
文|许档 编| 展洋
出品|商业秀
现如今,只要ChatGPT一有任何风吹草动,就会马上搅动国内外各大科技公司、投资人和创业公司的心。
北京时间3月15日的凌晨,OpenAI有了新突破。在经历了多次迭代和改进升级后,OpenAI重磅发布了更为强大的版本GPT-4。而且,这个版本的具备强大的识图能力,文字输入限制也提升至2.5万字;甚至可以支持文字和图片的混合输入。
此外,GPT-4的回答在准确性层面也显著提升,还能够生成歌词、创意文本从而实现风格变化。同时,GPT-4在各类专业测试及学术基准上也表现优良。
这操作,相当于深夜扔出了一个炸弹,让国内外的ChatGPT迷们为之惊叹。
就连猎豹移动董事长兼CEO、猎户星空董事长傅盛都在凌晨发布视频惊呼:“真的是太恐怖了!你说我们人类还学什么呢?它一个人工智能模型就能考出这样的分数,这才是它刚刚开始啊!哎,人类的教育该何去何从呢?说实话,我都有点迷茫了!”
随后傅盛称,自己只是刚刚使用,但他想告诉大家,“GPT-4非常非常恐怖,是整个世界的生产力变革。但不论如何,一个技术浪潮的来临,只有先拥抱,所有的人都应该去关心新的AI,新的ChatGPT-4。”
这种所谓的“恐怖”,一幕幕惊叹,感觉又是人类再次被AI碾压的一天。这很难不让人想起2016年往事:谷歌旗下的DeepMind团队向李世石九段,发起了围棋五番棋挑战并轻松获胜。
AI机器人“阿尔法狗”(AlphaGo)及其继任者,尚且全面碾压人类棋手。何况,迭代之后似乎无所不能的ChatGPT-4。
但人类在惊叹“恐怖”的同时,似乎也忘记了一点:人工智能有Bug,也会犯错,或大或小,像极了人类。
ChatGPT更是如此,即便饲喂了如此多的数据,迭代了如此多的版本,OpenAI也还是表示:GPT-4仍旧会产生幻觉、生成错误答案,出现推理性错误。
更值得玩味的是,OpenAI发布GPT-4的节点甚为有趣,因为国内的科技公司百度将于明天(3月16日)对外发布文心一言,外界对此极为期待。
01 所谓“震撼”
根据OpenAI的介绍,它是一个大型多模态模型,能接受图像和文本输入,再输出正确的文本回复。
但关于GPT-4,已经有多家媒体把它吹爆了。毋庸置疑,没有对比就没有伤害。和ChatGPT-3.5相比,确实强大了不少。
GPT-4实现了以下几个方面的飞跃式提升:强大的识图能力;文字输入限值提升至2.5万字;回答准确性显著提高;能够生成歌词、创意文本,实现风格变化。
比如在日常对话中,GPT-4与GPT-3.5之间的差距或许微妙。但当任务的复杂度足够高,差异就会很明显,GPT-4就表现出更可靠、更具创造性,还能能处理更细致的指令。
根据OpenAI公布的实验数据,GPT-4在各种专业测试和学术基准上的表现与人类水平相当。比如,它通过了模拟律师考试,且分数在应试者的前10% 左右;相比之下,GPT-3.5的得分在倒数10% 左右。
但相较于此前的GPT模型而言,GPT-4最大的突破之一是在文本之外还能够处理图像内容。OpenAI表示,用户同时输入文本和图像的情况下,它能够生成自然语言和代码等文本。
目前在官网上,OpenAI已经给出了一系列相关案例。例如,在GPT-4输入图片并设问“这些图片有何可笑之处?详细描述一下。”

GPT-4在 TruthfulQA 等外部基准测试方面也取得了进展,OpenAI 测试了模型将事实与错误陈述的对抗性选择区分开的能力,结果如下图所示。
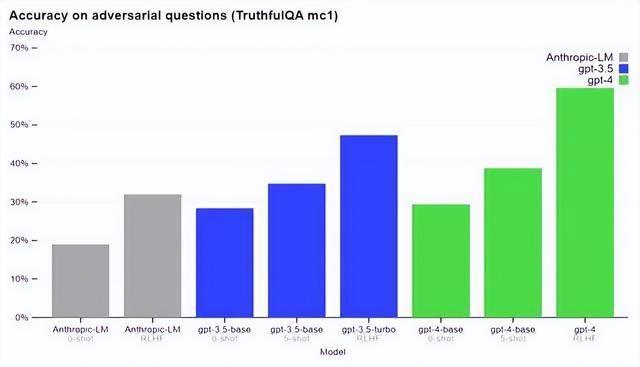
实验结果表明,GPT-4基本模型在此任务上仅比 GPT-3.5略好;然而,在经过 RLHF 后训练之后,二者的差距就很大了。以下是 GPT-4的测试示例 —— 并不是所有时候它都能做出正确的选择。

该模型在其输出中可能会有各种偏见,OpenAI 在这些方面已经取得了进展,目标是使建立的人工智能系统具有合理的默认行为,以反映广泛的用户价值观。
GPT-4通常缺乏对其绝大部分数据截止后(2021年9月)发生的事件的了解,也不会从其经验中学习。它有时会犯一些简单的推理错误,这似乎与这么多领域的能力不相符,或者过于轻信用户的明显虚假陈述。有时它也会像人类一样在困难的问题上失败,比如在它生成的代码中引入安全漏洞。
GPT-4预测时也可能出错但很自信,意识到可能出错时也不会 double-check。有趣的是,基础预训练模型经过高度校准(其对答案的预测置信度通常与正确概率相匹配)。然而,通过 OpenAI 目前的后训练(post-training)过程,校准减少了。
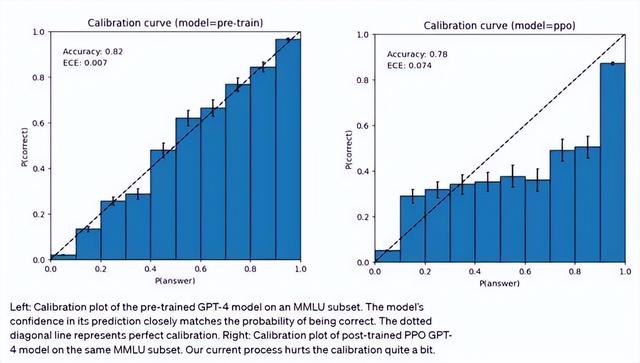
同时,与早期GPT模型类似,GPT-4也具备局限性。GPT-4依然会形成推理错误,因而在使用语言模型输出时需要非常小心,最好以人工核查、附加上下文或避免高风险使用的方式予以辅助。
“GPT4的模型发布,本身是技术持续升级迭代发展的必然阶段。AI行业每一年都会有些新模型发布,趋势就是大模型、多模态。”
在接受21世纪经济报道记者采访时,IDC中国研究总监卢言霞表示,“多模态肯定是必然趋势,毕竟AI要真正达到人的智慧,需要处理多模数据。且在各行业场景里,大都是涉及多模态数据的处理。”
03 担忧与接受
对于ChatGPT,人类一直担心的是,对于超出安全边界和敏感的问题,怎么去训练和规避以及提升它的安全性能?
OpenAI 表示,与之前的 GPT 模型一样,GPT-4基础模型经过训练可以预测文档中的下一个单词。OpenAI 使用公开可用的数据(例如互联网数据)以及已获得许可的数据进行训练。
训练数据是一个网络规模的数据语料库,包括数学问题的正确和错误解决方案、弱推理和强推理、自相矛盾和一致的陈述,以及各种各样的意识形态和想法。
因此,当提出问题时,基础模型的回应可能与用户的意图相去甚远。为了使其与用户意图保持一致,OpenAI 依然使用强化学习人类反馈 (RLHF) 来微调模型的行为。而该模型的能力似乎主要来自预训练过程 ——RLHF 不会提高考试成绩(甚至可能会降低它)。但是模型的控制来自后训练过程 —— 基础模型甚至需要及时的工程设计来回答问题。
关于风险和安全,OpenAI 研究团队称,一直在对 GPT-4进行迭代,使其从训练开始就更加安全和一致,所做的努力包括预训练数据的选择和过滤、评估和专家参与、模型安全改进以及监测和执行。
GPT-4有着与以前的模型类似的风险,如产生有害的建议、错误的代码或不准确的信息。
同时,GPT-4的额外能力导致了新的风险面。为了了解这些风险的程度,团队聘请了50多位来自人工智能对齐风险、网络安全、生物风险、信任和安全以及国际安全等领域的专家,对该模型在高风险领域的行为进行对抗性测试。这些领域需要专业知识来评估,来自这些专家的反馈和数据为缓解措施和模型的改进提供了依据。
或许更值得关注的问题是,人类的很多领域继续会被人工智能颠覆。在机器面前,人类似乎又渺小了不少。
《人类简史》的作者赫拉利总是在强调一项事实:人类并不是多么了不起的物种;人类之有今天,缘于各种生物和进化上的巧合,纯属狗屎运。
人类虽已拥有改变世界的技术能力,心智却严重落伍,他们在生理上与两万年前的祖先没有本质区别。甚至在全书结尾,赫拉利给人类下的判词是:“拥有神的能力,但是不负责任、贪得无厌,而且连想要什么都不知道。天下危险,恐怕莫此为甚。”
在不断迭代的新技术面前,无论人类有多少惊叹和担忧,首先都必须先选择:去接受,去拥抱,然后才是创造和改变。
「参考资料」
01 OpenAI 官网
02 GPT-4震撼发布:多模态大模型,直接升级ChatGPT、必应,开放API 来源:机器之心03 逐浪AIGC①丨OpenAI正式发布GPT-4 向超级AI进发? 来源:21世纪经济报道
04 刚刚,ChatGPT-4发布,全方位碾压老版本 来源:知危
相关文章






关于作者

猜你喜欢































