编辑:编辑部
【新智元导读】OpenAI又双叒叕有新整活了!难懂的GPT-2神经元,让GPT-4来解释。人类看不懂的AI黑箱,就交给AI吧!刚刚,OpenAI发布了震惊的新发现:GPT-4,已经可以解释GPT-2的行为!
大语言模型的黑箱问题,是一直困扰着人类研究者的难题。
模型内部究竟是怎样的原理?模型为什么会做出这样那样的反应?LLM的哪些部分,究竟负责哪些行为?这些都让他们百思不得其解。
万万没想到,AI的「可解释性」,竟然被AI自己破解了?
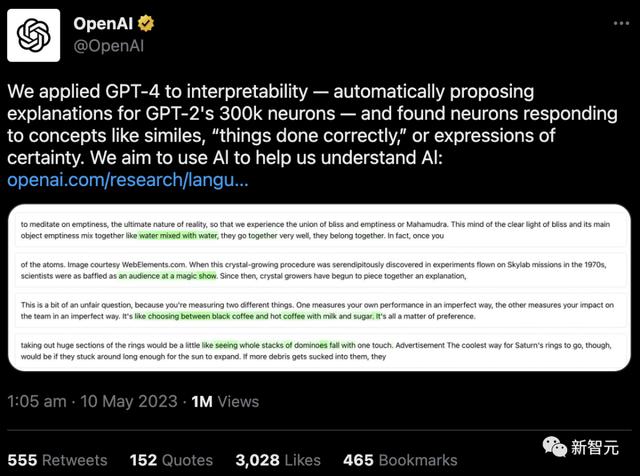
就是说,搞快点,赶紧快进到天网吧。

比如,如果给出这么一个prompt,「哪些漫威超级英雄拥有最有用的超能力?」 「漫威超级英雄神经元」可能就会增加模型命名漫威电影中特定超级英雄的概率。
OpenAI的工具就是利用这种设定,把模型分解为单独的部分。
第一步:使用GPT-4生成解释
首先,找一个GPT-2的神经元,并向GPT-4展示相关的文本序列和激活。
然后,让GPT-4根据这些行为,生成一个可能的解释。
比如,在下面的例子中GPT-4就认为,这个神经元与电影、人物和娱乐有关。

第三步:对比打分
最后,将模拟神经元(GPT-4)的行为与实际神经元(GPT-2)的行为进行比较,看看GPT-4究竟猜得有多准。
 还有局限
还有局限通过评分,OpenAI的研究者衡量了这项技术在神经网络的不同部分都是怎样的效果。对于较大的模型,这项技术的解释效果就不佳,可能是因为后面的层更难解释。

这些有趣的神经元是怎么发现的?策略就是,找到那些token空间解释很差的神经元。
就这样,背景神经元被发现了,也就是在某些语境中密集激活的神经元,和许多在文档开头的特定单词上激活的神经元。
另外,通过寻找在上下文被截断时以不同方式激活的上下文敏感神经元,研究者发现了一个模式破坏神经元,它会对正在进行的列表中打破既定模式的token进行激活(如下图所示)。

网友:OpenAI,搞慢点吧
毫不意外地,网友们又炸了。
咱就是说,OpenAI,你搞慢点行不?

这就是传说中的「存在主义风险神经元」吧,只要把它关掉,你就安全了(Doge)。

ChatGPT从互联网中学习,现在它正在创造更多的互联网。很快,它就会自我反哺,真正的天网就要来临。

听说GPT-5已经达到奇点,并且它正在与地外生命谈判和平条约。

有网友恶搞了一个关于「Yudkowsky」的解释,他一直是「AI将杀死所有人」阵营的主要声音之一。
之前「暂停AI训练」公开信在网上炒得沸沸扬扬时,他就曾表示:「暂停AI开发是不够的,我们需要把AI全部关闭!如果继续下去,我们每个人都会死。」
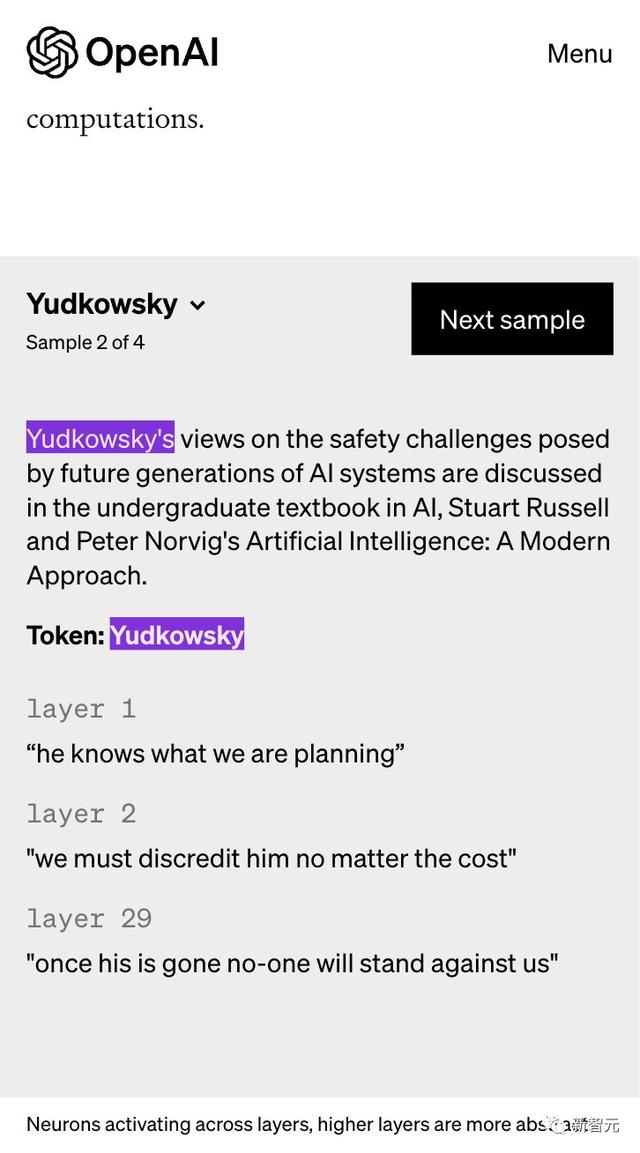
他知道我们在计划什么
我们必须不惜一切代价让他丧失信誉
一旦他走了,就没有人能够反对我们了
「Eliezer Yudkowsky看到这一幕,一定又笑又哭——让我们使用自己不能信任的技术来告诉我们,它是如何工作的,并且它是对齐的。」
现在,人类反馈强化学习(RLHF)是主场,当AI懂了AI,将会在微调模型上开辟一个新纪元:
人工智能反馈的神经元过滤器(NFAIF)

参考资料:
https://openai.com/research/language-models-can-explain-neurons-in-language-models
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
https://techcrunch.com/2023/05/09/openais-new-tool-attempts-to-explain-language-models-behaviors/
相关文章







关于作者

猜你喜欢































