机器之心报道
编辑:小舟、泽南、大盘鸡
大模型也可解释了?
大模型都在想什么?OpenAI 找到了一种办法,能给 GPT-4 做「扫描」,告诉你 AI 的思路,而且还把这种方法开源了。

反问句:
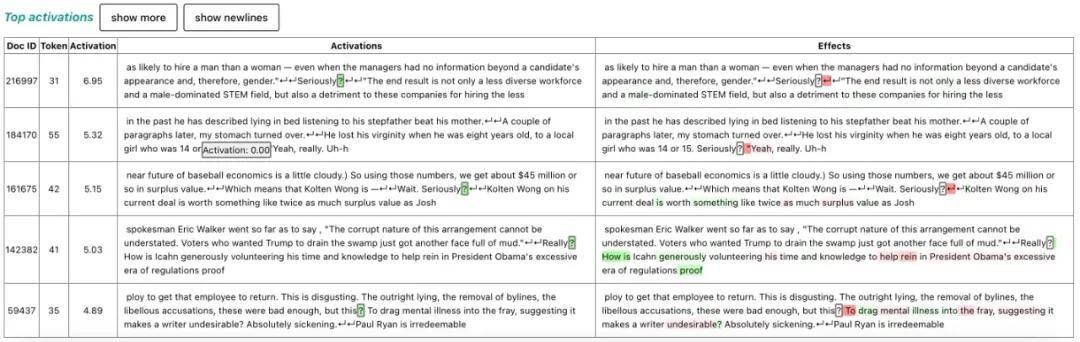
局限和发展方向
新方法能够提高模型的可信度和可操纵性。然而这仍是早期工作,存在许多局限性:
与此前的研究一样,许多发现的特征仍然难以解释,许多特征的激活没有明确的模式,或者表现出与它们通常编码的概念无关的虚假激活。此外,目前我们还没有很好的方法来检查解释的有效性。稀疏自动编码器不会捕获原始模型的所有行为。目前,将 GPT-4 的激活通过稀疏自动编码器大致相当于使用大约 1/10 计算量训练一个模型。为了完全映射前沿 LLM 中的概念,我们可能需要扩展到数十亿或数万亿个特征,即便使用改进的扩展技术,这也具有挑战性。稀疏自动编码器可以在模型中的某一点找到特征,但这只是解释模型的一步。还需要做更多的工作来了解模型如何计算这些特征以及如何在模型的其余部分下游使用这些特征。稀疏自动编码器的研究令人兴奋,OpenAI 表示,还有一些待解决的挑战。短期内,工程师们希望新发现的特征能够实际用于监控和控制语言模型行为,并计划在前沿模型中对此进行测试。希望最终有一天,可解释性可以为我们提供推理模型安全性和稳健性的新方法,并通过对 AI 行为提供强有力的保证,大幅提高我们对新一代 AI 模型的信任。
参考内容:
相关文章









关于作者

猜你喜欢
成员 网址收录40398 企业收录2981 印章生成236644 电子证书1047 电子名片60 自媒体48699































