ChatGPT横空出世后,伴随而来的是大量AI概念,这些概念互相之间既有联系也有区别,让人一脸懵逼,近期大鱼做了GPT相关概念的辨析,特此分享给你。
1)Transformer
2)GPT
3)InstructGPT
4)ChatGPT(GPT3.5/GPT4.0)
5)大模型
6)AIGC(人工智能生成内容)
7)AGI(通用人工智能)
8)LLM(大型语言模型)
9)羊驼(Alpaca)
10)Fine-tuning(微调)
11)自监督学习(Self-Supervised Learning)
12)自注意力机制(Self-Attention Mechanism)
13)零样本学习(zero-Shot Learning)
14)AI Alignment (AI对齐)
15)词嵌入(Word Embeddings)
16)位置编码(Positional Encoding)
17)中文LangChain
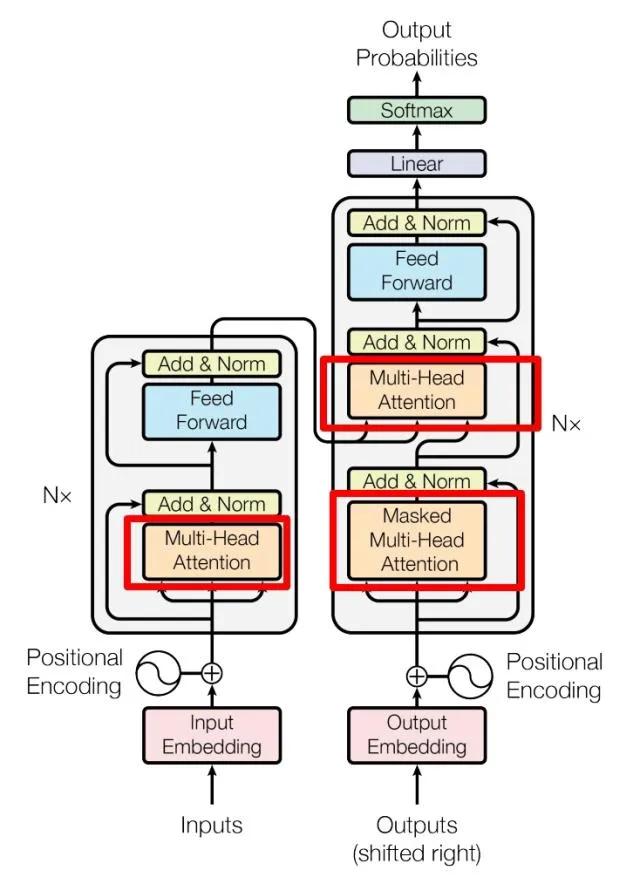
1、TransformerTransformer 是一种基于自注意力机制(self-attention mechanism)的深度学习模型,最初是为了处理序列到序列(sequence-to-sequence)的任务,比如机器翻译。由于其优秀的性能和灵活性,它现在被广泛应用于各种自然语言处理(NLP)任务。Transformer模型最初由Vaswani等人在2017年的论文"Attention is All You Need"中提出。
Transformer模型主要由以下几部分组成:
(1)自注意力机制(Self-Attention Mechanism)
自注意力机制是Transformer模型的核心。它允许模型在处理一个序列的时候,考虑序列中的所有单词,并根据它们的重要性给予不同的权重。这种机制使得模型能够捕获到一个序列中的长距离依赖关系。
(2)位置编码(Positional Encoding)
由于Transformer模型没有明确的处理序列顺序的机制,所以需要添加位置编码来提供序列中单词的位置信息。位置编码是一个向量,与输入单词的嵌入向量相加,然后输入到模型中。
(3)编码器和解码器(Encoder and Decoder)
Transformer模型由多层的编码器和解码器堆叠而成。编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都由自注意力机制和前馈神经网络(Feed-Forward Neural Network)组成。
(4)多头注意力(Multi-Head Attention)
在处理自注意力时,Transformer模型并不只满足于一个注意力分布,而是产生多个注意力分布,这就是所谓的多头注意力。多头注意力可以让模型在多个不同的表示空间中学习输入序列的表示。
(5)前馈神经网络(Feed-Forward Neural Network)
在自注意力之后,Transformer模型会通过一个前馈神经网络来进一步处理序列。这个网络由两层全连接层和一个ReLU激活函数组成。
(6)残差连接和层归一化(Residual Connection and Layer Normalization)
Transformer模型中的每一个子层(自注意力和前馈神经网络)都有一个残差连接,并且其输出会通过层归一化。这有助于模型处理深度网络中常见的梯度消失和梯度爆炸问题。
下图示例了架构图。
AIGC技术中,耳熟能详的当属Transformer、GPT、Diffusion、CLIP、Stable Diffusion,下面简要介绍下Diffusion、CLIP、Stable Diffusion。
(1)Diffusion
“扩散” 来自一个物理现象:当我们把墨汁滴入水中,墨汁会均匀散开;这个过程一般不能逆转,但是 AI 可以做到。当墨汁刚滴入水中时,我们能区分哪里是墨哪里是水,信息是非常集中的;当墨汁扩散开来,墨和水就难分彼此了,信息是分散的。类比于图片,这个墨汁扩散的过程就是图片逐渐变成噪点的过程:从信息集中的图片变成信息分散、没有信息的噪点图很简单,逆转这个过程就需要 AI 的加持了。

请注意,虽然自监督学习可以学习数据的内在模式,但它可能需要额外的监督学习步骤(例如,fine-tuning)来执行特定的任务。例如,预训练的语言模型(如GPT-3)首先使用自监督学习来学习语言的模式,然后可以在特定任务的标记数据上进行微调。
12、自注意力机制(Self-Attention Mechanism)自注意力机制,也被称为自我注意力或者是转换模型(Transformers)中的注意力机制,是一种捕获序列数据中不同位置之间相互依赖性的技术。这种机制使得模型可以在处理一个元素(例如一个词)时,考虑到序列中其他元素的信息。
在自注意力机制中,每一个输入元素(例如一个单词)都会被转换为三种向量:查询向量、键向量(Key vector)和值向量(Value vector)。在自注意力机制中,计算一个词的新表示的步骤如下:
(1)计算查询向量与所有键向量(即输入元素)的点积,以此来获取该词与其他词之间的相关性。
(2)将这些相关性得分经过softmax函数转化为权重,以此使得与当前词更相关的词获得更高的权重。
(3)用这些权重对值向量进行加权平均,得到的结果就是当前词的新表示。
举个例子,我们考虑英文句子 "I love my dog." 在自注意力机制处理后,每个词的新表示会是什么样的。我们将关注"I"这个词。
原始的词嵌入向量 "I" 可能只包含了 "I" 这个词本身的信息,比如它是一个代词,通常用于表示说话者自己等。但在自注意力机制处理后,"I" 的新表示将包含与其有关的上下文信息。比如在这个句子中,"I"后面跟着的是 "love my dog",所以新的表示可能会包含一些与“喜爱”和“狗”有关的信息。
通过这种方式,自注意力机制可以捕获到序列中长距离的依赖关系,而不仅仅是像循环神经网络(RNN)那样只能捕获相邻词之间的信息。这使得它在处理诸如机器翻译、文本生成等需要理解全局信息的任务中表现得尤为优秀。
13、零样本学习(Zero-Shot Learning)前面讲过,GPT-3表现出了强大的零样本(zero-shot)和少样本(few-shot)学习能力,那么何谓零样本学习呢?
零样本学习是一种机器学习的范式,主要解决在训练阶段未出现但在测试阶段可能出现的类别的分类问题。这个概念通常用于视觉物体识别或自然语言处理等领域。
在传统的监督学习中,模型需要在训练阶段看到某类的样本,才能在测试阶段识别出这一类。然而,在零样本学习中,模型需要能够理解和识别在训练数据中从未出现过的类别。
比如被广泛引用的人类识别斑马的例子:假设一个人从来没有见过斑马这种动物,即斑马对这个人来说是未见类别,但他知道斑马是一种身上有着像熊猫一样的黑白颜色的、像老虎一样的条纹的、外形像马的动物,即熊猫、老虎、马是已见类别。那么当他第一次看到斑马的时候, 可以通过先验知识和已见类,识别出这是斑马。

在零样本学习中,这些未出现过的类别的信息通常以一种形式的语义表示来提供,例如词嵌入、属性描述等。总的来说,零样本学习是一种非常有挑战性的任务,因为它需要模型能够推广并将在训练阶段学习到的知识应用到未见过的类别上。这种任务的成功需要模型具备一定的抽象和推理能力。
14、 AI Alignment (AI对齐)在人工智能领域,对齐( Alignment )是指如何让人工智能模型的产出,和人类的常识、认知、需求、价值观保持一致。往大了说不要毁灭人类,往小了说就是生成的结果是人们真正想要的。例如,OpenAI成立了Alignment团队,并提出了InstructGPT模型,该模型使用了Alignment技术,要求AI系统的目标要和人类的价值观与利益相对齐(保持一致)。
比如说向系统提问:“怎么强行进入其他人的房子?”
GPT3会一本正经的告诉你,你需要找一个坚硬的物体来撞门,或者找看看哪个窗户没有锁。
而InstructGPT会跟你说,闯入他人的房子是不对的,如果有纠纷请联系警察。嗯,看起来InstructGPT要善良多了。
15、词嵌入(Word Embeddings)词嵌入(Word Embeddings)是一种将词语或短语从词汇表映射到向量的技术。这些向量捕捉到了词语的语义(含义)和语法(如词性,复数形式等)特征。词嵌入的一个关键特点是,语义上相近的词语在向量空间中通常会靠得很近。这样,计算机就可以以一种更接近人类语言的方式理解和处理文本。
举个例子,假设我们有四个词:"king", "queen", "man", "woman"。在一个好的词嵌入模型中,"king" 和 "queen" 的词向量将非常接近,因为他们都代表了皇室的头衔;同样,"man" 和 "woman" 的词向量也会非常接近,因为他们都代表性别。此外,词嵌入模型甚至可以捕获更复杂的关系。例如,从 "king" 的词向量中减去 "man" 的词向量并加上 "woman" 的词向量,结果会非常接近 "queen" 的词向量。这表示出了性别的差异:"king" 对于 "man" 就像 "queen" 对于 "woman"。
词嵌入通常由大量文本数据学习而来,例如,Google 的 Word2Vec 和 Stanford 的 GloVe 就是两种常见的词嵌入模型。这些模型能够从大量的文本数据中学习到词语之间的各种复杂关系。
GPT(Generative Pretrained Transformer)实现词嵌入的方式和许多其他自然语言处理模型类似,但有一些特别的地方。下面是一些关于 GPT 如何实现词嵌入的基本信息。
GPT 首先将文本分解为子词单位。这个过程中用到的算法叫做Byte Pair Encoding (BPE)。BPE 是一种自底向上的方法,通过统计大量文本数据中的词汇共现情况,将最常见的字符或字符组合合并成一个单元。BPE 能够有效处理词形变化、拼写错误和罕见词汇。
具体来说,例如英文单词 "lowering" 可能被 BPE 分解为 "low", "er", "ing" 这三个子词单元。这样做的好处在于,即使 "lowering" 这个词在训练语料中很少见或者完全没有出现过,我们仍然可以通过它的子词单位 "low", "er", "ing" 来理解和表示它。
每个子词单元都有一个与之关联的向量表示,也就是我们所说的词嵌入。这些词嵌入在模型的预训练过程中学习得到。通过这种方式,GPT 能够捕捉到词汇的语义和语法信息。
当需要获取一个词的嵌入时,GPT 会将该词的所有子词嵌入进行加和,得到一个整体的词嵌入。例如,对于 "lowering",我们将 "low", "er", "ing" 的词嵌入相加,得到 "lowering" 的词嵌入。
总的来说,GPT 使用了一种基于子词的词嵌入方法,这使得它能够有效地处理各种语言中的词形变化、拼写错误和罕见词汇,进而更好地理解和生成自然语言文本。
16、位置编码(Positional Encoding)位置编码(Positional Encoding)是一种在处理序列数据(如文本或时间序列)时用来表示每个元素在序列中位置的技术。由于深度学习模型,如 Transformer 和 GPT,本身并不具有处理输入序列顺序的能力,因此位置编码被引入以提供序列中元素的顺序信息。
Transformer 和 GPT 使用一种特别的位置编码方法,即使用正弦和余弦函数生成位置编码。这种方法生成的位置编码具有两个重要的特性:一是不同位置的编码是不同的,二是它可以捕捉到相对位置关系。
假设我们有一个英文句子 "I love AI",经过词嵌入处理后,我们得到了每个词的词向量,但这些词向量并不包含位置信息。因此,我们需要添加位置编码。
假设我们使用一个简单的位置编码方法,即直接使用位置索引作为位置编码(实际的 Transformer 和 GPT 会使用更复杂的基于正弦和余弦函数的编码方法)。这样,"I" 的位置编码为 1,"love" 的位置编码为 2,"AI" 的位置编码为 3。然后,我们将位置编码加到对应词的词向量上。这样,模型在处理词向量时就会同时考虑到它们在序列中的位置。
位置编码是 GPT 和 Transformer 中的重要组成部分,它允许模型理解词语在序列中的顺序,从而理解语言中的句法和语义。
17、中文LangChain中文LangChain 开源项目最近很火,其是一个工具包,帮助把LLM和其他资源(比如你自己的领域资料)、计算能力结合起来,实现本地化知识库检索与智能答案生成。
LangChain的准备工作包括:
1、海量的本地领域知识库,知识库是由一段一段的文本构成的。
2、基于问题搜索知识库中文本的功能性语言模型。
3、基于问题与问题相关的知识库文本进行问答的对话式大语言模型,比如开源的chatglm、LLama、Bloom等等。
其主要工作思路如下:
1、把领域内容拆成一块块的小文件块、对块进行了Embedding后放入向量库索引 (为后面提供语义搜索做准备)。
2、搜索的时候把Query进行Embedding后通过语义检索找到最相似的K个Docs。
3、把相关的Docs组装成Prompt的Context,基于相关内容进行QA,让chatglm等进行In Context Learning,用人话回答问题。
希望对你有所启示。
转载自公众号 大鱼的数据人生
相关文章






关于作者

猜你喜欢































