Jay Alammar 发表的一篇blog,我用机器翻译转给大家看看,关于最火热的GPT3的工作原理。
原文地址:
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
The tech world is abuzz with GPT3 hype. Massive language models (like GPT3) are starting to surprise us with their abilities. While not yet completely reliable for most businesses to put in front of their customers, these models are showing sparks of cleverness that are sure to accelerate the march of automation and the possibilities of intelligent computer systems. Let’s remove the aura of mystery around GPT3 and learn how it’s trained and how it works.科技界充斥着 GPT3 炒作。大规模语言模型(如 GPT3)的能力开始让我们大吃一惊。虽然对于大多数企业来说,展示在客户面前的这些模型还不是完全可靠,但这些模型正在显示出聪明的火花,这些火花肯定会加速自动化的进程和智能计算机系统的可能性。让我们揭开 GPT3 的神秘面纱,了解它的训练方式和工作原理。
A trained language model generates text.经过训练的语言模型生成文本。
We can optionally pass it some text as input, which influences its output.我们可以选择将一些文本作为输入传递给它,这会影响它的输出。
The output is generated from what the model “learned” during its Training period where it scanned vast amounts of text.输出是根据模型在扫描大量文本的训练期间“学习”的内容生成的。

Please note: This is a description of how GPT-3 works and not a discussion of what is novel about it (which is mainly the ridiculously large scale). The architecture is a transformer decoder model based on this paper https://arxiv.org/pdf/1801.10198.pdf请注意:这是对 GPT-3 工作原理的描述,而不是讨论它的新颖之处(主要是荒谬的大规模)。该架构是基于本文https://arxiv.org/pdf/1801.10198.pdf的transformer解码器模型
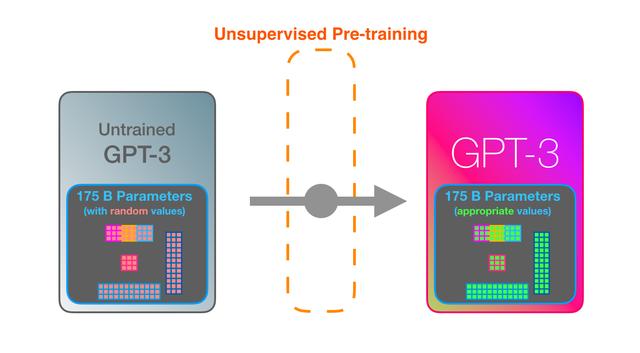
GPT3 is MASSIVE. It encodes what it learns from training in 175 billion numbers (called parameters). These numbers are used to calculate which token to generate at each run.GPT3 是巨大的。它用 1750 亿个数字(称为参数)对从训练中学到的内容进行编码。这些数字用于计算每次运行时要生成的令牌。
The untrained model starts with random parameters. Training finds values that lead to better predictions.未经训练的模型以随机参数开始。训练会找到导致更好预测的值。
These numbers are part of hundreds of matrices inside the model. Prediction is mostly a lot of matrix multiplication.这些数字是模型中数百个矩阵的一部分。预测主要是很多矩阵乘法。
In my Intro to AI on YouTube, I showed a simple ML model with one parameter. A good start to unpack this 175B monstrosity.在我在 YouTube 上的人工智能介绍中,我展示了一个带有一个参数的简单 ML 模型。打开这个 175B 怪物的包装是一个好的开始。
To shed light on how these parameters are distributed and used, we’ll need to open the model and look inside.为了阐明这些参数的分布和使用方式,我们需要打开模型并查看内部。
GPT3 is 2048 tokens wide. That is its “context window”. That means it has 2048 tracks along which tokens are processed.GPT3 是 2048 个令牌宽。那就是它的“上下文窗口”。这意味着它有 2048 个处理令牌的轨道。
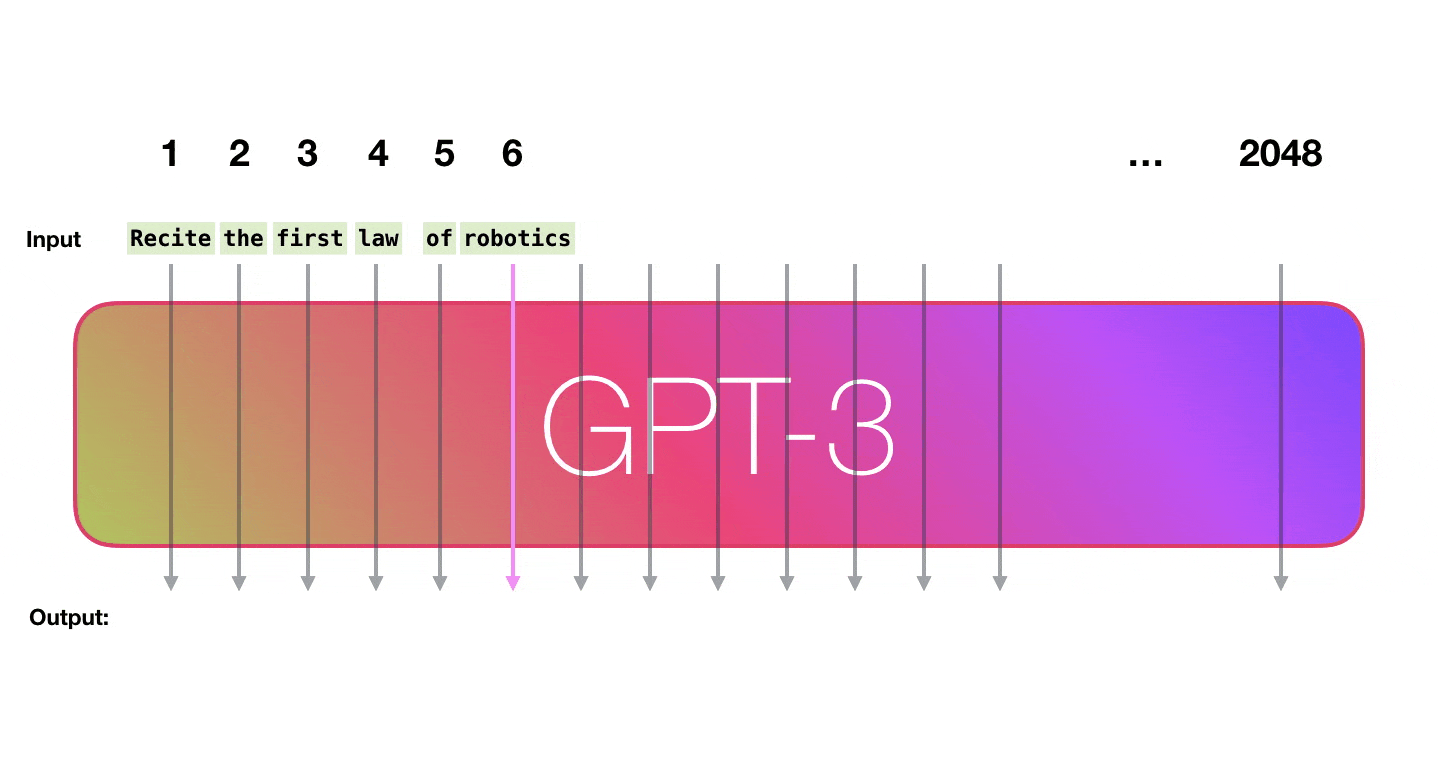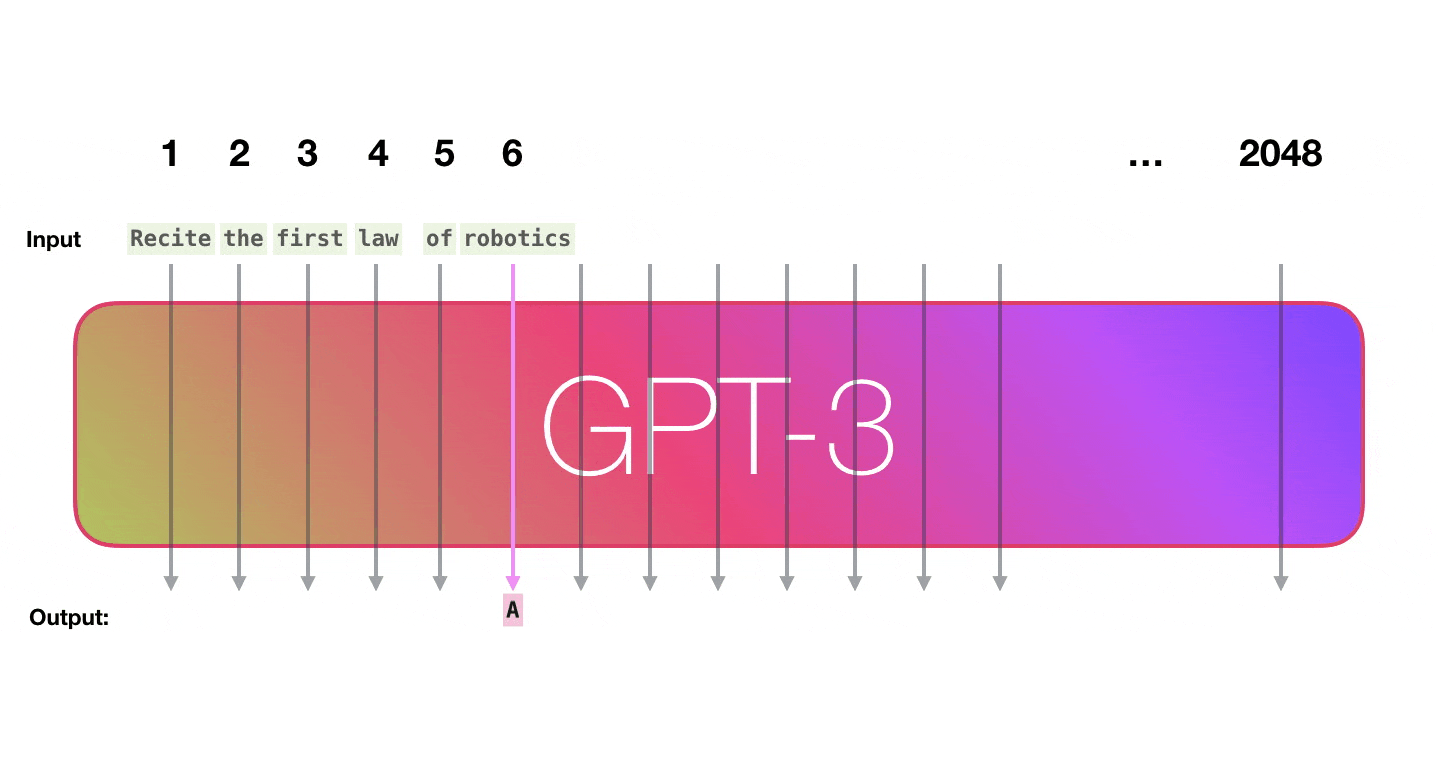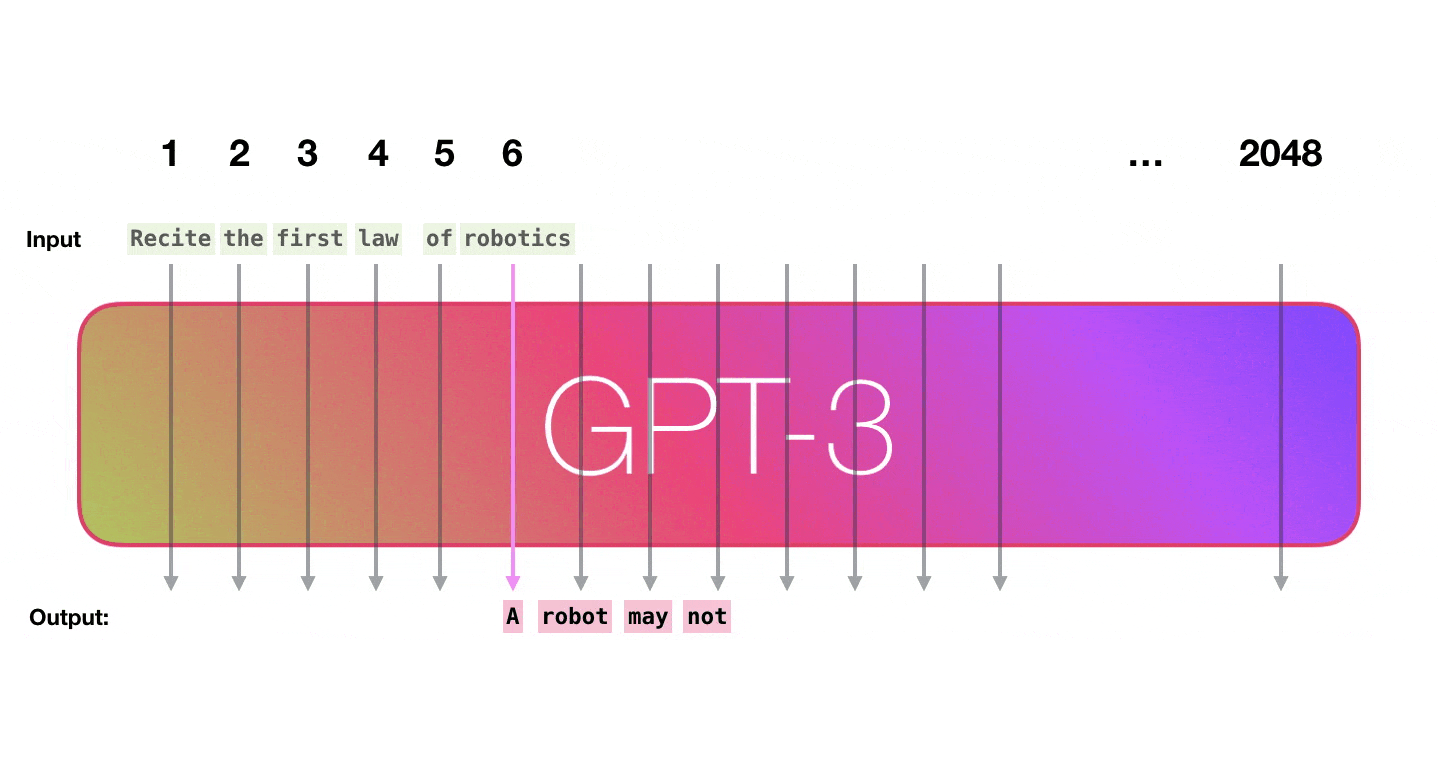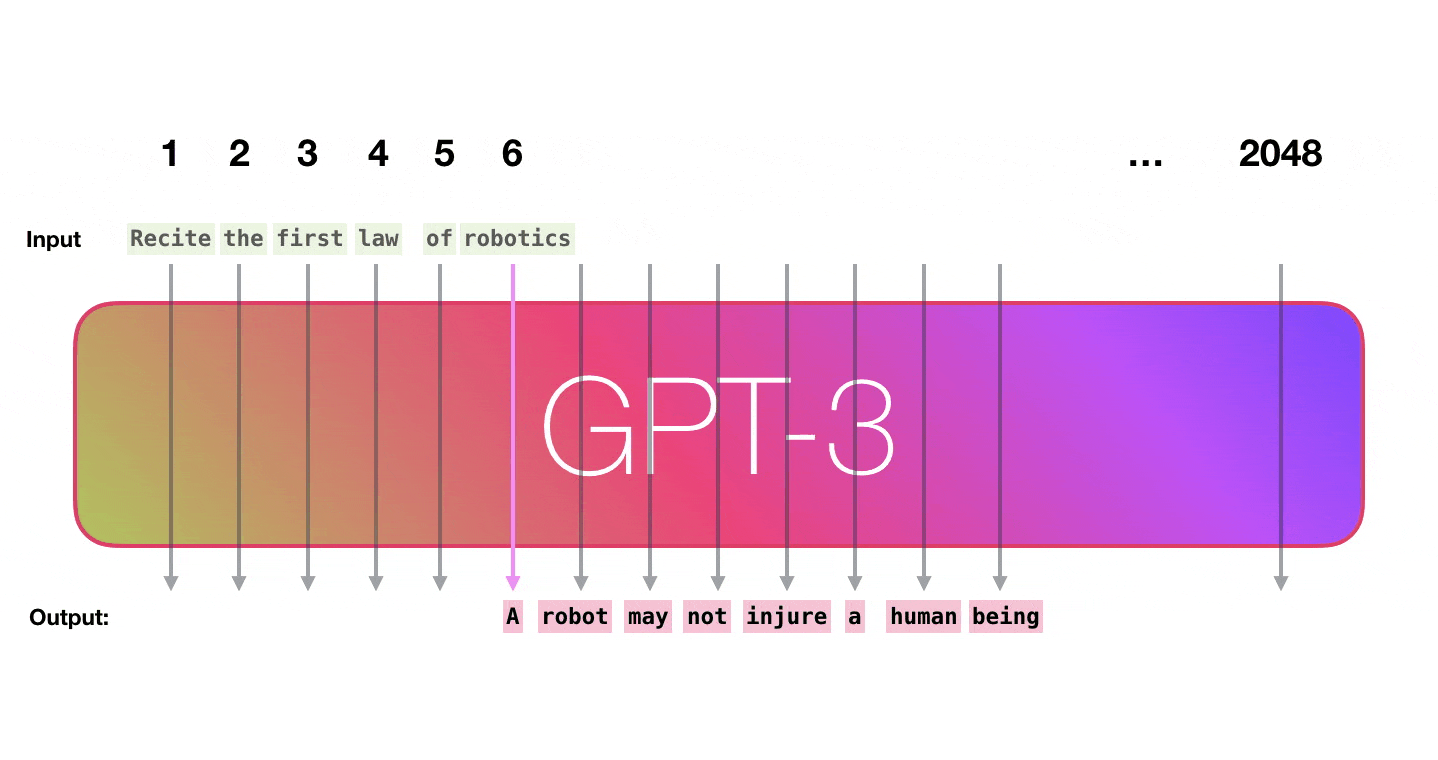
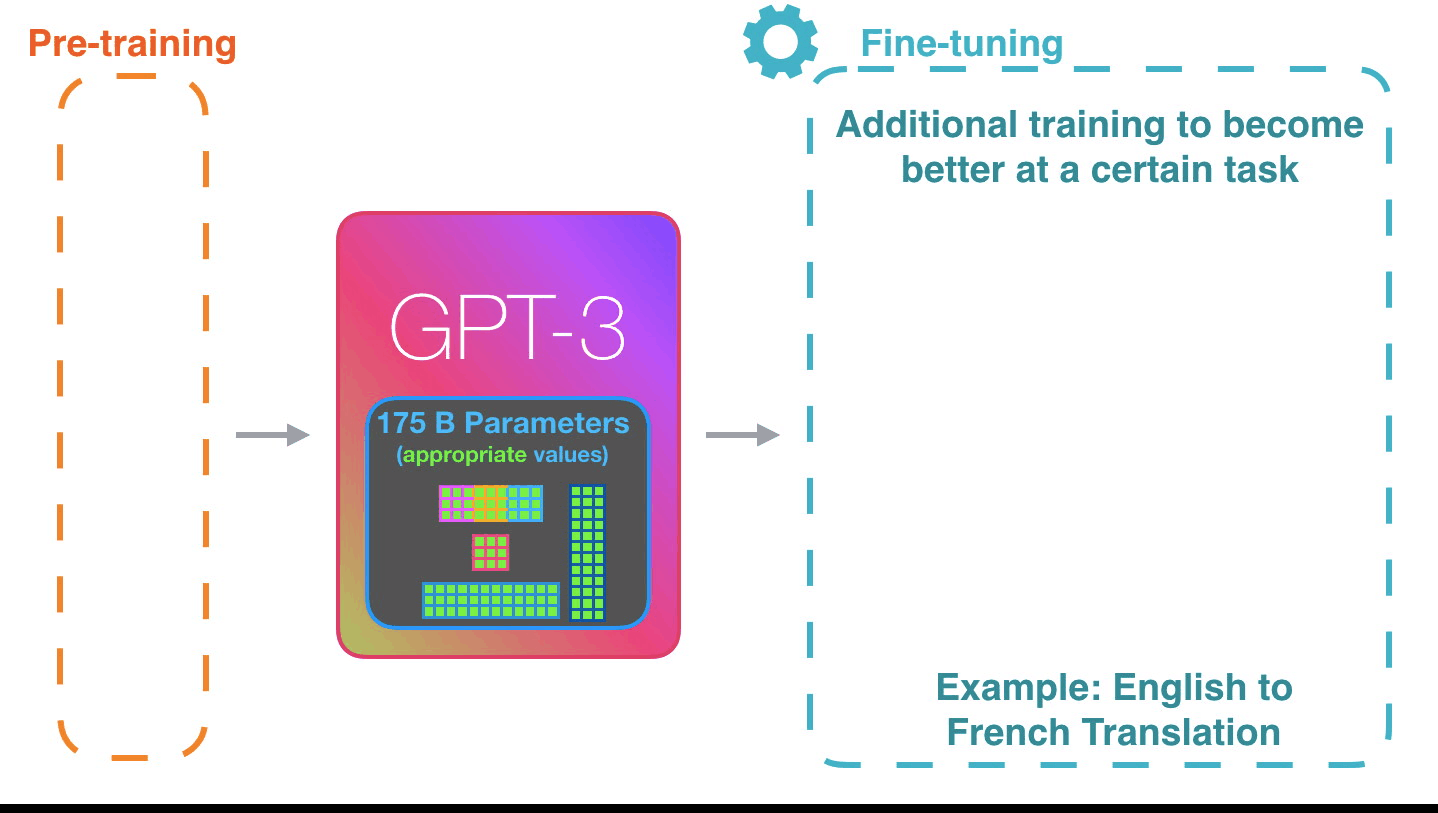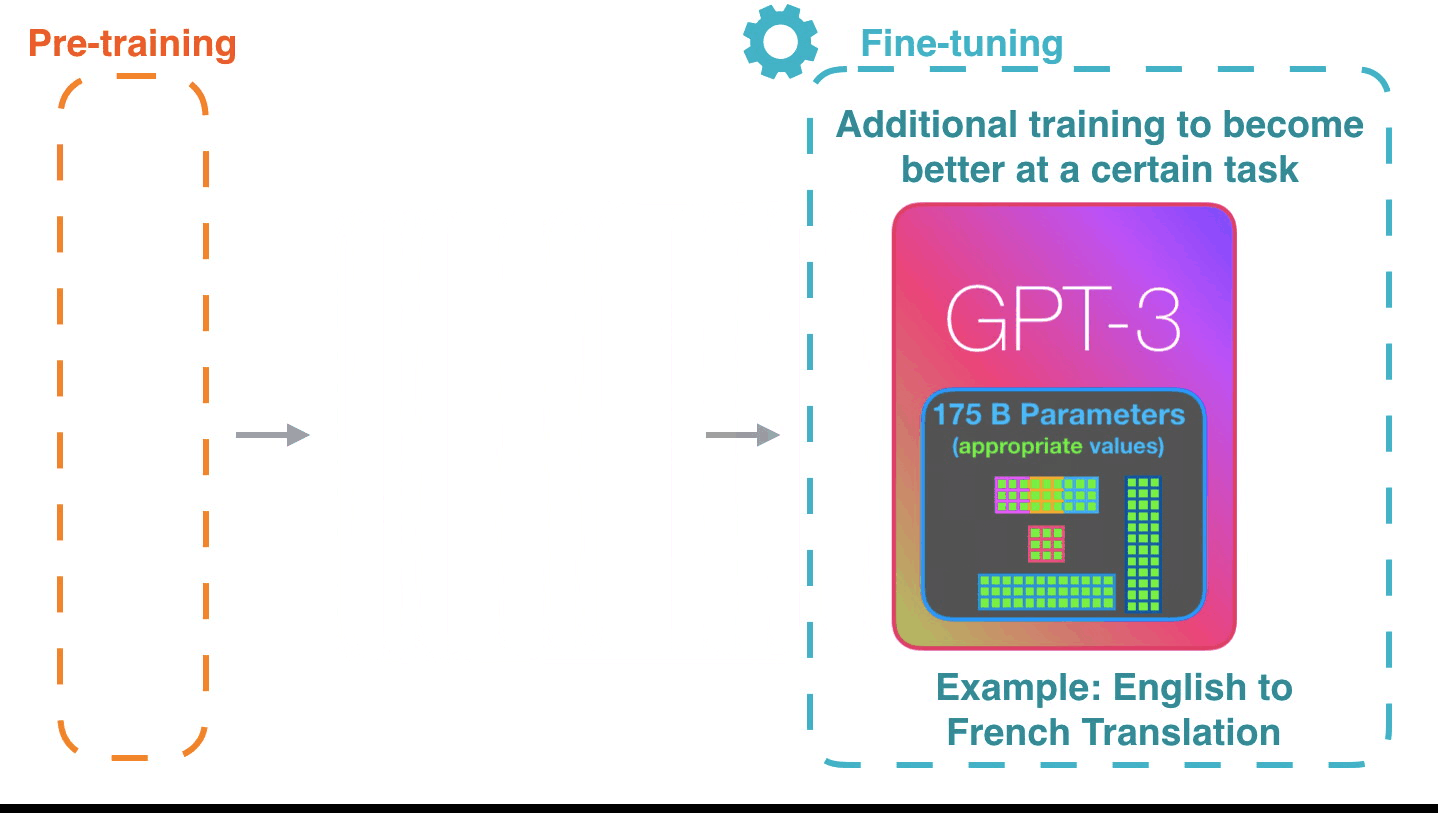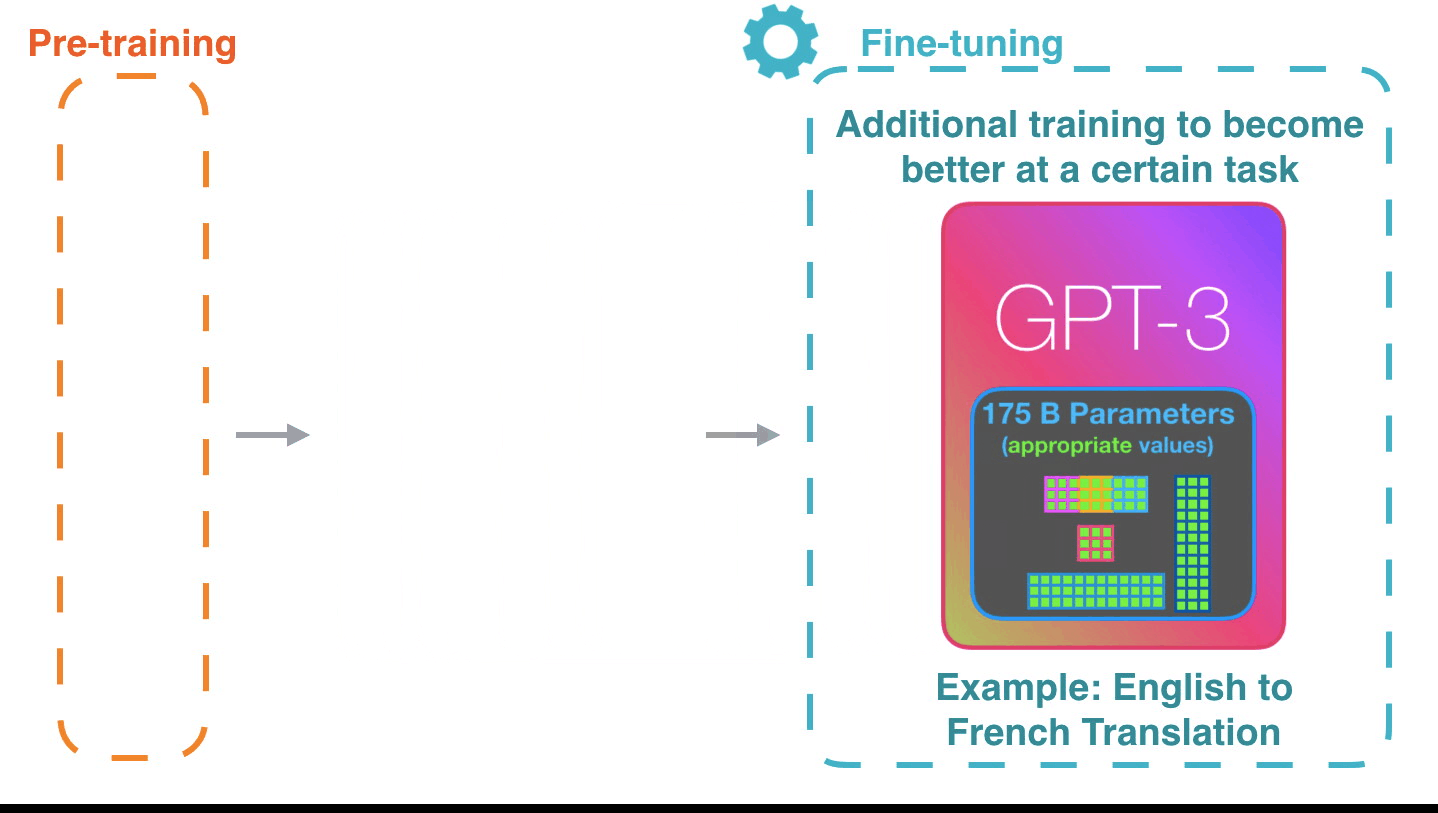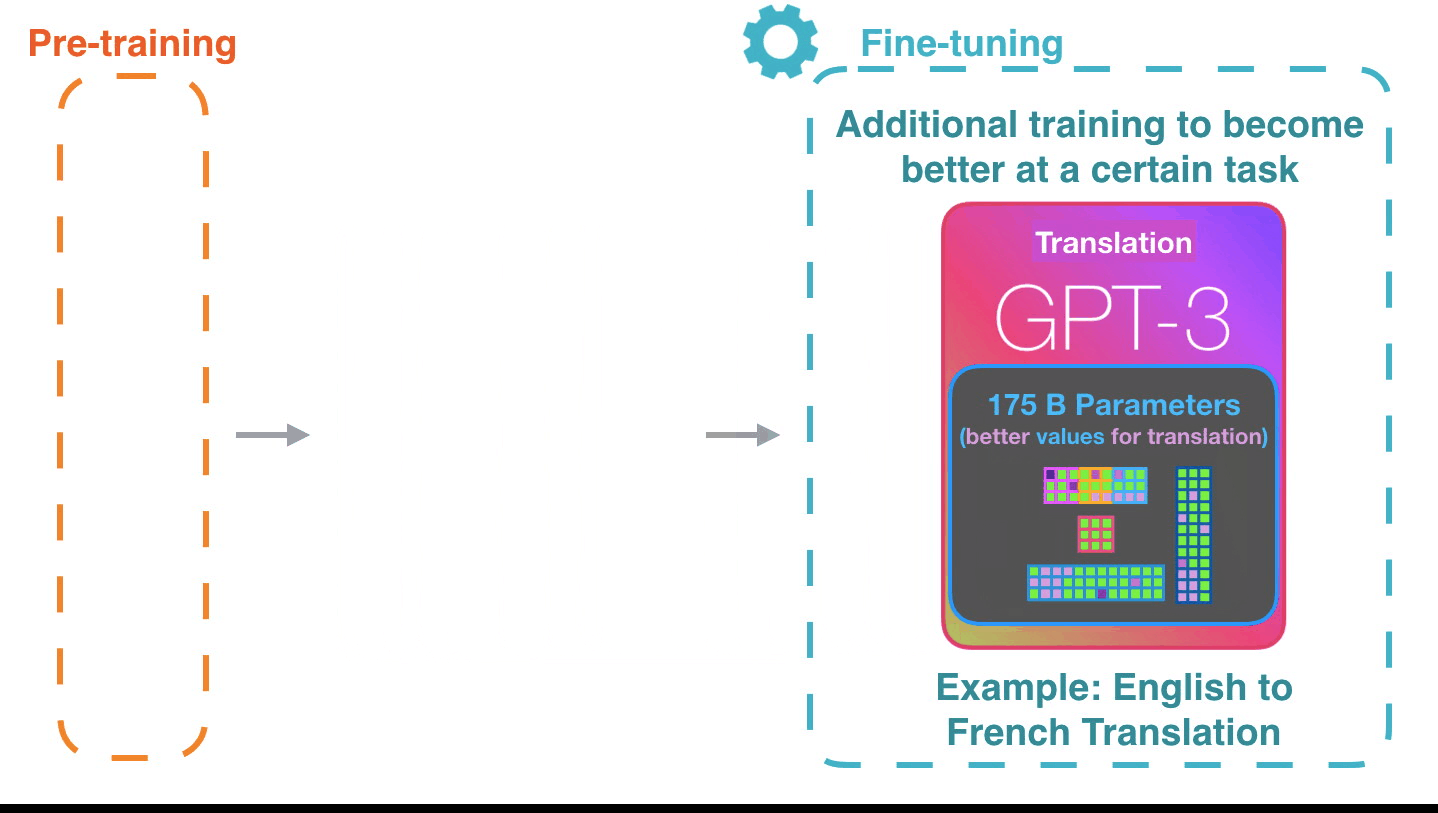
It’s impressive that this works like this. Because you just wait until fine-tuning is rolled out for the GPT3. The possibilities will be even more amazing.令人印象深刻的是,它是这样工作的。因为您只需等到 GPT3 推出微调。可能性将更加惊人。
Fine-tuning actually updates the model’s weights to make the model better at a certain task.微调实际上是更新模型的权重,使模型在某个任务上表现更好。
Written on July 27, 2020 写于 2020 年 7 月 27 日
相关文章




关于作者

猜你喜欢
成员 网址收录40405 企业收录2984 印章生成241717 电子证书1079 电子名片61 自媒体64547































