前段时间 OpenAI 发布了针对复杂推理问题的大模型——o1,也就是草莓模型。这款大模型一经发布就引起巨大的关注,但基本上都是关于使用和测评的。这篇文章,我们就来看看,o1模型的背后,其创新、原理分别是什么。

(ChatGPT访问量变化趋势,来源:tooltester)
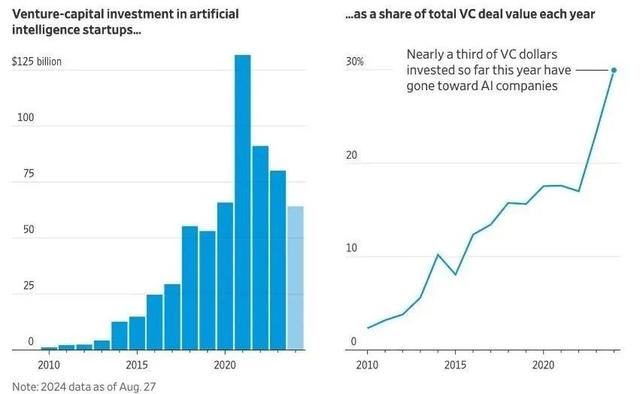
与此相对应的,一二级市场的AI热潮正在持续降温。
一级市场方面,VC资金对AI初创公司投资占比在持续上升,占比接近30%,但是在金额上已经回落到2020年的水平,降幅明显。
(AGI指数,来源:海外独角兽)
在这样的背景下,通过全新的大模型o1给投资人“画饼”成为了OpenAI绝佳的选择。
二、现象:o1模型的超强推理能力1. OpenAI的模型迭代史作为OpenAI在2023年GPT4发布以来最重要的模型更新,o1在数学、代码等方面推理能力显著提升。

(o1与gpt4o的对比,来源:OpenAI官网)
2.4 在启用视觉感知功能时,多模态o1在MMMU上得分为78.2%,成为第一个与人类专家竞争的模型。在博士级别的科学问题上,特别是物理和化学领域,o1更是大幅领先人类博士。
2.5 在IOI(国际信息学奥林匹克竞赛)中在每题 50 次提交的条件下取得了第 49%/213分。在每题10,000次提交的情况下,该模型的得分达到了362,超过了金牌门槛。

(系统1与系统2的对比,来源:简书)
5. 案例案例网上很多,这里只简单提下“草莓”这个最经典的案例。
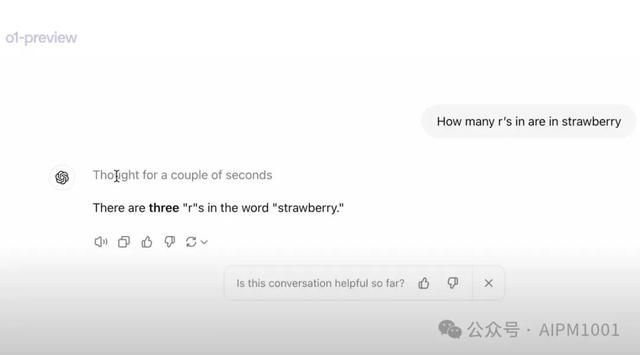
草莓的梗最初是因为人们测试GPT系列的时候,发现了模型无法数对草莓这个单词里面的r的数量。而OpenAI的新模型可以通过self-play的方式提升模型Reasoning的能力,从而数对r的数量。于是这个名叫草莓的模型就开始在网上不断发酵,并在Sam各种有意无意的暗示中升温。
 6. 业界关于o1模型的正负面观点
6. 业界关于o1模型的正负面观点6.1 正面观点
Jason Wei,OpenAI研究员,COT作者:
“通过将复杂步骤分解为更简单的步骤、识别和纠正错误,以及尝试不同的方法,o1 的表现完全令人惊叹,游戏规则已经被彻底重新定义。”

o1 模型的发布,意味着 AI 能力的提升不再局限于预训练阶段,还可以通过在 Post-Training 阶段中提升 RL 训练的探索时间和增加模型推理思考时间来实现性能提升,即 Post-Training Scaling Laws。
数据飞轮 Bootstrap -> SuperIntelligence : 基于自我反思的模型将能够实现自举 Bootstrap,并提升大大提升模型对于未见过的复杂问题的解决能力,模型的推理过程形成大量高质量数据的飞轮,并最终有可能向 SuperIntelligence 更进一步。
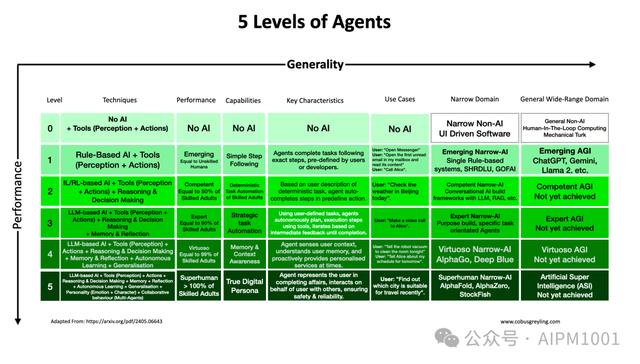
8.2 AI能力的等级跃迁
AI开始具备推理能力,且复杂问题的解决能力可以与人类相媲美,这意味着AI从仅能利用工具和规则的 Level 1 水平开始进化到了 Level 2 的阶段,并向第3阶段开始探索。
强化学习(Reinforcement Learning,RL)是一种基于反馈的学习方法,对算法执行的正确和不正确行为分别进行奖励和惩罚的制度,目的是使算法获得最大的累积奖励,从而学会在特定环境下做出最佳决策。“强化”一词来自于心理学,心理学中的“强化”就是通过提供一种刺激手段来建立或者鼓励一种行为模式。这种“强化”具体分为两种:
积极强化,是指在预期行为呈现后,通过给予激励刺激以增加进一步导致积极反应。
负面强化,通过提供适当的刺激来减少出现负面(不希望的)反应的可能性,从而纠正不希望出现的行为。
想象一下,当你第一次自己玩超级马里奥,你需要在游戏中不断探索环境和重要的NPC,一个错误的举动会导致失去一条“命”,一个正确的跳跃可以把我们带到一个更安全的地方获得金币奖励!在n次奖励和惩罚的探索之后,你对于马里奥游戏的熟练程度越来越高,操作的正确性大大提升,最终成为一个该游戏的高手。
1.2 Self-play
Self-play 是 AlphaZero 等强化学习算法的合成数据方法,最早可以追溯到 1992 年的 TD-Gammon 算法,其本质是利用 AI 无限的计算能力来补足它数据利用效率不够的短板。
以 AlphaZero 为例,在每一局对弈中,模型使用蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)来选择动作。MCTS 结合了当前神经网络提供的策略(policy)和价值(value),从而在每个游戏状态下评估出最优的行动。其具体步骤如下:
1) 随机初始化:模型从完全随机初始化的状态开始,没有任何人类先验知识。
2) self-play:模型自己与自己进行对弈,生成大量的游戏数据。其中好的结果用于更新模型的参数。
3) MCTS:在每一次对弈中,AlphaZero 会使用 MCTS 来搜索最佳动作。MCTS 使用策略网络 (policy network) 提供的动作概率分布和价值网络提供的局面评估结果来引导搜索。
4) 策略更新:根据自我对弈的结果,使用强化学习的方式来更新神经网络的参数,使得模型逐步学习到更优的策略
1.3 Self-play强化学习、RLHF
早在2018 年,Ilya Sutskever就认为强化学习与 self-play 是通往 AGI 路上最关键的方法之一。Ilya 用一句话概括了强化学习:让 AI 用随机的路径尝试新的任务,如果效果超预期,那就更新神经网络的权重,使得 AI 记住多使用这个成功的事件,再开始下一次的尝试。
1)传统强化学习与self-play的区别:传统强化学习与今天的 self-play 强化学习相比,最大的区别是强化学习算法模型(如AlphaZero)是一个千万参数的神经网络,和今天的语言模型相差 3-4 个数量级。
2)Self-play 强化学习与RLHF 的区别:RLHF 的目的不是获取机器智能,而是人机对齐,使得 AI 能够更像人,但不能超越人成为超级智能。简单来说:RLHF 像人类一样,更喜欢好理解的东西,而不是喜欢逻辑更严密的内容。而 self-play 强化学习的目标是如何提升逻辑能力,绝对强度更高,甚至超越最强人类、专家。
3)RLHF 的核心是通过强化学习训练语言模型,但由于缺乏奖励函数这一必要因素,因此需要通过收集人类的反馈来学习一个奖励函数。
4)强化学习不是一个模型,而是一整套的系统,其中包含了很多因素,第一,强化学习包括了智能体,其中的 agent 就是模型。第二,包括了环境,环境可能是狗主人的家,也可能是编程环境,也可能是垂直领域。第三,包括了动作,是狗坐下,还是一些其他模态的输出。第四,包括了奖励模型,这也很重要。最重要的两个因素是环境和智能体。智能体的目标是得到更多奖励。

(o1可能的架构图,来源:https://www.reddit.com/r/LocalLLaMA/comments/1fgr244/reverse_engineering_o1_architecture_with_a_little/)
下面是关于这张架构图的详细说明,主要包括四个阶段:
4.1 数据生成
数据生成模块负责创建用于训练的数据,包括:
合成数据生成器(Synthetic Data Generator)、人类专家、CoT数据库(CoT Dataset,链式思维数据库)、现实世界和沙盒数据
这些数据被汇集起来,形成训练数据,用于后续模型的训练阶段。
4.2 训练阶段
训练阶段主要由以下几个模块组成:
语言模型,这是核心的AI模型,负责处理和理解语言数据。
RL环境,强化学习环境用于模型优化。
奖励函数,包括验证(Verification)和人类反馈(Human labeling),用来指导模型学习。
策略优化器(Policy Optimizer),包括梯度压缩、Panzar系统、探索与利用等,用于优化模型策略。在这个阶段,模型通过强化学习和高级技术进行训练,不断优化性能和效率。
4.3 推理阶段
推理阶段包括:
训练好的模型,这是通过强化学习和高级技术优化后的模型。
多任务生成,处理多个任务的能力。
最终响应,生成最终的输出结果。
CoT生成和微调,根据链式思维生成并微调结果。
效率监控:实时监控模型的性能。
4.4 关键注释
大规模CoT存储进入RL环境是作者自己的假设,作者认为OpenAI可能会使用从现实世界中生成的大量链式思维来进一步调整和优化RL模型。举例说明:假设你是一名研究员,想要构建一个能够进行多任务处理的AI系统。
我们可以通过参考这个o1架构按照上面三个模块进行以下工作:
1)首先,收集并生成各种类型的数据,包括合成数据、人类专家提供的数据以及现实世界的数据。
2)接着,利用这些数据训练你的语言模型,并在强化学习环境中进行优化,通过奖励函数和策略优化器不断提升模型性能。
3)最后,将训练好的模型部署到推理阶段,使其能够处理多任务并生成最终响应,同时监控其效率并进行必要的微调。这种架构不仅适用于语言处理,还可以扩展到其他领域,如图像识别、游戏开发等,通过不断优化强化学习过程,使得AI系统更加智能高效。
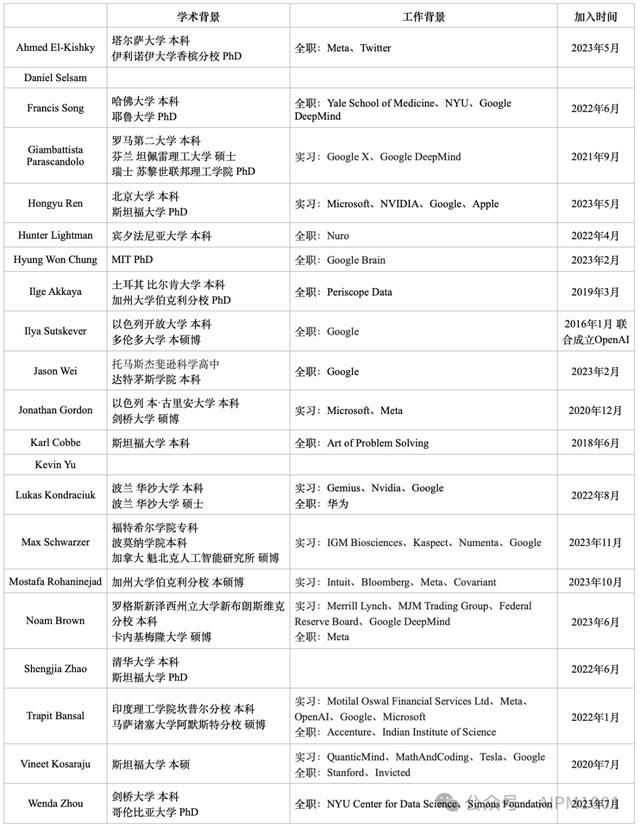
四、幕后:o1背后的团队在 OpenAI 公布的o1模型的参与人员中,不仅包括前首席科学家Ilya Sutskever,COT 作者 Jason Wei,还包含了Jiayi Weng等大量华人科学家。
在o1 的21个Foundational贡献者呈现出了高学历、高包容性、多元化、国际化等特点。
学术背景:14人拥有博士学位,3人以本科学位进入OpenAI,1人有专科经历,5人有斯坦福背景;国家背景:团队来自至少8个国家,包括美国、中国、印度、韩国、意大利、土耳其、以色列、波兰,呈现出了高度的国际化。其中以色列2人。华人贡献:作为人数最多的国家之一,6个华人本科分别来自清华、北大、剑桥、哈佛、达特茅斯。从某种程度上来说,OpenAI 在AI技术上的领先离不开华人的贡献。工作背景:作为OpenAI最主要的竞争对手,贡献者中11人有 Google 背景,5人没有相关名企经验;注:2人未找到相关资料。
21个Foundational贡献者资料明细
 五、相关名词解释1. MCTS
五、相关名词解释1. MCTS1.1 概念:蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一种用于某些类型决策过程的启发式搜索算法,特别是在双人零和游戏中。它结合了蒙特卡洛模拟的随机抽样和决策树搜索的系统性。MCTS在计算博弈论和人工智能领域中非常有用,尤其是在围棋、国际象棋和其他策略游戏中。
1.2 MCTS的基本步骤
1)选择:从根节点开始,按照特定的策略,选择最有前途的子节点,直到到达一个尚未完全展开(即还有未探索的行动)的节点。
2)扩展:在选择的节点上添加一个或多个子节点,这些子节点代表了可能的下一步行动。这涉及到游戏状态的更新,将游戏向前推进到一个新的状态。
3)模拟:从新添加的节点开始,进行蒙特卡洛模拟,直到游戏结束或达到预定的模拟深度。这个过程不需要完美信息,可以使用随机策略来选择行动。
4)反向传播:将模拟的结果(比如输赢或得分)更新到所访问路径上的所有节点。如果模拟结果是胜利,则增加沿途节点的胜利次数;如果是失败,则相应地更新失败的统计数据。
1.3 关键特点
1)自适应搜索:MCTS能够根据之前的搜索结果自适应地搜索那些更有希望的区域。
2)无启发式:与某些其他搜索算法不同,MCTS不需要领域特定的启发式评估函数。
3)并行化:模拟步骤可以独立进行,因此MCTS很容易并行化,这使得它在多核处理器上特别有效。
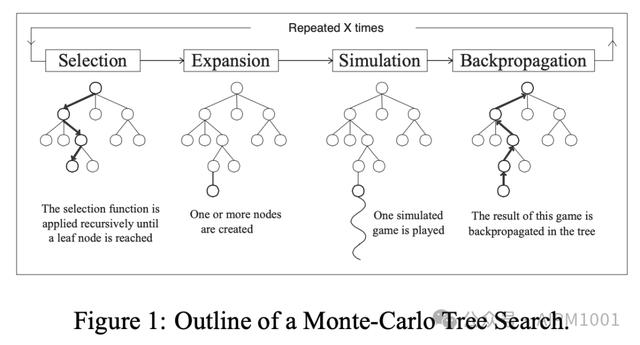
1.4 Beam Search、Lookahead Search、MCTS对比
Beam Search:一种启发式的图搜索算法,常用于机器翻译、语音识别等领域的解码过程。它在每一步都从当前节点扩展出一定数量(beam width)的最有前途的子节点,而不是搜索所有可能的子节点,从而减少了搜索空间。
Beam Search的优点是计算效率高,但缺点是可能会错过一些不那么显而易见但最终可能更优的路径。
Lookahead Search:一种在Beam Search基础上的扩展,它在搜索时不仅考虑当前步骤的最优解,还会向前看多步,考虑未来的可能性。这种搜索策略可以帮助算法做出更长远的决策,但计算成本也会随之增加。
Lookahead Search的关键在于它尝试预测并评估不同的决策路径,从而选择最优的行动方案。
MCTS:一种用于某些类型决策过程的启发式搜索算法,它结合了随机模拟和决策树搜索。MCTS通过多次模拟来评估不同的决策路径,并根据这些模拟的结果来选择最优的行动。
MCTS特别适用于双人零和游戏,如围棋、国际象棋等,它通过构建整个树来探索所有可能的行动路径,并通过模拟来评估这些路径。
2. Bootstrap这是一种重采样技术,用于从原始数据集中生成新的样本集,以此来估计一个统计量(如均值、方差等)的分布。通过这种方法,可以不需要对总体分布做出任何假设,就能够估计出模型参数的不确定性和稳定性。
Bootstrap方法的步骤通常包括:从原始数据集中随机抽取样本,允许重复抽样(即有放回抽样);根据抽取的样本计算所需的统计量;重复上述过程多次(通常是数千次),以获得统计量的分布;使用这个分布来估计原始统计量的标准误差、置信区间或其他特征。
在机器学习领域,Bootstrap方法可以用来提高模型的泛化能力和鲁棒性。例如,通过Bootstrap抽样可以创建多个不同的训练集,然后用这些训练集来训练多个模型。这些模型可以结合起来,形成一个集成模型,如随机森林或Bagging模型,以此来减少过拟合和提高模型的预测准确性。
3. PPOPPO(Proximal Policy Optimization,近端策略优化)是一种在强化学习领域广泛使用的算法,它属于策略梯度方法的一种。PPO算法的核心思想是在每次更新策略时,限制新策略与旧策略之间的差异,以保持训练过程的稳定性。
PPO算法有两个主要变体:PPO-Penalty和PPO-Clip。PPO-Penalty通过在目标函数中添加一个惩罚项来近似解决一个KL散度约束的更新问题,而PPO-Clip则不直接使用KL散度项,而是通过目标函数中的裁剪操作来限制新旧策略之间的差异。
PPO算法的实现步骤通常包括:
1)初始化策略网络参数。
2)通过与环境交互收集数据。
3)计算优势函数,用于评价动作的好坏。
4)使用裁剪的目标函数或惩罚项来更新策略网络参数。
5)重复以上步骤,直到策略收敛。
PPO算法的优点包括稳定性、适用性和可扩展性。它适用于离散和连续动作空间的环境,并且可以通过并行化来提高训练效率。PPO算法在游戏、机器人控制、自动驾驶等领域都有广泛的应用。
4. 激活学习激活学习是一种机器学习方法,其核心思想是选择最有价值的数据进行标注和学习,从而提高学习效率和模型性能。
通常用于以下场景:数据标注成本高、数据集规模庞大、模型性能提升空间有限。
包括以下几个步骤:选择标注策略、选择标注数据、标注数据、训练模型、迭代优化。
在许多领域都有广泛应用,例如图像识别、自然语言处理、推荐系统。
参考资料:Open AI官网:
1、https://openai.com/index/introducing-openai-o1-preview/
2、https://openai.com/index/learning-to-reason-with-llms/
3、https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/#model-speed
OpenAI o1、核心成员官推:OpenAI 官推、CEO Sam Altman、总裁&联创Greg Brockman、COT 作者Jason Wei、模型核心成员Noam Brown、Hyung Won Chung、Ahmed El-Kishky、Ren HongYu、ShenJia Zhao
公众号:海外独角兽、 FudanNLP、机器之心、 量子位、数字生命卡兹克、 AI Pioneer、 AI产品黄叔、人工智能与算法学习、AINLP、腾讯科技、 GitChat、AI科技大本营、智能涌现、PaperWeekly、硅谷科技评论、卜寒兮AI、zartbot、投资实习所、AI的潜意识、夕小瑶科技说
作者:AIPM1001 ,公众号:AIPM1001
本文由 @AIPM1001 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
相关文章









关于作者

猜你喜欢
成员 网址收录40396 企业收录2981 印章生成236444 电子证书1045 电子名片60 自媒体48062































