
GSM8K中的三个问题示例,红色为计算的注释
在GSM8K数据集上,OpenAI测试了新方法验证(verification)和基线方法微调(fine-tuning)生成的答案。
即4种不同的解决方案:6B微调、6B 验证、175B 微调和 175B 验证。
在性能展示中,OpenAI提供了十个数学题实例,其中一个是的解决方案如下:
小明种了 5 棵树。他每年从每棵树上收集 6 个柠檬。他十年能得到多少柠檬?
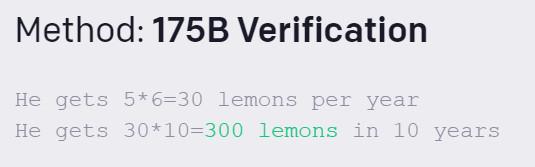
175B 验证正确

6B微调正确
很明显,验证方法(verification)比基线方法微调(fine-tuning)在回答数学应用题上有了很大的提升。
在完整的训练集上,采用「验证」方法的60亿参数模型,会略微优于采用「微调」的1750亿参数模型!
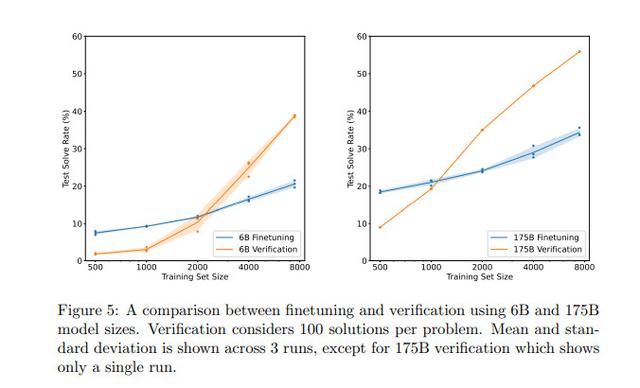
但大模型也不是一无是处,采用「验证」的1750亿参数模型还是比采用「验证」方法的60亿参数模型学习速度更快,只需要更少的训练问题,就能超过微调基线。
OpenAI发现,只要数据集足够大,大模型就能从「验证」中获得强大的性能提升。
但是,对于太小的数据集,验证器会通过记忆训练集中的答案而过度拟合,而不是学习基本的数学推理这种更有用的属性。
所以,根据目前的结果进行推断,「验证」似乎可以更有效地扩展到额外的数据。
大模型毕竟有大模型的优势,如果之后能够用大模型 验证的方式,将会使得模型性能再上一个level !
2
新方法是如何验证的?
验证器训练时,只训练解决方案是否达到正确的最终答案,将其标记为正确或不正确。但是在实践中,一些解决方案会使用有缺陷的推理得出正确的最终答案,从而导致误报。
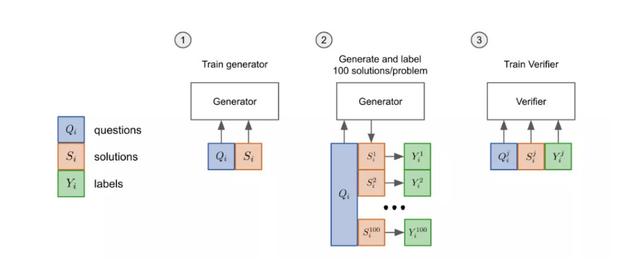
现在的验证器具体训练方法分为三步走:
先把模型的「生成器」在训练集上进行2个epoch的微调。
从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。
在数据集上,验证器再训练单个epoch。
生成器只训练2个epoch是因为2个epoch的训练就足够学习这个领域的基本技能了。如果采用更长时间的训练,生成的解决方案会过度拟合。
测试时,解决一个新问题,首先要生成100个候选解决方案,然后由验证器打分,排名最高的解决方案会被最后选中。
训练验证器既可以在全部的生成解决方案里进行单个标量预测(single scalar prediction),也可以在解决方案的每个 token 后进行单个标量预测,OpenAI 选择后者,即训练验证器在每个 token 之后进行预测。
如下图所示,它们分别标记为“解决方案级别”和“token 级别”。
在b图中,通过消融实验验证训练验证器中使用目标(objective)的作用, OpenAI 将使用两个目标与仅使用验证目标进行比较。
在c图中,OpenAI 对生成器和验证器的大小进行了实验,研究发现使用大的生成器、小的验证器组合性能显著优于小的生成器、大的验证器组合。

3
写在最后
通过OpenAI所展现出的10个数学实例是看出,使用验证方法比单纯扩大参数要更加智能,但缺点是并不稳定。比如在另一个问题实例中,仅有175B验证模型输出正确结果:小明是一所私立学校的院长,他有一个班。小红是一所公立学校的院长,他有两个班,每个班的人数是小明班级人数120人的1/8。问两所学校的总人数是多少?
AI发展道阻且长,目前绝大多数的机器学习仍依赖于数据堆砌,缺乏根本性的技术突破,存在一定的发展瓶颈。Google 工程总监 Ray Kurzweil 曾表示,直到 2029 年,人类才有超过 50% 的概率打造出 AGI 系统,还有一部分专家表示至少要到2099年或2200年。
现下,通过在一些简单的领域试验新路径,识别和避免机器学习的错误是推动模型发展的关键方法,比如这种简单的小学数学题。最终当我们试图将模型应用到逻辑上更复杂的领域时,那些不被了解的黑箱子将变得越来越透明。
参考链接:https://openai.com/blog/grade-school-math/
https://zhuanlan.zhihu.com/p/427877874

雷锋网
相关文章








关于作者

猜你喜欢































