机器之心发布
机器之心编辑部
元语智能的功能型对话大模型 ChatYuan「既泛又专」,除了问答、上下文对话以及创意性写作等各类自然语言理解和生成任务之外,还能回答法律、医疗等专业领域的问答,并且写代码功能也已经在内测中,不久即将发布。特别提醒,本文中有部分文本由「ChatYuan」生成,请君细心分辨。
ChatGPT 到底有多火?它已成为史上最快传播的应用,发布两个月后就有了 1 亿用户。实现同样的用户量,TikTok 需要近九个月,而 Instagram 用了两年多。
未来几年,微软将继续增加投资 ChatGPT 背后的公司 OpenAI 100 亿美金,而 Google 也于近日投资了另外一个同类公司 Anthropic 将近 4 亿美金,在硅谷科技圈和资本市场成为了 2023 年最令人兴奋的科技进展。微软联合创始人比尔盖茨判断,ChatGPT 的历史意义重大,不亚于 PC 或互联网诞生。
国内在这次 AI 变革的浪潮中同样反应热烈,其中就有国内通用人工智能初创公司元语智能,推出国内首个基于大模型的功能型对话产品 ChatYuan。
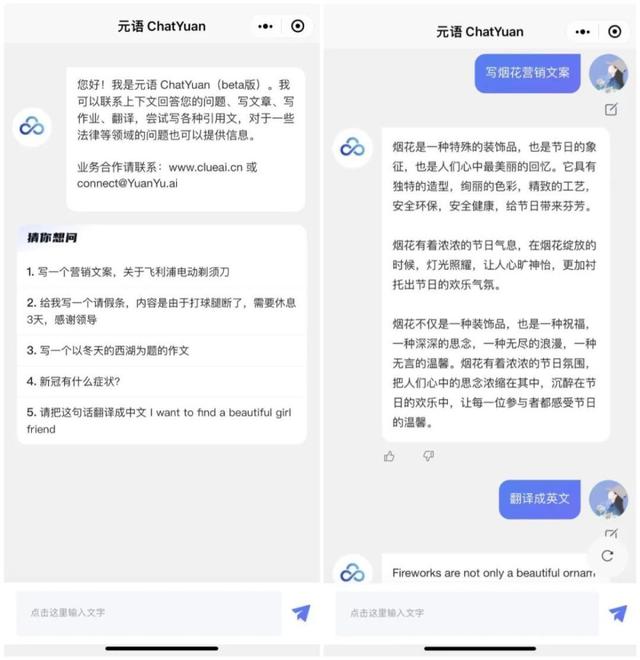
ChatYuan 产品样例
PromptCLUE 全中文任务零样本学习模型
在正式介绍元语智能的功能型对话大模型 ChatYuan 之前,我们先了解一下大规模多任务 Prompt 预训练中文开源模型——PromptCLUE,它实现了中文上的三大统一:统一模型框架、统一任务形式和统一应用方式。
PromptCLUE 在千亿中文 token 上大规模预训练,累计学习 1.5 万亿中文 token,在亿级中文任务数据上完成训练,并训练数百种任务集。它具有更好的理解、生成和抽取能力,并且支持文本改写、纠错、知识图谱问答等。
PromptCLUE 支持几十个不同类型的任务,具有较好的零样本学习能力和少样本学习能力。针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对生成任务,可以进行采样自由生成。
技术亮点
首个全中文任务支持的零样本学习的开源模型;自动化高质量数据处理算法,产出海量高质量无监督和有监督数据用于训练;基于高质量数据构建更加符合中文习惯的字典并从零训练中文大模型,模型性能效果更有保证;融合多种训练策略训练大模型,具备在中文上强大的泛化、迁移和生成能力。ChatYuan 功能对话开源大模型
就其功能而言,ChatYuan 可以用于问答、结合上下文做对话、做各种生成任务(包括创意性写作),也能回答一些像法律、医疗等领域问题。ChatYuan 线上服务是基于百亿参数大模型,目前已开源了 7.7 亿的参数模型,显存 6G 左右,一张民用显卡即可加载使用。后续会陆续开源更多、更大参数量的版本。
ChatYuan 基于 PromptCLUE 结合数亿条功能对话多轮对话数据进一步训练得到,它去掉了文本理解、信息抽取类任务,加强了问答、对话和各种生成式任务的学习和训练;针对多轮对话容易受到上下文的干扰,加入了抗干扰数据使得模型可以在必要时忽略无关的上下文;加入了用户反馈数据的学习,对齐人类意图,使得模型不仅具有一定的通用语言理解能力、特定任务上的生成能力,也能更好地响应用户的意图。
技术亮点
基于从零训练的全中文任务支持零样本学习模型 PromptCLUE 进一步迭代获取。在中文领域首创了功能对话形式支持全中文任务,支持自由输入。结合人类反馈的方法进行学习,对齐人类意图。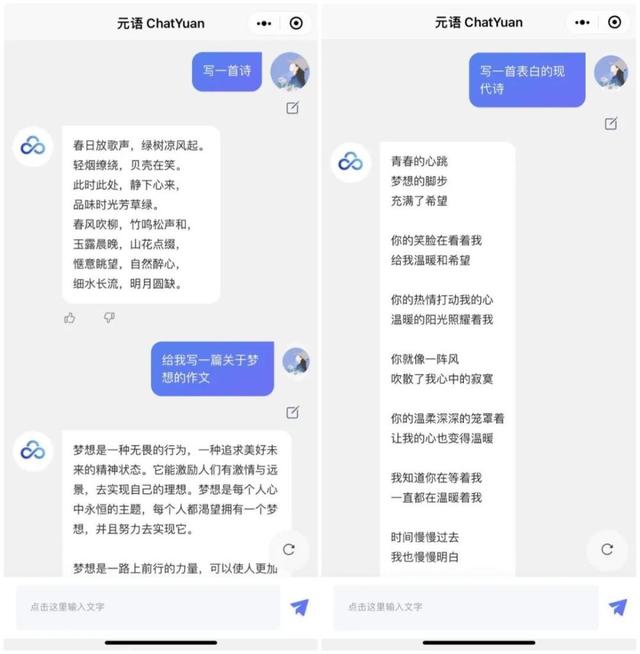 人力、算力方面的资源瓶颈。国内行业内相对来说更缺乏耐心,在未见到明确收益前持续投入不足,资本也同时缺乏耐心。中文高质量的数据积累不足,国内开源开放的生态相对薄弱。对 AI 未来趋势的前瞻性判断不足,缺少具有坚定信仰的引领者。行业对 AGI 创业公司信心不足,对于 AGI 价值的共识不够。
人力、算力方面的资源瓶颈。国内行业内相对来说更缺乏耐心,在未见到明确收益前持续投入不足,资本也同时缺乏耐心。中文高质量的数据积累不足,国内开源开放的生态相对薄弱。对 AI 未来趋势的前瞻性判断不足,缺少具有坚定信仰的引领者。行业对 AGI 创业公司信心不足,对于 AGI 价值的共识不够。未来愿景
因此,元语智能作为国内第一个勇敢前行的初创公司,并坚定通用人工智能(AGI)将普惠人类的信仰,给了国内通用人工智能行业从业者非常大的信心。
同时,元语智能强烈呼吁:国内从事人工智能研究的同行、长期关注科技行业的资本以及各行各业对 AGI 感兴趣的朋友,要共同有耐心、有信心的坚持下去。他山之石,可以攻玉,但我山之石将会持之以恒。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成241489 电子证书1076 电子名片60 自媒体64547































