对3Blue1Brown的「Transformers (how LLMs work) explained visually | DL5」笔记,以及一些自己的理解。
本来想写完所有参数,可是还需要看完两个视频,而且「Attention in transformers, visually explained | DL6」还有好多没看懂,根本做不了笔记。
算了,就先记Embeding和Umbedding吧。

GPT-3 总权重: 175,181,291,520;总矩阵: 27,938
Embedding Matrix:词汇表大小为 50,257,向量的维度为 12,288。那么 embedding matrix 的参数大小为 50,000 × 12,288,包含约 6.17 亿个权重。
embedding matrix 的作用是将词汇表中的每个 token 映射到一个高维向量空间。在初始化时,模型为 embedding matrix 中的每一行(每个 token)分配一个随机的向量。输入一个文本时,模型会根据该 token 在词汇表中的索引,查找到对应的词向量(即在 embedding matrix 中的某一行),这就是该 token 的初始表示。这个初始向量并不具备语义上的任何含义,它只是一个随机值。通过训练,模型会不断调整这些向量,使它们能更好地表达词语之间的语义关系。Unembedding Matrix:词汇表大小为 50,257,向量的维度为 12,288。那么 unembedding matrix 的参数大小为 50,000 × 12,288,包含约 6.17 亿个权重。
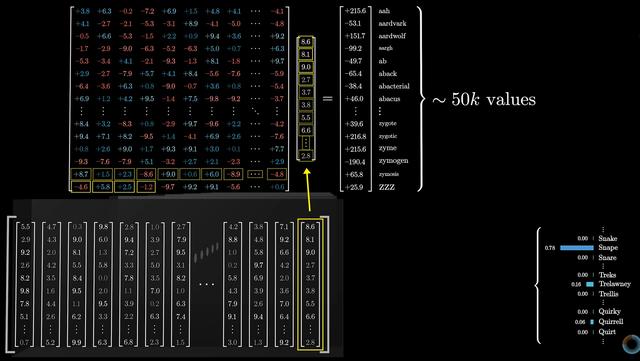 训练后的 unembedding matrix,每一行(对应词汇表的每个token)学会了表示这个token的特征。由于 Transformer 已经将整个上下文的信息都编码到上下文最后一个嵌入,所以只需使这个嵌入,通过 unembedding matrix 映射为词汇表的 logits,经归一化就能预测下一个词。
训练后的 unembedding matrix,每一行(对应词汇表的每个token)学会了表示这个token的特征。由于 Transformer 已经将整个上下文的信息都编码到上下文最后一个嵌入,所以只需使这个嵌入,通过 unembedding matrix 映射为词汇表的 logits,经归一化就能预测下一个词。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成241049 电子证书1067 电子名片60 自媒体64547































