此文章由ChatGPT协助完成,成稿只用了半个小时左右。
前段时间ChatGPT引爆了AIGC领域,热度空前。随着时间的推移,关于ChatGPT的讨论逐渐减少了,回归理性,要想用好ChatGPT这类工具,你还需要了解这些内容。
 ChatGPT 会取代搜索引擎吗?
ChatGPT 会取代搜索引擎吗?人们经常会把谷歌、百度等搜索引擎拿来和 ChatGPT 进行比较。但是 ChatGPT 并不是一个搜索引擎。相对于传统的搜索引擎, ChatGPT 更像是一个智能助手,可以帮助用户获得有关某些主题的信息,并以对话的形式回答问题。它不仅提供了信息,而且还可以根据上下文理解用户的意图,回答相关的问题。 ChatGPT 提供了一种全新的、更人性化的信息获取体验,当然这种体验并不适用于所有应用场景。例如,搜索引擎能列出信息来源网址就是其一个优势。
下面就简单说明一下百度搜索引擎和 ChatGPT 的区别。
目的:百度引擎旨在帮助用户找到有关特定主题的信息。 ChatGPT 是一个语言模型,旨在生成文本内容并回答用户问题。
范围:百度搜索引擎涵盖了整个互联网,提供了丰富的信息。 ChatGPT 是基于训练数据,因此可能不能回答所有问题,但它可以根据上下文理解问题并提供有关信息。
准确性:百度搜索引擎通过爬取网页并使用排名算法提供搜索结果。它的结果通常是准确的。 ChatGPT 是基于机器学习和自然语言处理技术的,其结果的准确性取决于其训练数据的质量。
总的来说,百度搜索引擎是一个功能强大的工具,适用于大量信息的检索,而 ChatGPT 则是一个智能助手,适用于获取特定信息并以对话的形式回答问题。但是因为 ChatGPT 的良好互动性和获取信息的便捷性,所以被很多人认为是下一代搜索引擎的雏形。微软就顺势推出了集成了 ChatGPT 和传统搜索引擎为一体的新产品﹣﹣新版的必应( Bing ),谷歌推出的类似产品为 Bard 。
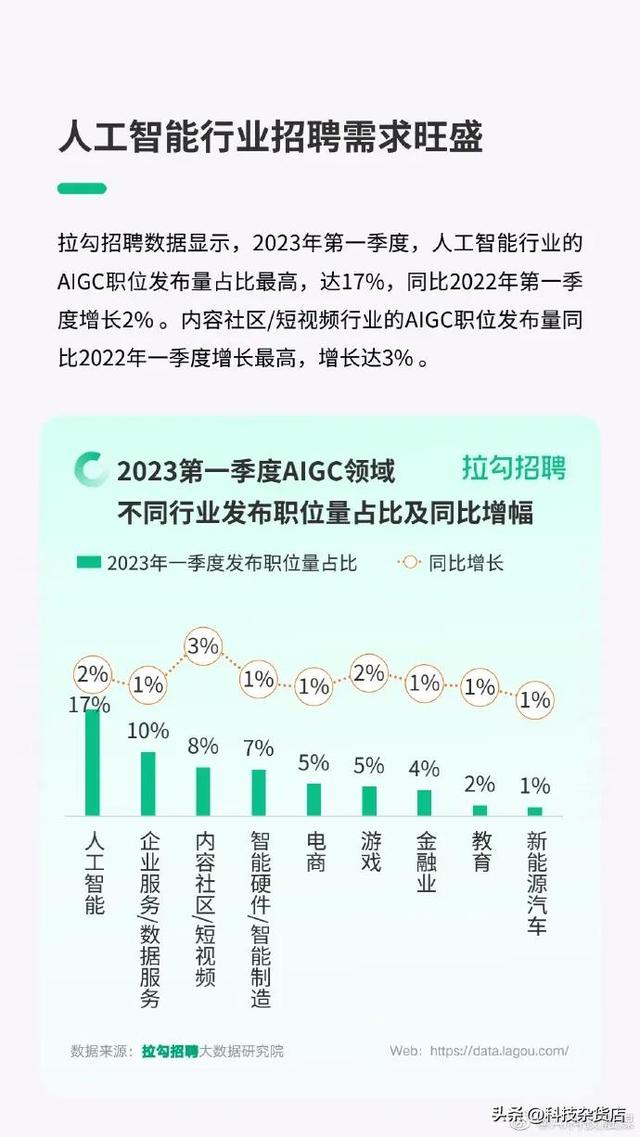 人类和 ChatGPT 对话次数越多, ChatGPT 是否越智能?
人类和 ChatGPT 对话次数越多, ChatGPT 是否越智能?并非如此。 ChatGPT 是一个预训练的自然语言处理模型,它在训练数据过程中学到了如何生成类似人类语言的回答。
与人类进行对话时,它是根据人类的输入从它已经学到的语言知识中生成回答。其智能水平取决于其训练数据和算法的优化程度,而不是通过对话的方式来直接增加其智能水平。但是人们与 ChatGPT 进行对话过程可以提高其"经验",即增加其对话质量和适应性。长期以后当 ChatGPT 面对更多的问题和场景时,它将学习到更多的语言和语境知识,从而更好地理解并回答问题。
人类会带偏 ChatGPT 吗?是的。由于 ChatGPT 的学习和表现是基于其预训练数据和算法得出的,它可能会受到人类提供的错误信息或有偏差的数据的影响,从而输出错误的答案或有偏见的言论。此外,如果 ChatGPT 的训练数据集本身就存在问题或存在偏见,那么 ChatGPT 在学习和输出过程中也可能会出现偏见或错误的现象。例如,有时它可能生成带有性别、种族、宗教等偏见的内容。
为了避免这种情况的发生, ChatGPT 的开发者和维护者应该对其训练数据和算法进行严格的监控和优化,确保其对话内容的准确性和中立性。同时,人们在与 ChatGPT 进行对话时,也需要提高自我意识和质疑精神,避免盲目接受 ChatGPT 的答案,从而最大限度地避免 ChatGPT 受到错误或有偏见信息的影响
ChatGPT 真的无所不能吗?ChatGPT 并非是无所不能的。前面提到过, ChatGPT 是一个通过大量语料库训练的预测模型,只是具有较强的自然语言处理能力。它能够完成一些复杂的任务,如生成文本、回答问题、对话等。但是, ChatGPT 仍然只是一个人工智能模型,其能力还有很多限制。例如,不能完全理解人类的意图,不能完全模拟人类的思维,不能做出全部正确的判断等。此外, ChatGPT 的表现质量也受到一些限制。例如,它可能无法处理某些领域的专业术语、文化习惯和地方口音等。同时, ChatGPT 也可能会出现一些语言和逻辑上的错误,尤其是面对复杂和抽象的问题时它仍然有局限性和错误的可能。
对同一个问题, ChatGPT 的回答是否都相同?有可能它的回答是相同的。前面讲解过, ChatGPT 的背后是一个生成式预训练模型,通过学习大量的语料数据训练得到的。它通过输入上下文和对问题的解释,来生成可读的、自然的、相关的文字。如果输入的问题和语料库中的文字非常相似,那么生成的文字也很可能非常相似。同时,它还受到它所被训练的语料数据的限制,如果语料库中没有该问题的相关信息, GPT -3将不能生成出符合该问题的回答。
假如有10000个人同时对 ChatGPT 提出同样的一个开放性问题,如果生成的答案大部分相同,那么这主要是因为语料中已有类似的信息,且输入的问题是相同的。不过,因为ChatGPT是一个随机生成的模型,所以生成的答案完全相同的能性比较小,只是说近似性会比较大。
下面看看 OpenAI 公司官网声明是如何描述这个问题的:
Terms of Use
3. Content
( b ) Similarity of Content . Due to the nature of machine learning , Output may not be unique across users and the Services may generate the same or similar output for OpenAl or a third party . For example , you may provide input to a model such as " What color is the sky ?" and receive output such as " The sky is blue ." Other users may also ask similar questions and receive the same response . Responses that are requested by and generated for other
users are not considered your Content .
中文含义为:
使用条款
3.内容
( b )内容的相似性。由于机器学习的性质,输出在用户之间可能不是唯一的,服务可能会为 OpenAI 或第三方生成相同或相似的输出。例如,你可以向模型提供输入,例如"天空是什么颜色?”,并接收输出,例如"天空是蓝色的”。其他用户也可能提出类似的问题并收到相同的回复。其他用户请求和生成的响应不被视为你的内容。
ChatGPT 是通过英汉互译来实现中文回答的吗?不是。 ChatGPT 是一个多语言的语言生成模型,可以直接对中文输人生成中文输出。它是通过学习大量的语料数据来训练模型,并利用语言模型的方法来生成文本。因此,不需要将中文文本翻译为英文再生成中文的文本。
同一个问题,为什么中英文回答不同?这是因为对于 ChatGPT 来说不同语种的语料库是不同的。例如,英语语料库中的数据通常比中文语料库中的数据更丰富和多样化,所以英语回答的信息量可能比中文回答的信息量更多。因此,同一个问题的回答在英语和中文中可能会有所不同。
相关文章






关于作者

猜你喜欢































