鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
随着对Sora技术分析的展开,AI基础设施的重要性愈发凸显。
来自字节和北大的一篇新论文在此时吸引关注:
文章披露,字节搭建起的万卡集群,能在1.75天内完成GPT-3规模模型(175B)的训练。

具体来说,字节提出了一个名为MegaScale的生产系统,旨在解决在万卡集群上训练大模型时面临的效率和稳定性挑战。
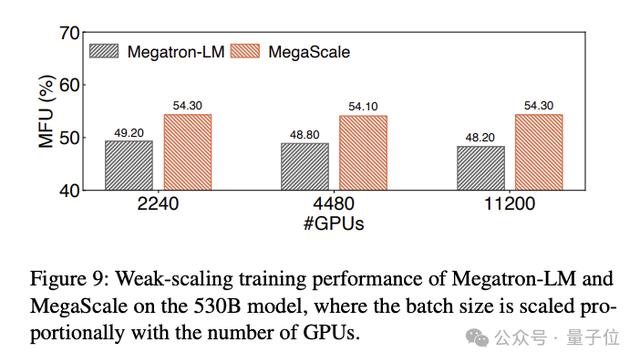
在12288块GPU上训练1750亿参数大语言模型时,MegaScale实现了55.2%的算力利用率(MFU),是英伟达Megatron-LM的1.34倍。
论文还透露,截止2023年9月,字节已建立起超过1万张卡的Ampere架构GPU(A100/A800)集群,目前正在建设大规模Hopper架构(H100/H800)集群。
适用于万卡集群的生产系统大模型时代,GPU的重要性已无需赘述。
但大模型的训练,并不是把卡的数量拉满就能直接开干的——当GPU集群的规模来到“万”字级别,如何实现高效、稳定的训练,本身就是一个颇具挑战的工程问题。

具体改进包括,算法和系统组件的共同设计、通信和计算重叠的优化、操作符优化、数据流水线优化以及网络性能调优等:
算法优化:研究人员在模型架构中引入并行化的Transformer块、滑动窗口注意力机制(SWA)和LAMB优化器,来提高训练效率而不牺牲模型的收敛性。通信重叠:基于对3D并行(数据并行、流水线并行、张量并行)中各个计算单元操作的具体分析,研究人员设计技术策略有效地减少了非关键执行路径上操作所带来的延迟,缩短了模型训练中每一轮的迭代时间。高效操作符:对GEMM操作符进行了优化,对LayerNorm和GeLU等操作进行了融合,以减少启动多个内核的开销,并优化内存访问模式。数据流水线优化:通过异步数据预处理和消除冗余的数据加载器,来优化数据预处理和加载,减少GPU空闲时间。集体通信群初始化:优化了分布式训练中英伟达多卡通信框架NCCL初始化的过程。在未经优化的情况下,2048张GPU的集群初始化时间是1047秒,优化后可降至5秒以下;万卡GPU集群的初始化时间则可降至30秒以下。网络性能调优:分析了3D并行中的机器间流量,设计技术方案提高网络性能,包括网络拓扑设计、减少ECMP哈希冲突、拥塞控制和重传超时设置。故障容忍:在万卡集群中,软硬件故障难以避免。研究人员设计了一个训练框架,来实现自动故障识别和快速恢复。具体包括,开发诊断工具来监控系统组件和事件、优化checkpoint高频保存训练进程等。论文提到,MegaScale能够自动检测和修复超过90%的软硬件故障。

实验结果表明,MegaScale在12288个GPU上训练175B大语言模型时,实现了55.2%的MFU,是Megatrion-LM算力利用率的1.34倍。
训练530B大语言模型的MFU对比结果如下:
 One More Thing
One More Thing就在这篇技术论文引发讨论之际,字节类Sora产品也传出了新消息:
剪映旗下类似Sora的AI视频工具已经启动邀请内测。

看样子地基已经打好,那么对于字节的大模型产品,你期待吗?
论文地址:https://arxiv.org/abs/2402.15627
— 完 —
量子位 QbitAI · 头条号
关注我们,第一时间获知前沿科技动态签约
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成241632 电子证书1079 电子名片61 自媒体64547































