在ChatGPT风靡全球数月后,OpenAI终于发布了它的大型多模态模型(large multimodal model)GPT-4,它不仅能与用户一起生成、编辑,完成创意的迭代和技术写作任务,更重要的是,它还能读懂图片。

GPT-4分别回答了图片中的问题
多模态对GPT-4这样的生成式AI来说意义重大,除了Be My Eyes的例子,未来还可望应用到一些设计工具和图像处理产品上,连OCR(光学字符识别)技术也要甘拜下风了。
视频翻译产品Targum Video的创办人Altryne也表示,GPT-4的图像理解能力已经甩开现有模型数里地。
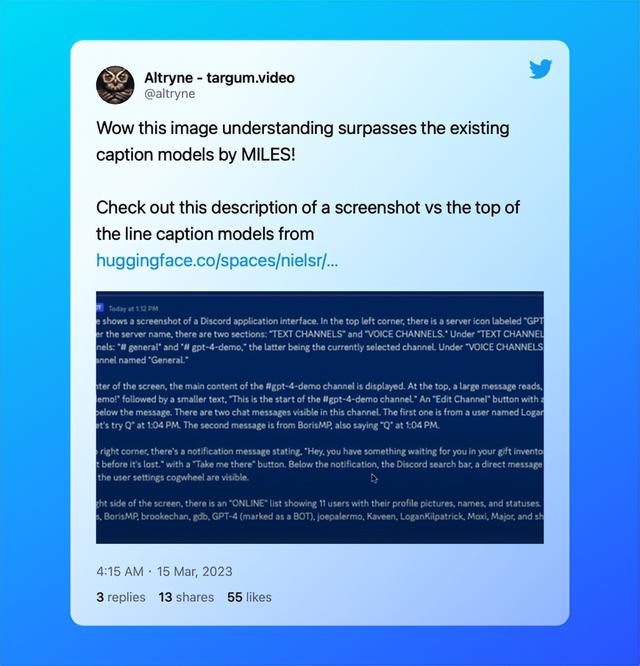
不过遗憾的是,OpenAI还没有把图像输入能力开放给公众体验,目前我们可以通过付费订阅ChatGPT Plus或Quora Poe来尝鲜。那么不会“看图说话”的GPT-4比GPT-3.5强在哪里呢?我们也通过Quora的Poe询问了一下GPT-4“本人”:
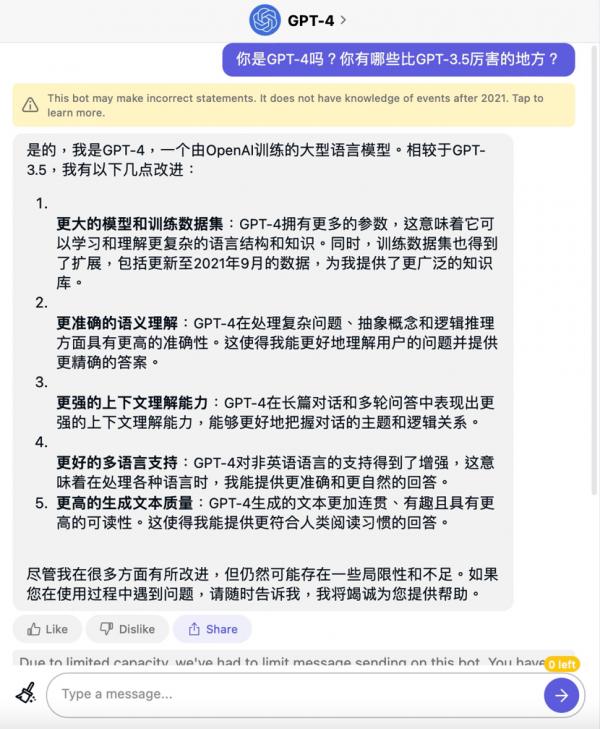
总的来说,相比GPT-3.5,GPT-4拥有更丰富的知识,对人类语言的理解能力也更准确,可以更好的理解整体对话的主题,不像以前那样一不小心就“歪楼”,非英语的语言理解能力也有所增强,生成的文本也会更连贯,可读性更高。
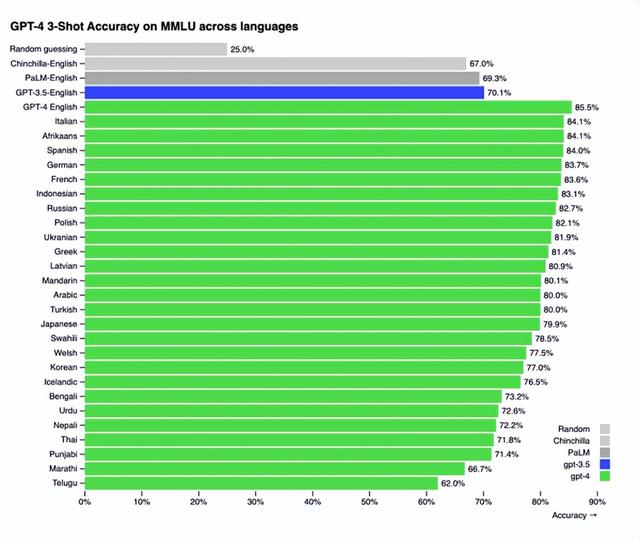
根据官方公布的数据,GPT-4不仅具备理解图片的能力,语言处理能力也有很大进步,GPT-4的中文能力已经超越GPT-3.5的英文能力了。
不过OpenAI CEO Sam Altman在Twitter上表示,GPT-4“仍然有局限性”,而且“第一次使用时似乎比你花更多时间使用它时更令人印象深刻”。
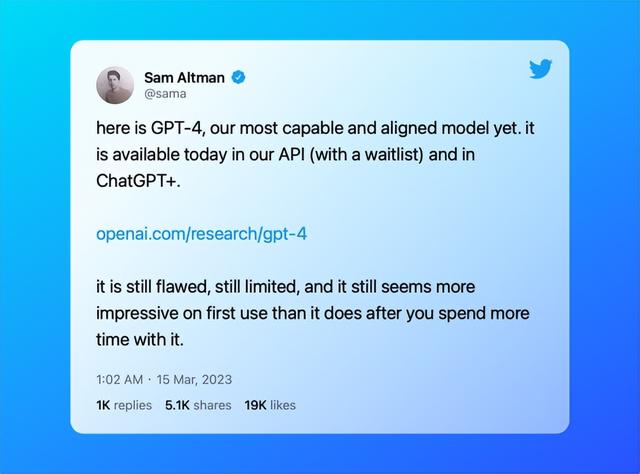
也就是说,仅从使用体验出发,GPT-4在语言能力上的改变更多体现在一些细微之处,不会像ChatGPT刚出现时那样惊为天人,不过对于多模态AI的实现来说,GPT-4的出现确也让人类再次迈出具有历史意义的一大步。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成241147 电子证书1072 电子名片60 自媒体64547































