
Scaling Law失效了么,这是当前 AI 领域最热门的话题之一。近日人工智能科学家 Cameron R. Wolfe发表了一篇万字博客文章,详细介绍了 LLM scaling 的发展状况,并阐述了他对 AI 研究未来的看法。

这里研究的两个量是 和 ,而 和 是描述这些量之间关系的常数。如果我们绘制这个幂律函数xyap2,我们得到下图。我们提供正常尺度和对数尺度的绘图,因为大多数研究 LLM 尺度的论文都使用对数尺度。
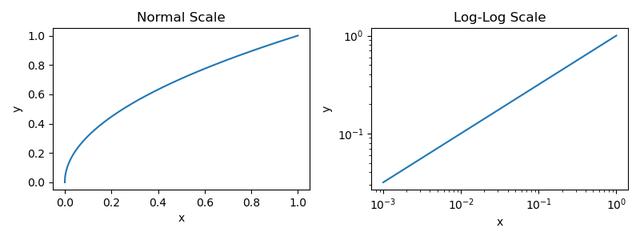
和 之间的基本幂律图 xy
但是,为 LLM 缩放提供的绘图看起来与上面显示的绘图不同,它们通常是颠倒的;请参阅下面的示例。
无对数刻度的幂律图
鉴于许多围绕扩展和 AGI 的在线言论,这样的发现似乎有悖常理。在许多情况下,我们得到的直觉似乎是,LLM 的质量会随着计算的对数增加而呈指数级提高,但事实并非如此。实际上,随着规模的扩大,提高 LLM 的质量会变得呈指数级增长。
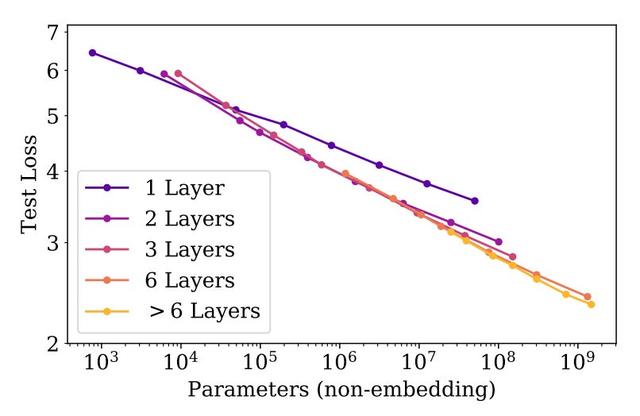
(来自 [3])
GPT-2 [3] 是在 GPT 之后不久提出的,包括几个参数大小高达 1.5B 的模型的集合;见上文。这些模型与 GPT 模型共享相同的架构,并使用相同的自监督语言建模目标进行预训练。然而,与 GPT 相比,GPT-2 对预训练过程进行了两个重大变化:
这些模型在 WebText 上进行了预训练,WebText 是 i) 比 BooksCorpus 大得多,并且 ii) 通过从互联网上抓取数据来创建。这些模型不会在下游任务上进行微调。相反,我们通过执行零样本推理来解决任务7使用预训练模型。GPT-2 模型在大多数基准测试中都达不到最先进的性能8,但它们的性能会随着模型的大小而不断提高 - 增加模型参数的数量会产生明显的好处;请参阅下文。
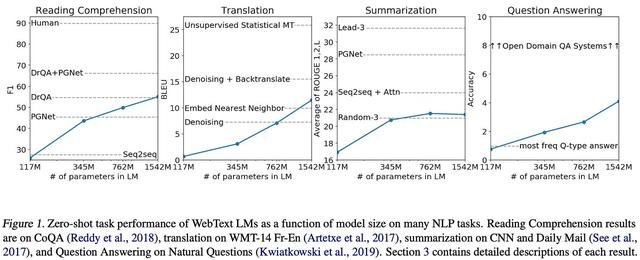
(来自 [4])
GPT-3 在 [4] 中主要通过使用小样本学习方法进行评估。小样本提示(GPT-3 使用)、零样本提示(GPT-2 使用)和微调(GPT 使用)之间的区别如下所示。
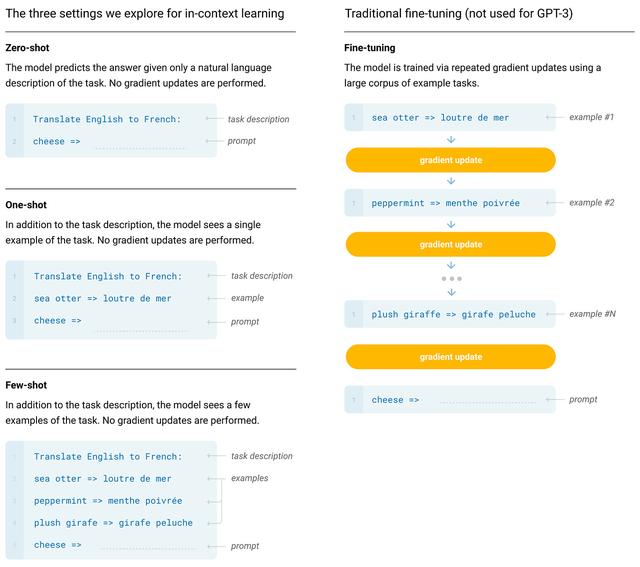
(来自 [4])
当在各种语言理解任务上评估 GPT-3 时,我们看到使用更大的模型显着有利于小样本学习性能,如下图所示。相对于较小的模型,较大的模型可以更好、更高效地利用其上下文窗口中的信息。GPT-3 能够通过小样本学习在多项任务上超越最先进的性能,并且模型的性能随着大小的增加而顺利提高。
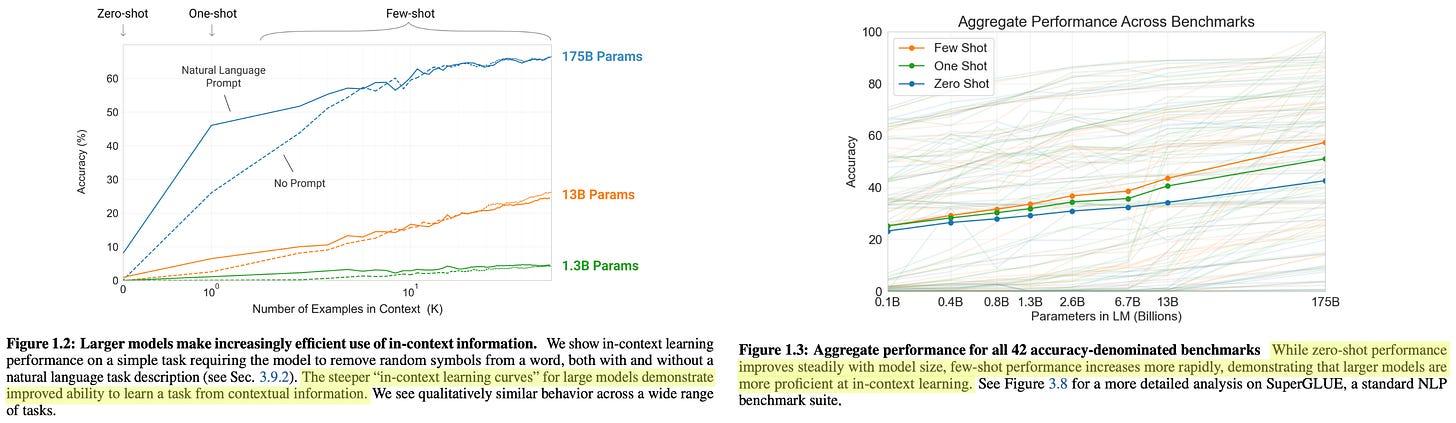
(来自 [8])
与 ChatGPT 相比,GPT-4 在功能上有了显着的提升。然而,研究人员选择分享 GPT-4 的技术细节非常少。GPT-4 的技术报告 [5] 简单地告诉我们:
GPT-4 是基于 transformer 的。该模型使用 next token prediction 进行预训练。使用公共和许可的第三方数据。该模型通过来自人类反馈的强化学习进行微调。尽管如此,在这份技术报告中,扩展的重要性非常明显。作者指出,这项工作中的一个关键挑战是开发一种可扩展的训练架构,该架构在不同规模上的行为是可预测的,允许推断较小运行的结果,从而为更大规模(而且要昂贵得多)的训练练习提供信心。
“经过适当训练的大型语言模型的最终损失是......用幂律近似于用于训练模型的计算量。- 来自 [5]
大规模的预训练非常昂贵,因此我们通常只有一次机会把它做好——没有空间进行特定于模型的调整。缩放定律在这个过程中起着关键作用。我们可以少用 1,000-10,000 倍的计算来训练模型,并使用这些训练运行的结果来拟合幂律。然后,这些幂律可以用来预测更大模型的性能。特别是,我们在 [8] 中看到,GPT-4 的性能是使用衡量计算和测试损失之间关系的幂律来预测的;见下文。
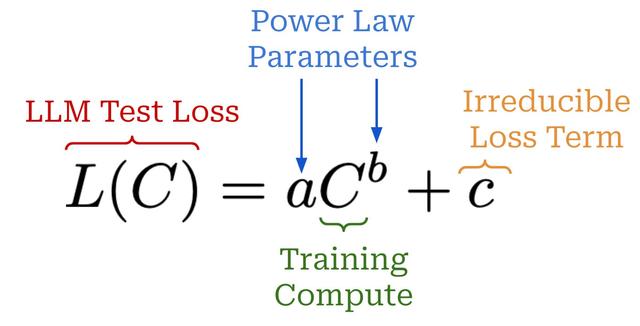
用于训练 GPT-4 的缩放定律公式(来自 [5])
这个表达式看起来与我们之前看到的几乎相同,但它增加了一个不可约损失项,以解释 LLM 的测试损失可能永远不会达到零的事实。拟合后,缩放定律被用来预测 GPT-4 的最终性能,精度非常高;描述见下文。在这里,我们应该注意,该图不是使用对数标度生成的,我们看到损失的改善显然随着计算量的增加而开始衰减!
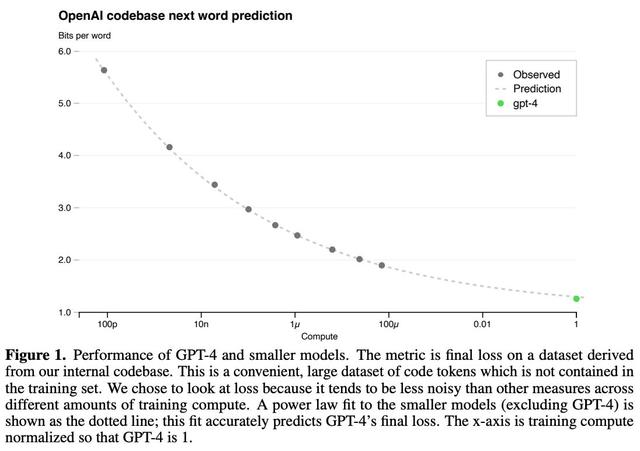
(来自 [5])
正如我们所看到的,扩大预训练过程是有价值的。然而,大规模的预训练也非常昂贵。扩展定律使这个过程更具可预测性,使我们能够避免不必要或过多的计算成本。
Chinchilla:训练计算最优大型语言模型[5]
(来自 [5])
换句话说,缩放定律会随着时间的推移自然地趋于稳定。通过这种方式,我们目前正在经历的“放缓”可以说是 LLM 缩放定律的预期部分。
“从业者经常使用下游基准精度作为模型质量的代理,而不是困惑评估集的损失。”- 来自 [7]
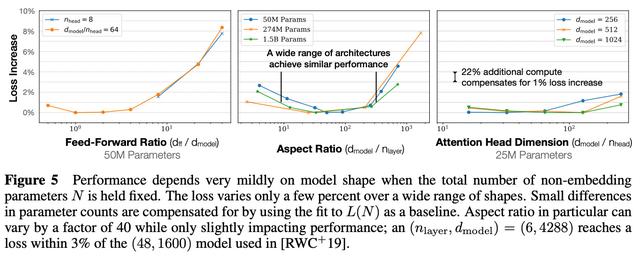
定义性能。我们如何衡量 LLM 是否在改进?从扩展定律的角度来看,LLM 性能通常是通过模型在预训练期间的测试损失来衡量的,但较低的测试损失对 LLM 能力的影响尚不清楚。较低的损失是否会导致下游任务的准确性更高?较低的损失是否会导致 LLM 获得新的能力?缩放定律告诉我们的内容与我们实际关心的内容之间存在脱节:
缩放定律告诉我们,增加预训练的规模将平稳地减少 LLM 的测试损失。我们关心获得“更好”的 LLM。根据你是谁,你对新 AI 系统的期望——以及你用来评估这些新系统的方法——会有很大的不同。普通 AI 用户往往专注于一般的聊天应用程序,而从业者通常关心 LLM 在下游任务上的表现。相比之下,顶级前沿实验室的研究人员似乎对 AI 系统抱有很高(而且非常特殊)的期望;例如,写一篇博士论文或解决高级数学推理问题。鉴于 LLM 具有如此广泛的功能,评估是困难的,而且我们可以从许多角度来查看 LLM 的表现;见下文。

(来自 [15])
鉴于模型期望的这种巨大差异,提供扩展是 “有效 ”的明确证据将永远是一场斗争。我们需要一个更具体的扩展定律的成功定义。如果科学告诉我们,更大的模型将实现更低的损失,这并不意味着新模型将满足每个人的期望。未能达到 AGI 或超过屡获殊荣的人类数学家的能力并不能证明扩展在技术层面上没有仍然有效!换句话说,有人可能会争辩说,扩展的 “减慢” 是一个感知和期望问题,而不是 scalion 定律的技术问题。
数据死亡。为了扩大 LLM 预训练的规模,我们必须增加模型和数据集的大小。早期的研究 [1] 似乎表明数据量不如模型大小重要,但我们在 Chinchilla [6] 中看到数据集大小同样重要。此外,最近的工作认为,大多数研究人员更喜欢 “过度训练” 他们的模型,或者在大小超过龙猫最优性的数据集上对其进行预训练,以节省推理成本 [7]。
“扩展研究通常集中在计算最优的训练制度上......由于较大的模型在推理时成本更高,现在通常的做法是过度训练较小的模型。- 来自 [7]
所有这些研究都让我们得出了一个简单的结论——扩大 LLM 预训练需要我们创建更大的预训练数据集。这一事实构成了对 LLM 缩放定律的主要批评之一的基础。许多研究人员认为,可能没有足够的数据来继续扩展预训练过程。就上下文而言,用于当前 LLM 的大部分预训练数据是通过网络抓取获得的;见下文。鉴于我们只有一个互联网,找到大规模、高质量预训练数据的全新来源可能很困难。
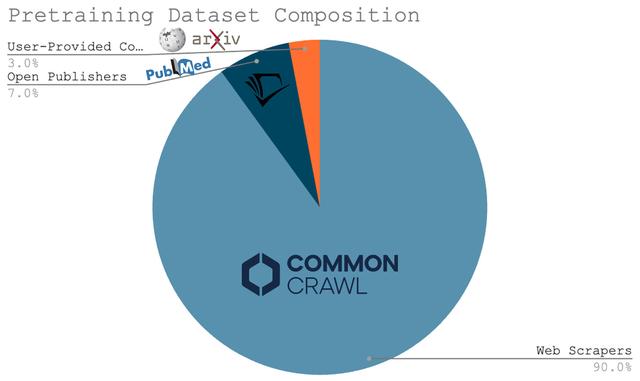
(源)
甚至 Ilya Sutskever 最近也提出了这一论点,声称 i) 计算正在快速增长,但 ii) 由于依赖网络抓取,数据没有增长。因此,他认为我们不能永远继续扩大预训练过程。我们所知道的预训练将结束,我们必须为 AI 研究找到新的进展途径。换句话说,“我们已经实现了峰值数据”。
用于预训练的下一代 Scale扩展最终会导致收益递减,以数据为中心的反对继续扩展的论点既合理又令人信服。然而,仍有几个研究方向可以改进预训练过程。
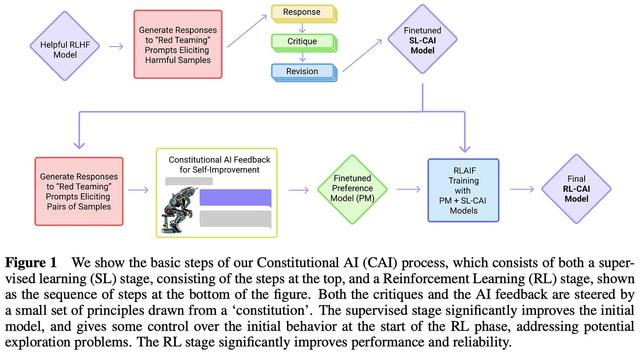
(来自 [18])
超越 GPT-4o 等模型的能力对于开放权重 LLM 来说是一个重大飞跃——即使是最大的 LLaMA 模型也未能达到这个目标。DeepSeek-v3 采用了各种有趣的技巧:
来自 DeepSeek-v2 的优化 MoE 架构。一种新的辅助无损策略,用于对 MoE 进行负载均衡。多标记预测训练目标。从长链思维模型(即类似于 OpenAI 的 o1)中提炼出推理能力。该模型还进行了后训练,包括监督微调和来自人类反馈的强化学习,以使其与人类偏好保持一致。
“我们在 14.8T 高质量和多样化的 Token 上训练 DeepSeek-V3。预训练过程非常稳定。在整个训练过程中,我们没有遇到任何无法挽回的损失尖峰,也没有遇到任何不得不回滚的情况。- 从 [8] 起
然而,DeepSeek-v3 令人印象深刻的性能的最大关键是预训练规模——这是一个在同等规模的数据集上训练的海量模型!由于各种原因(例如 GPU 故障和损失峰值),训练如此大型的模型很困难。DeepSeek-v3 的预训练过程非常稳定,并且按照 LLM 标准以合理的成本进行训练;见下文。这些结果表明,随着时间的推移,更大规模的预训练作业变得越来越易于管理和高效。

GPT-4o 和 o1 在推理密集型任务上的比较(来自 [21])
如前所述,o1 在复杂推理任务上的表现令人印象深刻。o1 在几乎所有推理密集型任务上都优于 GPT-4o;见上文。作为 o1 推理能力的一个例子,该模型:
在 Codeforces 的竞争性编程问题中排名第 89 个百分位。在美国数学奥林匹克竞赛 (AIME) 资格赛中进入美国前 500 名学生。超过人类博士生在研究生水平的物理、生物和化学问题 (GPQA) 上的准确性。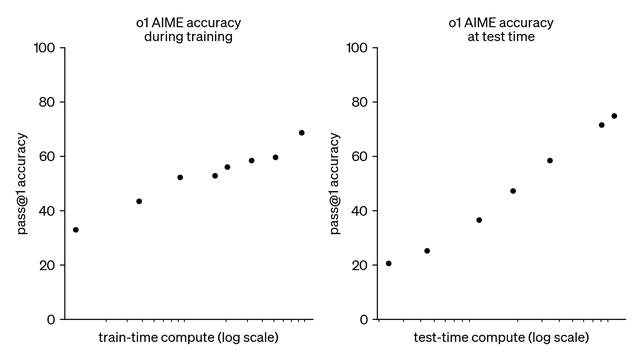
(源)
在撰写本文时,o3 模型尚未发布,但缩放 o1 所获得的结果令人印象深刻(在某些情况下甚至令人震惊)。下面列出了 o3 最显着的成就:
在 ARC-AGI 基准测试中得分为 87.5%, 而 GPT-4o 的准确率仅为 5%。o3 是第一个在 ARC-AGI 上超过 85% 人类水平性能的模型。该基准被描述为通往 AGI 的“北极星”,并且一直保持不败17五年多了。SWE-Bench Verified 的准确率为 71.7%,Codeforces 的 Elo 分数为 2727,在地球上排名前 200 的人类竞技程序员中排名 o3。在 EpochAI 的 FrontierMath 基准测试中,准确率为 25.2%, 比之前最先进的 2.0% 的准确率有所提高。Terence Tao 将这个基准描述 为“难以置信的困难”,并且可能在“至少几年内”无法被 AI 系统解决。还预览了名为 o3-mini 的 o3 的提炼版本,该版本的性能非常好,并且计算效率得到了显著提高。
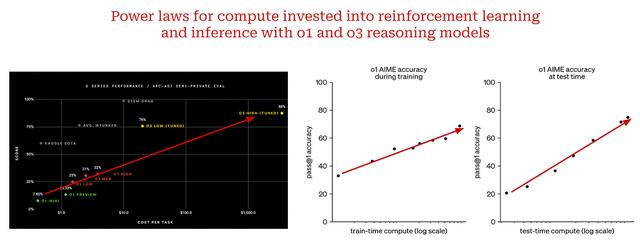
(从 [21] 到这里)
扩展的新范例。阅读此概述后,o1 和 o3 提供的许多图(见上文)可能看起来非常熟悉——这些是对数尺度图,我们看到性能随着计算量的增加而平滑、线性地提高!换句话说,我们看到这些推理模型的性能与两个不同的量之间存在明显的幂律关系:
训练时间(强化学习)计算。推理时计算。扩展 o1 风格的模型不同于传统的扩展定律。我们没有扩大预训练过程的规模,而是扩大了投入到后训练和推理的计算量。这是一种全新的扩展范式,到目前为止,通过扩展推理模型获得的结果非常好。这样的发现告诉我们,除了预训练之外,其他扩展途径显然存在。随着推理模型的出现,我们发现了下一座需要攀登的山峰。尽管它可能以不同的形式出现,但扩展将继续推动 AI 研究的进步。
结束语我们现在对缩放定律、它们对 LLM 的影响以及 AI 研究的未来发展方向有了更清晰的认识。正如我们所了解的,最近对缩放定律的批评有许多促成因素:
缩放定律中的自然衰减。对 LLM 功能的期望差异很大。大规模、跨学科工程工作的延迟。这些问题是有效的,但都不表明扩展没有仍然按预期工作。对大规模预训练的投资将(并且应该)继续,但随着时间的推移,改进将变得呈指数级增长。因此,替代的进步方向(例如,代理和推理)将变得更加重要。然而,随着我们投资于这些新的研究领域,扩展的基本理念将继续发挥巨大作用。扩展是否会继续不是一个问题。真正的问题是我们下一步将扩展什么。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成241596 电子证书1079 电子名片61 自媒体64547































