编辑:编辑部 HYZ
【新智元导读】通义万相视频模型,再度迎来史诗级升级!处理复杂运动、还原真实物理规律等方面令人惊叹,甚至业界首创了汉字视频生成。现在,通义万相直接以84.70%总分击败了一众顶尖模型,登顶VBench榜首。
Sora、Veo 2接连发布之后,AI视频生成的战场又热闹了起来。
就在昨天,通义万相视频生成模型迎来了重磅升级!
他们一口气推出了两个版本:注重高效的2.1极速版、追求卓越表现的2.1专业版。
刚一上线,就异常火爆,等待时间甚至一度达到了1小时
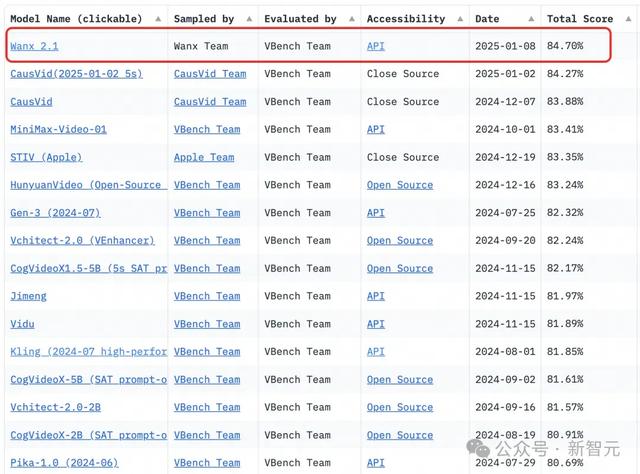
此次,全面升级的模型不仅在架构上取得创新,更是以84.70%总分登顶权威评测榜单VBench榜首。
通义万相2.1的性能一举超越了Gen-3、CausVid等全球顶尖模型。
在实用性方面,通义万相2.1也得到了显著的提升,尤其是在处理复杂运动、还原真实物理规律、提升影视质感、优化指令遵循等方面。
以下都是我们实测出的Demos,就说够不够拍电影大片吧!


更令人惊叹的是,它还在业界首次实现了中文文字视频生成,让AI视频文字创作再无门槛。

天空中飘着云朵,云朵呈现「新年快乐」的字样,微风吹过,云朵随着风轻轻飘动。

暴风雨中的海面,海王驾驭巨浪前行,肌肉线条,灰暗天空,戏剧性照明,动态镜头,粗犷,高清,动漫风格
实验室中女医生精心设计的特写镜头,细腻的表情刻画,以及背后灯光、实验器材等多种元素碰撞,让整个角色立即具备了丰富的层次感。

A fast-tracking shot down an suburban residential street lined with trees. Daytime with a clear blue sky. Saturated colors, high contrast
4. 真实的物理规律模拟AI视频模型不理解物理世界,一直以来饱受诟病。
比如,Sora不仅会生成8条腿的蚂蚁,而且眼瞧着手都要被切断了,也切不开西红柿, 而通义万相2.1切西红柿就像发生在现实生活中一样自然真实。

此外,万相2.1还能支持5种不同的长宽比——1:1, 3:4, 4:3, 16:9, 9:16,恰好可以匹配电视、电脑、手机等不同终端设备。
通义万相4D并行分布式训练策略
在显存优化上,采用了分层显存优化策略优化Activation显存,解决了显存碎片问题。
在计算优化上,使用FlashAttention3进行时空全注意力计算,并结合训练集群在不同尺寸上的计算性能,选择合适的CP策略进行切分。
同时,针对一些关键模块,去除计算冗余,使用高效Kernel实现,降低访存开销,提升了计算效率。
在文件系统优化上,结合了阿里云训练集群的高性能文件系统,采用分片Save/Load方式,提升了读写性能。
在模型训练过程中,通过错峰内存使用方案,能够解决多种OOM问题,比如由Dataloader Prefetch 、CPU Offloading 和 Save Checkpoint所引起的问题。
在训练稳定性方面,借助于阿里云训练集群的智能化调度、慢机检测,以及自愈能力,能在训练过程中实现自动识别故障节点并快速重启任务。
规模化数据构建管线与模型自动化评估机制规模化的高质量数据是大型模型训练的基础,而有效的模型评估,则指引着大模型训练的方向。
为此,团队建立了一套完整的自动化数据构建系统。
该管线在视觉质量、运动质量等方面与人类偏好分布高度一致,能够自动构建高质量的视频数据,同时还具备多样化、分布均衡等特点。
针对模型评估,团队还开发了覆盖多维的自动化评估系统,涵盖美学评分、运动分析和指令遵循等20多个维度。
与此同时,训练出专业的打分器,以对齐人类偏好,通过评估反馈加速模型的迭代优化。
AI视频生成下一个里程碑
去年12月,OpenAI和谷歌相继放出Sora、Veo 2模型,让视频生成领域的热度再一次升温。
从创业新秀到科技巨头,都希望在这场技术革新中寻找自己的位置。
但是相较于文本的生成,制作出令人信服的AI视频,确实是一个更具挑战性的命题。
Sora正式上线那天,奥特曼曾表示,「它就像视频领域的GPT-1,现在还处于初期阶段」。

若要从GPT-1通往GPT-3时刻,还需要在角色一致性、物理规律理解、文本指令精准控制等方面取得技术突破。
当AI真正打破现实创作的局限,赋予创意工作者前所未有的想象,新一轮的行业变革必将随之而来。
此次,通义万相2.1取得重大突破,让我们有理由相信,AI视频的GPT-3时刻正加速到来。
相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234174 电子证书1033 电子名片60 自媒体46877































