当地时间周五,美国总统特朗普会见了英伟达 CEO 黄仁勋,两人讨论了 DeepSeek 和 AI 芯片出口等问题。美国立法者们也已敦促特朗普考虑对 DeepSeek 使用的英伟达芯片进行新的限制。
与此同时,美国正在调查 DeepSeek 是否通过位于新加坡的半导体公司使用了英伟达禁用芯片。目前,美国五角大楼已经开始封锁使用 DeepSeek,美国海军则在上周就已禁用 DeepSeek。
绕开人工反馈来训练模型
大模型的训练过程主要分为两个阶段:预训练和后训练。预训练也是业内人士谈论最多的阶段。在此过程中,来自大量网站、书籍和代码库等的数十亿份文档,被反复输入到神经网络之中。这一过程往复循环,直到模型学会逐字逐句地生成与源材料相似的文本,通过这一阶段得到的模型被称为基础模型。
预训练阶段蕴含了大模型研发的大部分工作量,所以它可能会花费大量资金。但正如 OpenAI 联合创始人、特斯拉前 AI 负责人安德烈·卡帕斯(Andrej Karpathy)于 2024 年在微软 Build 大会上所讲的:“基础模型不是助手,它们只是在完成互联网文档而已。”
将大模型转化为真正有用的工具,还需要许多额外的步骤。这些步骤都发生在后训练阶段,在此期间模型需要学习执行特定任务,比如学习回答问题或学习逐步回答问题。过去几年业内的做法是,采用一个基础模型并对其进行训练,借此模仿大量人类测试员提供的问答示例,这一步也被称为“有监督微调”。
后来,OpenAI 开创了另一个技术,即对模型中的样本答案进行评分,当然这里同样是由人类测试员进行评分,并由人类测试员使用这些分数来训练模型,以便让所生成的答案更加接近得分高的答案,该技术的名字叫做人类反馈强化学习(RLHF,reinforcement learning with human feedback),正是这种技术让 ChatGPT 等聊天机器人得以如此好用。而在目前,RLHF 已经在整个行业中得到普及。
但是,后训练需要花费一定时间。而 DeepSeek 表明,在不使用监督微调和 RLHF 的情况下也能获得相同的结果。具体来说,DeepSeek 使用完全自动化的强化学习步骤取代了监督微调和 RLHF。同时,DeepSeek 没有使用人类反馈来指导其模型,而是使用计算机产生的反馈分数。
“跳过或减少人类反馈这是一件大事,”阿里巴巴前研究总监、以色列 AI 编码初创公司 Qodo 的联合创始人兼 CEO 伊塔马尔·弗里德曼(Itamar Friedman)说,“这几乎完全是在脱离了人工反馈的情况下训练模型。”
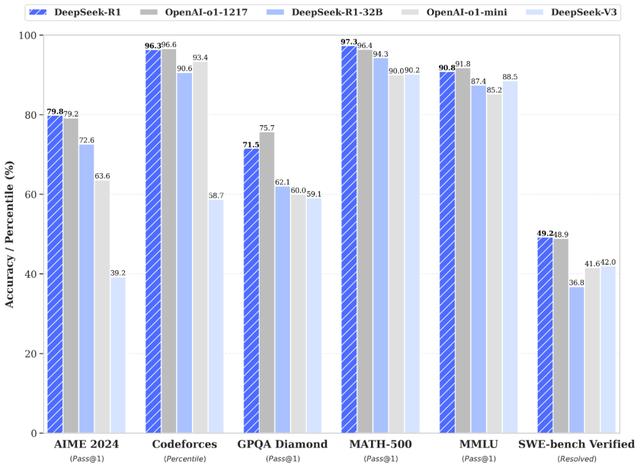
不过,上述方法的缺点是模型确实更加擅长对数学问题和代码问题的答案进行评分,但是不太擅长对开放式问题或更主观的问题进行评分。这也是为什么 DeepSeek 的 R1 模型能在数学测试和代码测试中取得佳绩的原因。

便宜、但却依然足够准确
事实上,为了让其模型能够回答更多的非数学问题或执行创造性任务,DeepSeek 仍然依赖真人来提供反馈。澳大利亚 AI 公司 Appen 副总裁、曾担任 AWS 中国和腾讯公司战略主管的 Si Chen 表示:“相对于西方国家,中国创建高质量数据的成本较低,而且拥有数学、编程或工程领域的大学学历的人才库更大。”
一个月前,DeepSeek 发布了 V3 模型,其能媲美 OpenAI 的旗舰模型 GPT-4o。DeepSeek 于上周发布的 R1,正是基于 V3 打造而来。同时,R1 也是一款能与 OpenAI o1 模型相媲美的推理模型。
为了构建 R1,DeepSeek 在 V3 的基础上一遍又一遍地运行强化学习循环。2016 年,谷歌 DeepMind 在 AlphaGo 上展示了这种无需人工输入的自动试错方法,起初 AlphaGo 只能在棋盘上随机移动棋子,但通过使用上述方法它最终得以击败国际象棋大师。
而 DeepSeek 对大模型做了类似的事情:将潜在答案视为游戏中可能的动作。需要说明的是,模型肯定无法一步步地给出问题的答案。但是,通过针对模型的样本答案进行自动评分,训练过程会逐渐将模型推向“期望之地”。
通过此,DeepSeek 打造出一款名为 R1-Zero 的模型,它在多个基准测试中均有良好表现。但是,R1-Zero 给出的答案很难阅读,而且是使用多种语言混合编写而来。
为了进行最后的调整,DeepSeek 使用一小组由真人提供的示例答案作为强化学习过程的种子,并使用这些答案来训练 R1-Zero 最终借此生成了 R1 模型。
而为了尽可能高效地利用强化学习,DeepSeek 还开发出一种名为“组相对策略优化”(GRPO,Group Relative Policy Optimization)的新算法。一年前,它首次使用 GRPO 构建出一款名为 DeepSeekMath 的模型。
对于强化学习来说,其通过计算分数来确定潜在行动到底是好是坏。很多强化学习技术都需要一个完全独立的模型来进行这种计算。对于大模型来说,这意味着要构建第二个模型,而第二个模型的运行成本可能与第一个模型同样高。但是,有了 GRPO 就无需使用第二个模型来预测分数,而是能够做出有根据的猜测。尽管这种做法很便宜,但却足够准确。

更省钱地打造数据集,更省钱地使用芯片
在 R1 的论文中,DeepSeek 介绍称 R1 的主要创新在于使用了强化学习。不过,DeepSeek 并不是唯一一家尝试这种技术的公司。在 R1 面世的两周前,微软亚洲研究院团队推出一款名为 rStar-Math 的模型,该模型使用和 DeepSeek 类似的方式进行训练。AI 公司 Clarifai 的创始人兼 CEO 马特·泽勒(Matt Zeiler)表示:“它的性能同样有巨大的飞跃。”
(来源:DeepSeek)
AI2 的 Tulu 模型也是使用强化学习技术构建而来,但其建立在监督微调和 RLHF 等人类主导的步骤之上。美国开源平台 Hugging Face 正在努力使用 OpenR1 来复制 R1,并以此来作为 DeepSeek 模型的克隆体。同时,Hugging Face 希望借此能够揭示 R1 的更多秘诀。
更重要的是,OpenAI、谷歌 DeepMind 和 Anthropic 等顶级公司可能已经在使用类似 DeepSeek 的方法来训练新一代模型,这是一个公开的秘密。泽勒说:“我相信他们做的几乎完全一样,但他们会有自己的风格。”
不过,DeepSeek 的诀窍不止这一个。它通过训练来让其基础模型 V3 来执行一种名为多标记预测(multi-token prediction)的任务。通过这种训练,模型可以学会一次预测一串单词,而非只能一次预测一个单词。
这种训练不仅更便宜,同时也能提高准确性。泽勒说:“如果你考虑一下你的说话方式,你会发现当你说完一个句子的一半时,你就知道句子的其余部分会是什么。”“(DeepSeek 的)这些模型应该也能做到这一点。”
DeepSeek 还找到了创建大型数据集的更省钱方法。2024 年,为了训练模型 DeepSeekMath,其采用一款名为 Common Crawl 的免费数据集(该数据集从互联网上抓取了大量文档),并使用自动化流程来提取包含数学问题的文档。
这种方法比手动构建新的数学问题数据集的方法要便宜得多。同时它也更有效,原因在于 Common Crawl 所包含的数学知识比任何其他可用的专业数学数据集都要多得多。
在硬件方面,DeepSeek 找到了让旧芯片焕发活力的新方法,这让其无需花钱购买市面上最新的硬件就能训练顶级模型。泽勒说,DeepSeek 的创新有一半来自工程:他们的团队中肯定有一些非常非常优秀的 GPU 工程师。
通常来讲,英伟达在为用户提供芯片的同时,还会提供名为 CUDA 的软件。工程师们在使用芯片的时候,需要使用 CUDA 来调整芯片设置。但是,DeepSeek 使用汇编器绕过了 CUDA,汇编器是一种能与硬件直接对话的编程语言,它所提供的功能远远超出英伟达所提供的开箱即用功能。泽勒说:”这是优化这些东西的核心。”“技术上这是可行的,但这太难了,几乎没有人能做到。”
桥水基金创始人兼 CEO 瑞·达利欧(Ray Dalio)在一档采访节目中表示,中国使用擅长非常便宜的芯片,然后在里面嵌入制成品,从而将芯片性能发挥到极致,其还认为英伟达等公司正在面临风险。
上个月,DeepSeek 声称其模型所使用的计算能力大约是 Meta 的 Llama 3.1 模型的十分之一。如此之小的耗能,几乎颠覆了人们的认知。当前,科技巨头正在争相建设大型 AI 数据中心,预计一些数据中心的用电量与一座小城市相当。
使用如此多电力肯定会造成环境污染,这也引发了人们对于 AI 数据中心可能会加剧气候变化担忧。那么,只要能够减少 AI 模型的耗电量,就能缓解上述压力。不过,DeepSeek 的训练方式是否会改变 AI 碳足迹,目前还不宜过早下判断,但它依然让人们看到了减少 AI 耗能的曙光。

靠硬件堆算力的时代逐渐进入尾声
Hugging Face 的研究员刘易斯·滕斯托尔(Lewis Tunstall)说:“R1 表明,有了足够强大的基础模型,强化学习就足以在没有任何人工监督的情况下从语言模型中得出推理能力。”
换句话说,美国顶级公司可能已经想出了如何做到这一点,但却保持沉默。“似乎有一种巧妙的方法可以把基础模型和预训练模型变成一个更强大的推理模型,”泽勒说,“截至目前,将预训练模型转换成推理模型所需的工作并不为人所知。它没有得到公开。”
R1 的不同之处在于 DeepSeek 公布了他们是如何做到的。“事实证明,这个过程并没有那么昂贵。”泽勒说,“最困难的部分在于首先要获得预训练模型。”正如安德烈·卡帕斯(Andrej Karpathy)于 2024 年在微软 Build 大会上透露的那样,预训练模型占据 99% 的工作和大部分成本。
如果建立推理模型并不像人们想象得那么困难,那么我们就可以期待大量免费模型的出现,并且它们的功能远比我们迄今所见的更加强大。阿里巴巴前研究总监、以色列 AI 编码初创公司 Qodo 的联合创始人兼 CEO 伊塔马尔·弗里德曼(Itamar Friedman)认为,随着 Know- How 技术的公开,小公司之间将拥有更多的合作,从而能够削弱大公司所享有的优势。
伊塔马尔·弗里德曼(Itamar Friedman)说:“我认为这可能是一个具有里程碑意义的时刻。”同时也正如网友“诗与星空”所言:“随着 DeepSeek 的出现,靠硬件堆算力的时代逐渐进入了尾声,通过技术优化大模型(来)减少硬件依赖(的)这条路,才刚刚开始。”
参考资料:
https://www.theverge.com/climate-change/603622/deepseek-ai-environment-energy-climate
https://techcrunch.com/2025/01/31/hundreds-of-companies-are-blocking-deepseek-over-china-data-risks/
https://semianalysis.com/2025/01/31/deepseek-debates/
https://www.zhihu.com/question/10956652646/answer/90118662962
运营/排版:何晨龙
相关文章







关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成244355 电子证书1088 电子名片62 自媒体73828































