机器之心编译
作者:Jay Alammar
编辑:张倩、蛋酱
构建越来越大的模型并不是提高性能的唯一方法。
从 BERT 到 GPT-2 再到 GPT-3,大模型的规模是一路看涨,表现也越来越惊艳。增大模型规模已经被证明是一条可行的改进路径,而且 DeepMind 前段时间的一些研究表明:这条路还没有走到头,继续增大模型依然有着可观的收益。
但与此同时,我们也知道,增大模型可能并不是提升性能的唯一路径,前段时间的几个研究也证明了这一点。其中比较有代表性的研究要数 DeepMind 的 RETRO Transformer 和 OpenAI 的 WebGPT。这两项研究表明,如果我们用一种搜索 / 查询信息的方式来增强模型,小一点的生成语言模型也能达到之前大模型才能达到的性能。
在大模型一统天下的今天,这类研究显得非常难能可贵。
在这篇文章中,擅长机器学习可视化的知名博客作者 Jay Alammar 详细分析了 DeepMind 的 RETRO(Retrieval-Enhanced TRansfOrmer)模型。该模型与 GPT-3 性能相当,但参数量仅为 GPT-3 的 4%。

检索到的近邻被添加到语言模型的输入中。然而,它们在模型内部的处理方式略有不同。
高层次的 RETRO 架构
RETRO 的架构由一个编码器堆栈和一个解码器堆栈组成。
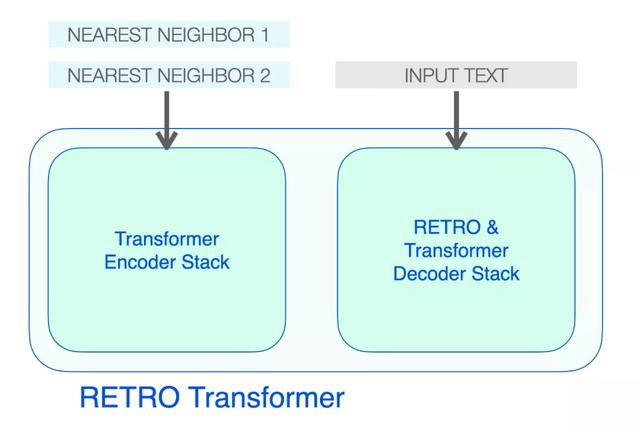
RETRO Transformer 由一个编码器堆栈(处理近邻)和一个解码器堆栈(处理输入)组成
编码器由标准的 Transformer 编码器块(self-attention FFNN)组成。Retro 使用由两个 Transformer 编码器块组成的编码器。
解码器堆栈包含了两种解码器 block:
标准 Transformer 解码器块(ATTN FFNN)RETRO 解码器块(ATTN Chunked cross attention (CCA) FFNN)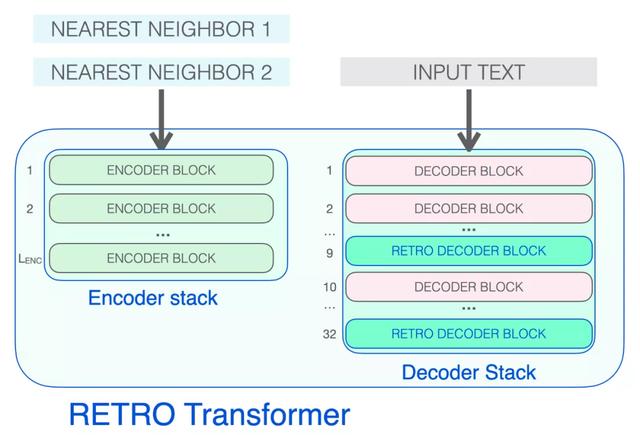
下图展示了检索到的信息可以浏览完成提示所需的节点步骤。
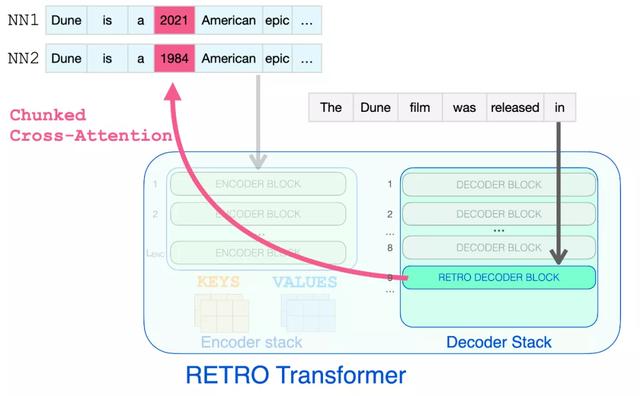
原文链接:http://jalammar.github.io/illustrated-retrieval-transformer/
相关文章









关于作者

猜你喜欢
成员 网址收录40387 企业收录2981 印章生成232077 电子证书1026 电子名片60 自媒体46877































