编译 | 屠敏
出品 | CSDN(ID:CSDNnews)
当昨日我们还在讨论从大厂以及个人创业的角度来看,复制一家 OpenAI 和一款强大的 ChatGPT 可行性究竟有几成之际,苦于 OpenAI 并未将 ChatGPT 开源出来,所以这趟水究竟有多深,众人并不知。
不过,2 月 14 日情人节这一天,来自加州大学伯克利分校的教授 James Demmel 和新加坡国立大学计算机系的校长青年教授尤洋及其背后的研究团队悄悄提供了一些答案,其率先呈现了一个开源的低成本 ChatGPT 等效实现流程,瞬间吸引无数 AI 爱好者的目光。
话不多说,简单来看,只需实现如下图所示的三步走,便能实现:
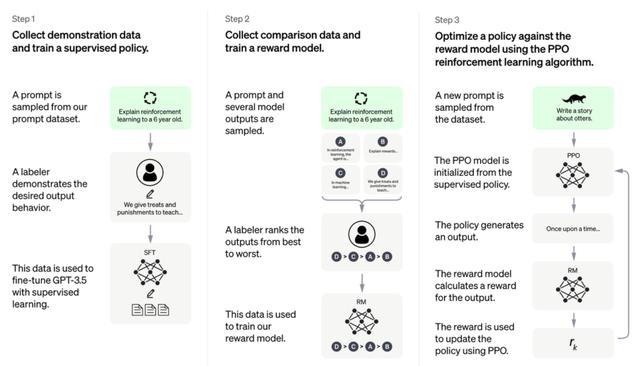
当然,等不及的小伙伴现在可以直接通过 GitHub 地址了解详情:https: //github.com/hpcaitech/ColossalAI

使用以下命令,开发者可以快速启动单 GPU 规模、单机多 GPU 规模、原始 1750 亿参数规模版本的训练,并对各种性能指标(包括最大GPU内存使用率、吞吐量和TFLOPS)进行评估。
# Training GPT2-S using a single card, a minimum batch size, Colossal-AI Gemini CPU strategytorchrun --standalone --nproc_pero_node 1 benchmark_gpt_dummy.py --model s --strategy colossalai_gemini_cpu --experience_batch_size 1 --train_batch_size 1# Training GPT2-XL with a 4-GPU machine, Colossal-AI Zero2 strategytorchrun --standalone --nproc_per_node 4 benchmark_gpt_dummy.py --model xl --strategy colossalai_zero2# Training GPT-3 with 4 8-GPU servers, Colossal-AI Gemini CPU strategytorchrun --nnodes 4 --nproc_per_node 8 --rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR benchmark_gpt_dummy.py --model 175b --strategy colossalai_gemini_cpu --experience_batch_size 1 --train_batch_size 1
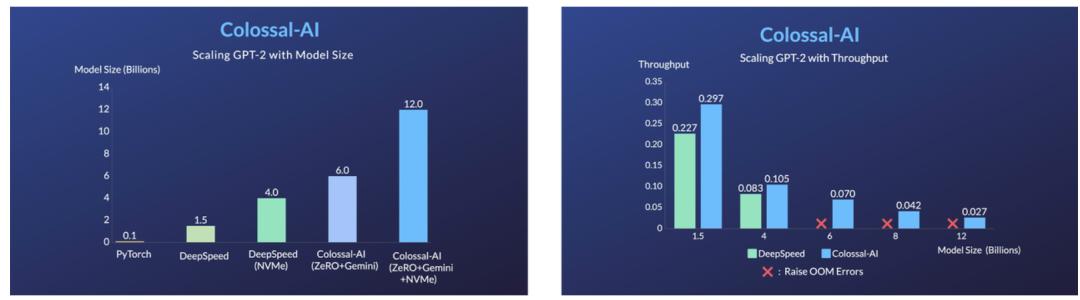
此外,Colossal-AI 的异构内存管理器 Gemini 通过将优化器状态卸载到 CPU ,以此减少 GPU 内存占用,允许同时使用 GPU 内存和 CPU 内存(包括 CPU DRAM 或 NVMe SSD 内存)来训练超出单个 GPU 内存限制的大规模模型。
写在最后
目前,该研究团队已经开源了完整的算法和软件设计来复制 ChatGPT 的实现过程:https://github.com/hpcaitech/ColossalAI。
不过,同样是基于成本考虑,他们表示,「对于这样一个巨型的人工智能模型,它需要更多的数据和计算资源来实际生效和部署。毕竟,用 1750 亿个参数训练一个 GPT-3 需要价值数百万美元的计算能力。因此,大型预训练模型长期以来只为少数大科技公司所拥有。」
因此,他们也希望能够以开源的方式,吸引更多的研究人员、机构共同参与进来,仅以上文中所复制 ChatGPT 训练流程的实践探索为起点,未来可以向大模型的时代做出努力。
更多详情内容可查阅官方公告:https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
参考资料:
https://twitter.com/ArtificialAva/status/1623346998928723971
https://arxiv.org/abs/2106.09685
https://arxiv.org/pdf/2203.02155
https://openai.com/blog/chatgpt/
相关文章








关于作者

猜你喜欢































