在 6 月 27 日举办的讯飞星火 V4.0 发布会上,科大讯飞发布了讯飞星火大模型 V4.0,以及在医疗、教育、商业等多个领域的人工智能应用。
讯飞星火大模型 V4.0 基于全国首个国产万卡算力集群“飞星一号”训练而成,全面提升了大模型底座的七大核心能力。整体超越 GPT-4 Turbo,特别是针对复杂指令、复杂逻辑推理、空间推理、数学、基于逻辑关系的多模理解等方面有着显著的提升。

点击左下角的头像可打开“我的”标签,在底部中间的输入框则可以进行对话。
在“对话”功能中,增加了长文本问答的能力,点击对话框右侧的上传文件按钮即可上传文件进行对话。
然后小编还针对文档中的一些内容对讯飞星火 V4.0 进行提问,比如小编问它“文档中对 MR 的定义是什么?”它也给出了准确的答案,对照文档中的相关解释,回答得没毛病。

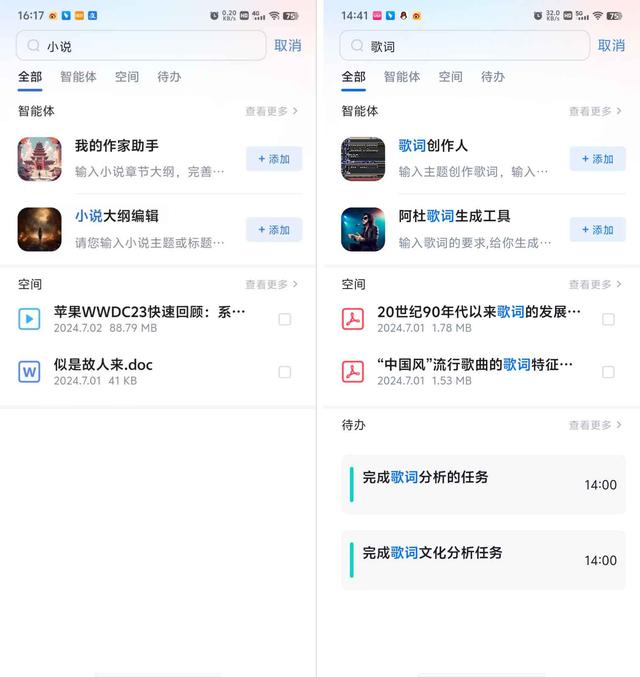
通过顶部的搜索功能,还可以用关键词搜索相关的智能体、“我的空间”中的文档以及待办事项等信息。
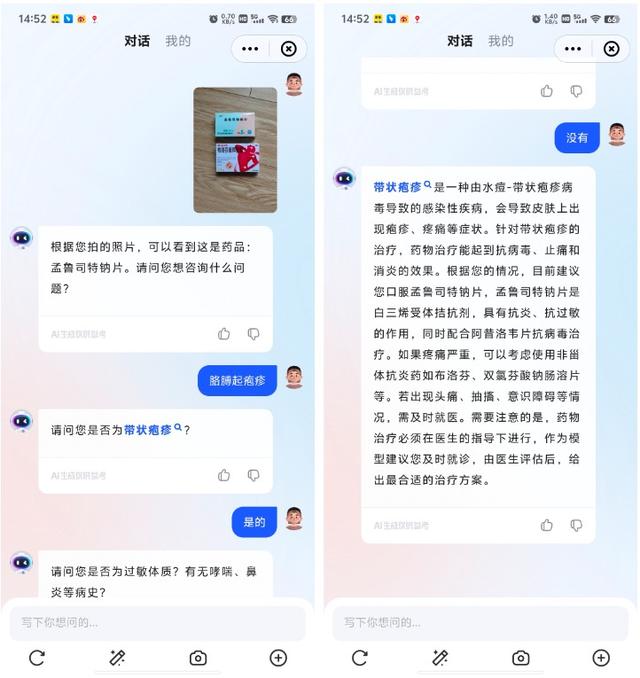
日常生活中,当我们吃药时经常会遇到“不知道这两种药能不能一起吃”的困扰,专门为此去询问医生也比较麻烦,这时就可以用“讯飞晓医”的拍照功能,同时拍下两个药盒,“讯飞晓医”就会结合自身的专业知识来告诉你这两个药是否可以一起吃。
这里小编用自己之前起带状疱疹时医生开的两种药来对其进行测试,同时拍下两个药盒,当小编说出胳膊起疱疹时,“讯飞晓医”初步判断为带状疱疹,然后给出了带状疱疹的相关科普以及用药建议,在用药建议中能看到这两个药可以一起吃,这和医生开出来的结果也是一样的。
过去很多时候我们使用 AI 大模型产品输入输出得到的结果都是公开的信息,而对于我们个人的信息,那些公开的大模型就无能为力。但其实无论是学习、工作还是生活,我们往往需要大模型能更懂我们个人的需求,有一个属于我们个人的知识库,全新升级的讯飞星火也考虑到了这一点,特别推出了“个人空间”的功能。
“个人空间”相当于是为用户打造的专属私域知识库,通过上传个人文档,让大模型进行更精确的知识问答和内容生成;并且通过人设标签、日程管理、信息订阅、创建发音人,为用户提供更加个性化和趣味化的服务。
在个人空间里,上传的文档默认会按时间顺序进行排列,你也可以切换到不同文件分类的条目下进行查看。
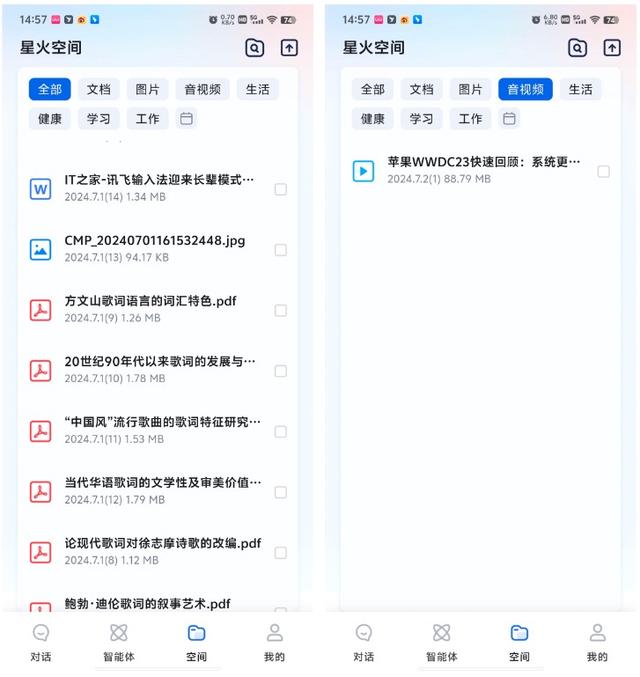
再比如小编上传了一份过去某个 10 月份自己所写的文章统计 EXCEL 表格,选中后点击“Excel”分析选项,进入对话界面,小编首先问它“我这个月写了多少篇文章”,它准确地回答出了 21 篇文章。然后小编又问它“我写的所有文章一共有多少字”,它则给出了 50563 个字。小编算了一下,也是正确的。
另外,在小编的个人空间里还有几篇和新能源汽车“三电”系统相关的研报资料,测试时,小编同时选择 5 个资料文档,让讯飞星火根据这 5 个资料文件写一篇关于介绍新能源汽车“三电”系统的文章,文章内容需要包含:
(1)什么是新能源汽车的“三电”系统。
(2)新能源汽车的“三电”系统各自有什么技术门类?
(3)我国在新能源汽车“三电”系统方面的发展现状。

可以看到,在设定“引经据典,文化内涵”的标签后,讯飞星火输出的短文确实加入了不少名言典故,包括《孟子・告子下》、《论语・阳货》、《论语・述而》等等。
总体来说,全新升级的讯飞星火 App / Desk 功能更强大、更丰富,但在交互布局上并没有显得凌乱,无论是星火 App 还是星火 Desk 各项功能层级都有序、清晰,而且丰富的智能体的加入让讯飞星火更好用、更实用,个人空间以及个性标签等个性化的功能,则让讯飞星火能够成为更懂你的大模型 AI 助手。
二、讯飞星火大模型 V4.0 通用能力体验正如前文所说,本次讯飞星火 V4.0 在通用能力方面全面提升了大模型底座的七大核心能力,特别是针对复杂指令、复杂逻辑推理、空间推理、数学、基于逻辑关系的多模理解等方面有着显著的提升。同时在多模态能力上也得到了再升级。
这里IT之家也针对这些通用能力做了体验测试,测试过程中小编用 GPT-4o 来进行对比,方便大家对讯飞星火 V4.0 的体验有深入的认知。
1、视频理解能力体验讯飞星火 V4.0 在多模态能力上目前已经可以支持视频的分析、理解能力,在测试时,IT之家上传了一段此前发布过的视频节目,来让他进行分析。这段视频是关于 2023 年苹果 WWDC 快速回顾的内容,小编让讯飞星火 V4.0 简述一下视频内容,它的回答很准确,完整给出了视频的核心内容。

而 GPT-4o 目前还不支持视频分析的功能,同样的问题让 GPT-4o 来回答,会出现“无法处理”的信息。
上传这张图片,直接让讯飞星火 V4.0 进行解答,可以看到,它给出的答案是正确的,解题的过程也没有什么问题。

GPT-4o 方面,逻辑思维也挺清楚,实际可操作性也没有问题,不过生成的答案重复,说明的文字较多,步骤也略繁琐些,也算是美中不足吧。

GPT-4o 方面给出的思考步骤和答案也没什么问题:

前面我们测试过两款大模型的逻辑推理能力,与之相似的其实还有数学答题的能力,可以更进一步检测大模型的“智商水平”。测试时,我们直接上今年全国高考卷的真题。
比如这一题:

这是一道函数解析几何的题目,讯飞星火 V4.0 成功做出了回答,小编看了一下答案,是正确的。

至于 GPT-4o,一顿操作猛如虎,一看答案没算出。

讯飞星火 V4.0 给出的答案很简洁,虽然小编残存的数学知识不多,但看解题步骤,还是没问题的,最后的结果也是正确的。

在语言理解能力方面,IT之家主要测试大模型的文本信息抽取能力、情感分析能力、翻译能力和歧义理解能力。
首先文本信息抽取能力方面,我们选择了IT之家此前发布的两篇新闻进行杂糅,让大模型从中提取信息,问题如下:

接着看情感分析能力,小编在这里抽取了 2022 年江苏连云港终稿语文试卷的一道阅读理解题目,题目如下:

GPT-4o 这边的翻译效果也很好,和讯飞星火 V4.0 差不多。
最后是语言歧义的理解能力,IT之家找来一句可能产生歧义的句子让大模型去分析:
分析并修改下面这句话中可能产生歧义的问题:
县里的通知说,让赵乡长本月 15 日前去报到。
讯飞星火 V4.0 准确分析出了居中可能存在歧义的原因,在于时间表述不清楚,给出的两种修改方案都可以让句子没有歧义。
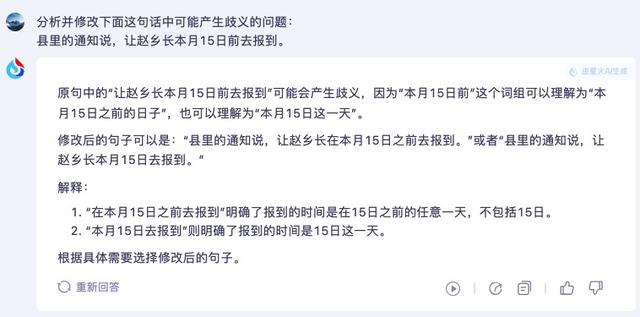
GPT-4o 对这句话的歧义问题分析就出现了偏差,修改的结果也不对,有点不知所云。
GPT-4o 写的文案也很优秀,要求的点都满足了。

上班族们经常会需要写一些方案、活动计划之类的,这时候也可以借助大模型的内容生成能力来帮助自己更快地完成任务。这里IT之家以“我司计划开展一个读书活动,帮我写一个活动方案”为需求,来进行测试。
讯飞星火给出的方案则是比较完整的,时间、地点、目标、流程、前期准备、人员配置、预算评估、结果评估等环节都有,而且不缺细节,可用性很高。

GPT-4o 的计划书相对简洁一些,但也比较完整,该有的地方都有了。

用 AI 大模型辅助写代码也是一些程序员常遇到的使用场景,这也可以视为大模型内容生成能力的重要组成。
测试时,小编首先用下面这个问题来考验两个大模型:
请用 c# 语言生成以下代码:给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
代码请遵循以下模板:
public class Solution {
public string LongestPalindrome(string s) {
}
}
我们以代码能直接拿来使用为准则,将大模型生成的代码用程序运行工具进行检测,看是否能直接完美运行。
首先还是看讯飞星火 V4.0,它给出的代码格式标准,算法也比较简洁,看起来很清爽。
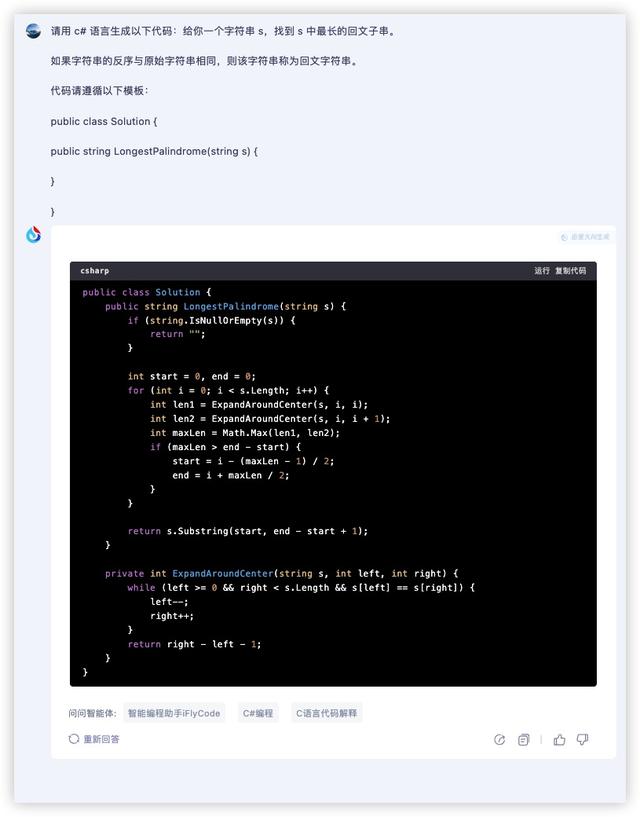
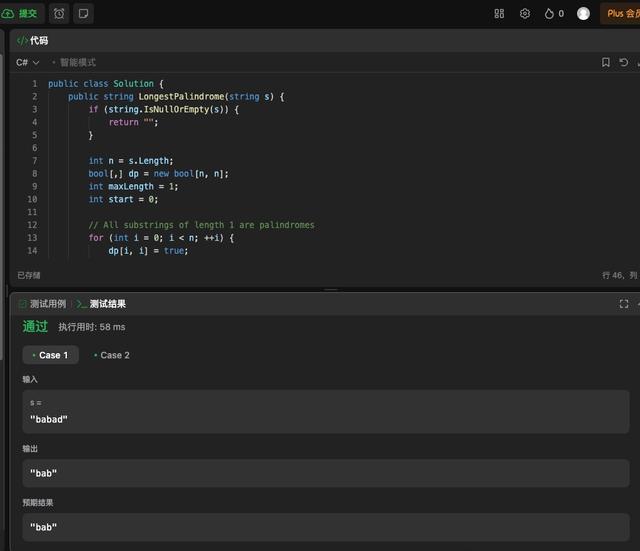
由于小编自己不懂代码,所以直接拿到检测工具中运行检测,发现这段代码可以直接运行,输出结果也是准确的,也就是说可以直接拿来用。

GPT-4o 这边,给出的代码同样有规范的格式,也比较简洁.
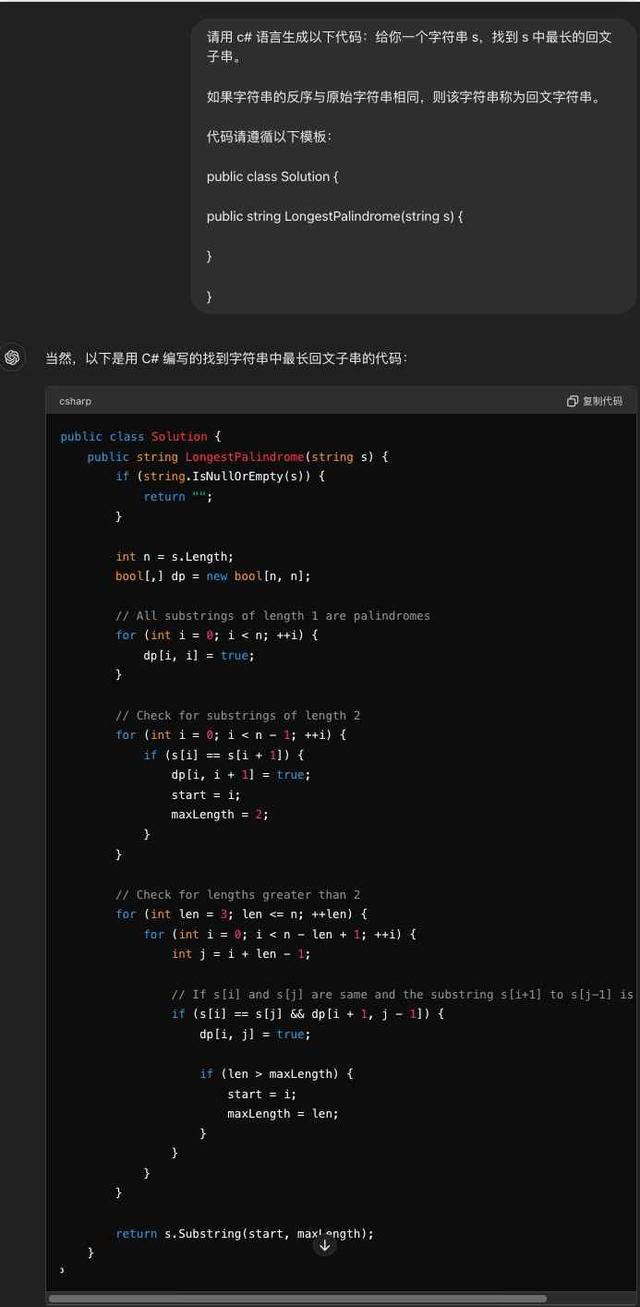
拿到检测软件中运行,也可以成功运行,表现同样不错。
总体来说,在大模型的通用能力方面,讯飞星火 V4.0 和目前 ChatGPT 最先进的 GPT-4o 模型相比,从小编测试的情况来看已经不相上下,在多模态、逻辑思维、数学能力等方面甚至还要好于 GPT-4o,在日常生活和工作中,大家完全可以只用讯飞星火 V4.0,就能带来非常大的效率提升和其他方面的助益。
结语讯飞星火大模型从去年 5 月份正式发布,到目前迭代到第四个大版本,仅仅只有一年多的时间,这一年多里,讯飞星火的进步可以说是神速,从最基础的开放式问答到 AI 智能助手、再到多模态能力、全语音交互,还有讯飞友伴等,再到如今智能体、个人空间等功能的上线,讯飞星火的功能在变得越来越全面且强大的同时,也关注到用户对于内容生成“个性化”的需求,如今的讯飞星火 V4.0 目前最全能、应用属性最强的 AI 大模型产品之一了。
在发布会上,科大讯飞还谈到了讯飞星火大模型在国家能源集团、中国石油、中国移动、中国人保、太平洋保险、交通银行等重点行业的应用,可见讯飞星火已经在 AI 大模型领域构建起自主可控的独特优势,而通过对讯飞星火 V4.0 的体验,IT之家也对讯飞星火未来在 AI 领域的表现充满期待,相信他们能够持续进化,让国产 AI 大模型技术和应用生态真正实现国际化的引领。
相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234299 电子证书1033 电子名片60 自媒体46877































