
智东西
编译 | 吴菲凝
编辑 | 李水青
智东西4月20日报道,开发出AI图像生成工具Stable Diffusion的初创公司Stability AI发布并开源该团队训练的大语言模型StableLM。该模型的Alpha版本有30亿和70亿个参数,接下来还将推出150亿至650亿参数的模型。用户已经可以从GitHub等开源平台上下载StableLM。

由Stable Diffusion绘制的图像
此次通过推出StableLM模型套件,Stability AI旨在展示一款小型、高效的模型如何通过适当的训练来提高自己的性能,该模型也代表着所有人都将使用上基础AI技术,公司以文本、图像等多种方式对其进行训练。
与其竞争对手ChatGPT一样,StableLM旨在有效地生成文本和代码。StableLM的发布建立在非营利性研究中心EleutherAI开源早期语言模型的基础之上。
Stability AI在开源早期语言模型方面经验丰富,曾经发布过GPT-J,GPT-NeoX和Pythia套件,这些模型都是在The Pile开源数据集上进行训练的。
今日发布的StableLM在更大版本的开源数据集The Pile上进行训练,该数据集包含来自各种来源的信息,包括维基百科(Wikipedia)、问答网站Stack Exchange和生物医学数据库PubMed,该数据集的规模是The Pile的三倍,包含1.5万亿个tokens(字符),其超大规模使得StableLM在会话和编码上具有超高性能,但是它目前只有30-70亿个参数,而GPT-3有1750亿个参数。
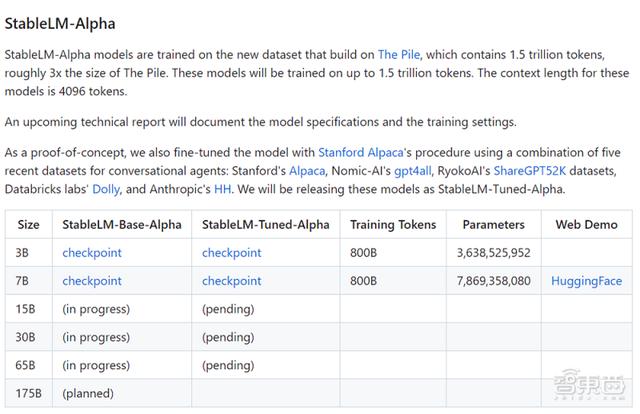
与Meta的LLaMA语言模型相比,StableLM模型在1亿个tokens上针对7亿个参数进行了训练。
在公司官网发布的《Stability AI Launches the First of its StableLM Suite of Language Models》这篇文章中,Stability AI还宣布StableLM套件包括一组经过指令微调的研究模型,使用了5个最近的开源数据集组合进行对话代理,包括斯坦福大学的Alpaca,Nomic-AI的GPT-4all,RyokoAI的ShareGPT52K数据集、Databricks实验室的Dolly和AI初创公司Anthropic的HH,并将发布这些模型作为StableLM-Tuned-Alpha版本,公司用斯坦福大学的Alpaca模型进行了微调。
二、聊天、写小说、编代码,ChatGPT会的它都会据Stability AI官网称,语言模型是数字经济的支柱,每个人都应该为自己的设计发言。通过提供对模型的细粒度访问,公司希望鼓励可解释性和安全性技术的发展,超越封闭模型所能达到的范围。该公司的模型现已在其GitHub存储库中开源,公司还补充,完整的技术报告中记录了模型的规格和训练设置数据,将会在不久的将来发布。
以下是StableLM模型在一些具体场景下的使用效果:
1、聊天

3、创作

Stability AI也在寻求发展其团队,并正在寻找在LLM方面经验丰富的个人,有相关经验的开发者可以在公司官网上申请加入团队。
除了StableLM套件的发布,Stability AI还启动了RLHF计划,并与Open Assistant等社区合作,创建开源AI助手数据集。该公司表示未来将发布更多模型,并称很高兴与开发人员和研究人员合作,推出StableLM套件。
结语:大模型不断涌现,“小而美”也能实现多功能在GitHub演示中,StableLM已展示出日常聊天、书信撰写、小说创作、代码编写等功能,或许在未来进一步的训练下,StableLM能将自己的功能反哺给Stable Diffusion,形成一个完整的AI生态闭环,并在Stability AI成熟的技术支持和丰富的开源项目经验下,让“小而美”模型也能实现多场景、多功能应用。
Stability AI自去年8月发布AI图像模型Stable Diffusion以来,在AIGC领域备受关注,公司市值随之水涨船高。据知情人士透露,今年3月开始新一轮融资后,公司估值将达40亿美元。此次新模型的推出或将再助Stability AI融资一臂之力。
来源:GitHub、Stability AI、The Verge、VentureBeat
相关文章







关于作者

猜你喜欢































