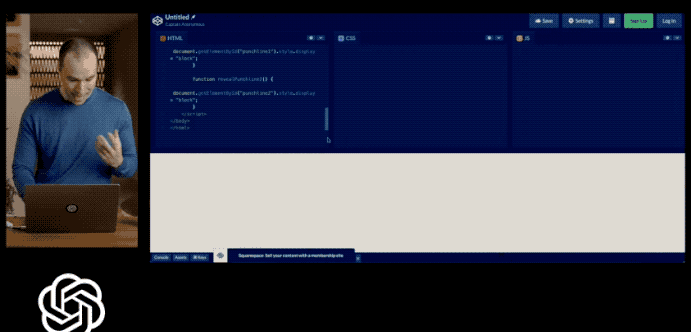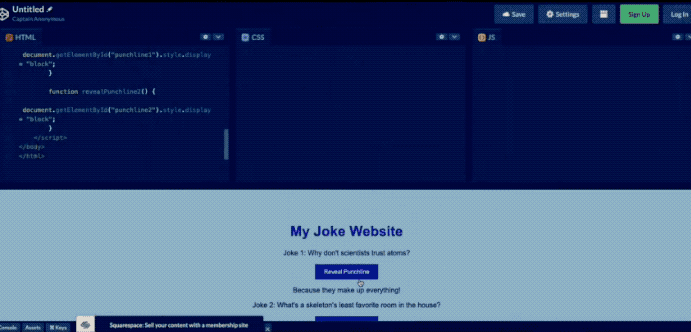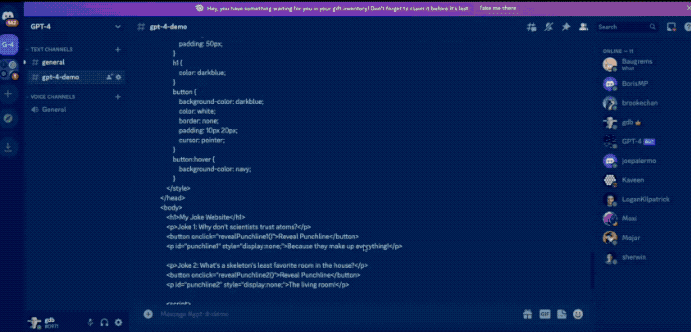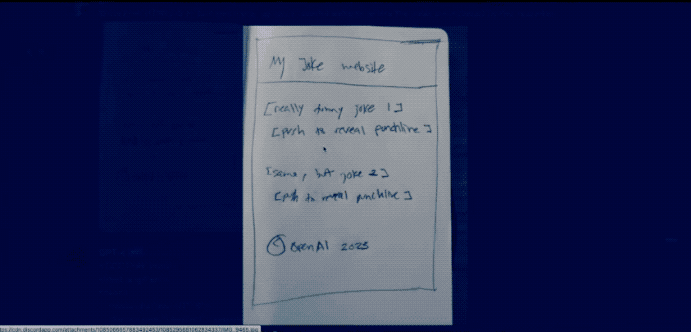
但是时间过去了这么久,GPT-4像这样的识图功能也迟迟没有开放。
就在大家都在等待这个功能开放的时候,一个名为MiniGPT-4的开源项目悄悄做了这件事情。
https://github.com/Vision-CAIR/MiniGPT-4

项目除了是开源的之外,而且还提供了网页版的demo,用户可以直接进去体验。
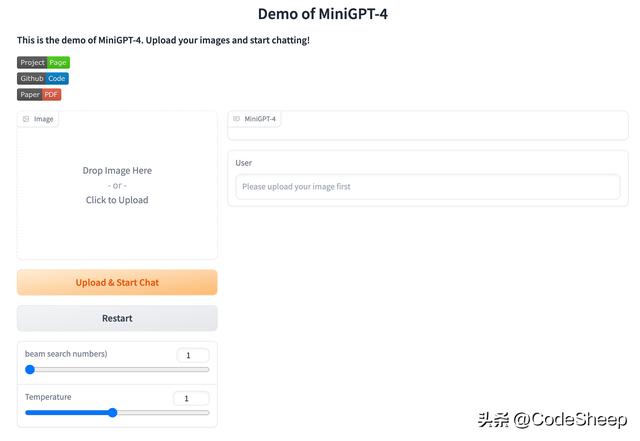
MiniGPT-4也是基于一些开源大模型来训练得到的。
团队把图像编码器与开源语言模型Vicuna(小羊驼)整合起来,并且冻结了两者的大部分参数,只需要训练很少一部分。
训练分为两个阶段。
传统预训练阶段,在4张A100上使用500万图文对,10个小时内就可以完成,此时训练出来的Vicuna已能够理解图像,但生成能力有限。
然后在第二个调优阶段再用一些小的高质量数据集进行训练。这时候的计算效率很高,单卡A100只需要7分钟。

并且团队正在准备一个更轻量级的版本,部署起来只需要23GB显存,这也就意味着未来可以在一些消费级的显卡中或许就可以进行本地训练了。
这里也给大家看几个例子。
比如丢一张食物的照片进去来获得菜谱。

或者给出一张商品的照片来让其帮忙写一篇文案。

当然也可以像之前GPT-4发布会上演示的那样,画出一个网页,让其帮忙生成代码。

可以说,GPT-4发布会上演示过的功能,MiniGPT-4基本也都有。
这一点可以说非常amazing了!
可能由于目前使用的人比较多,在MiniGPT-4网页demo上试用时会遇到排队的情况,需要在队列中等待。
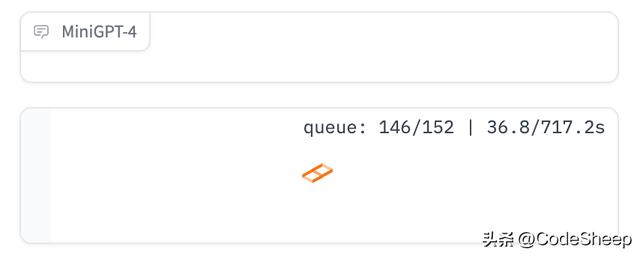
但是用户也可以自行本地部署服务,过程并不复杂。
首先是下载项目&准备环境:
git clone https://github.com/Vision-CAIR/MiniGPT-4.gitcd MiniGPT-4conda env create -f environment.ymlconda activate minigpt4
然后下载预训练模型:
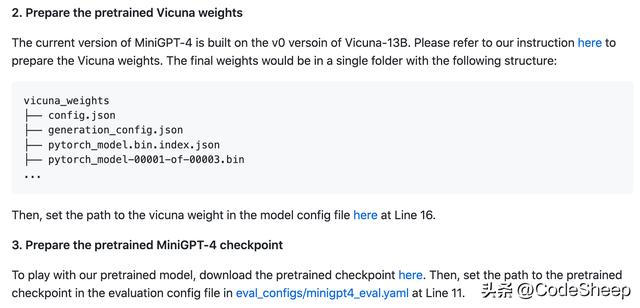
最后在本地启动Demo:
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml
通过这个项目我们也再一次看出大模型在视觉领域的可行性,未来在图像、音频、视频等方面的应用前景应该也是非常不错的,我们可以期待一下。
好了,今天的分享就到这里了,感谢大家的收看,我们下期见。
相关文章









关于作者

猜你喜欢
成员 网址收录40405 企业收录2984 印章生成242575 电子证书1086 电子名片62 自媒体71432































