编辑:编辑部
【新智元导读】刚刚,DeepSeek的GitHub星数,超越了OpenAI!V3的Star数,如今已经碾压OpenAI最热门的项目。机器学习大神的一篇硬核博文,直接帮我们揭秘了如何仅用450美元,训出一个推理模型。
就在刚刚,历史性的一刻出现了。
DeepSeek项目在GitHub平台上的Star数,已经超越了OpenAI。
热度最高的DeepSeek-V3,Star数如今已达7.7万。
Sebastian表示,很多人都来询问自己对DeepSeek-R1的看法。
在他看来,这是一项了不起的成就。
作为一名研究工程师,他非常欣赏那份详细的研究报告,它让自己对方法论有了更深入的了解。
最令人着迷的收获之一,就是推理如何从纯强化学习行为中产生。
甚至,DeepSeek是在MIT许可下开源模型的,比Meta的Llama模型限制更少,令人印象深刻。
在本文中,Sebastian介绍了构建推理模型的四种方法,来提升LLM的推理能力。
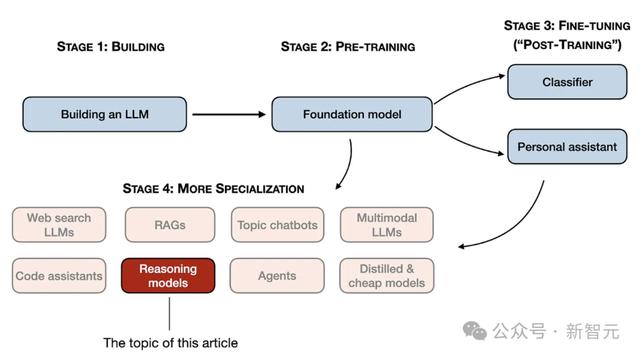
为什么开发蒸馏模型?可能有两个关键原因:
1 较小的模型更高效。小模型运行成本更低,还能在配置较低的硬件上运行。对研究人员来说很有吸引力。
2 纯SFT的案例研究。这些模型展示了在没有RL的情况下,单纯靠SFT能把模型优化到什么程度。

接下来一个有趣的方向是把RL SFT和推理时扩展结合起来,OpenAI的o1很有可能是这样做的,只不过它可能基于一个比DeepSeek-R1更弱的基础模型。
R1和o1相比如何?
Sebastian认为,DeepSeek-R1和OpenAI o1大致在同一水平。
不过引人注目的一点是,DeepSeek-R1在推理时间上更高效。
这就揭示了二者的区别:DeepSeek可能在训练过程中投入了更多,而OpenAI更依赖于o1的推理时扩展。
而很难直接比较两个模型的难点,就在于OpenAI并没有披露太多关于o1的信息。
现在关于o1,还有很多未解之谜。
比如,o1也是一个MoE吗?它究竟有多大?
或许,o1只是GPT-4o的一个略微改进版本,加上最小量的强化学习和微调,仅在推理时进行大规模scaling?

不了解这些细节,是很难直接比较的。
预算只有几十万美元,能开发推理模型吗
不过,想开发一个DeepSeek-R1这样的推理模型,哪怕是基于开放权重的基础模型,也可能需要几十万美元甚至更多资金。
这对预算有限的研究人员或工程师来说,实在是望而却步。
好消息是:蒸馏能开辟新路径!
模型蒸馏提供了一个更具成本效益的替代方案。
DeepSeek团队的R1蒸馏模型证明了这一点,尽管这些模型比DeepSeek-R1小得多,推理表现却强得惊人。
不过,这种方法也不是完全没有成本。他们的蒸馏过程用了80万条SFT样本,这需要大量的计算资源。
有趣的是,就在DeepSeek-R1发布的前几天,关于Sky-T1的文章中,一个团队用1.7万条SFT样本,就训练出了一个32B参数的开放权重模型。
总成本仅有450美元,甚至比大多数人AI会议的注册费还低。
Sky-T1的表现和o1大致相当,考虑到它的训练成本,着实令人惊叹。
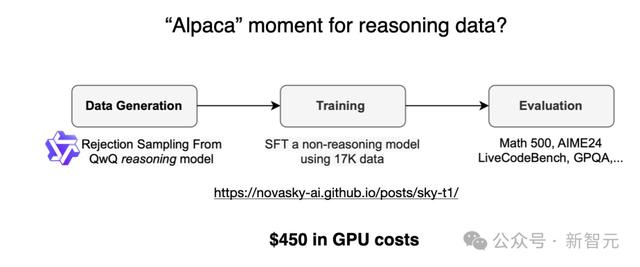
项目链接:https://novasky-ai.github.io/posts/sky-t1/
预算有限的纯强化学习:TinyZeroTinyZero是3B参数的模型,它借鉴了DeepSeek-R1-Zero的方法,其训练成本不到30美元。
令人意外的是,尽管只有3B参数,TinyZero仍展现出一些突现的自我验证能力,这证明了小模型通过纯RL也能产生推理能力。

这两个项目表明,即使预算有限,也可以进行有趣的推理模型研究。
两者都借鉴了DeepSeek-R1的方法,一种聚焦于纯RL(TinyZero),另一种聚焦于纯SFT(Sky-T1)。
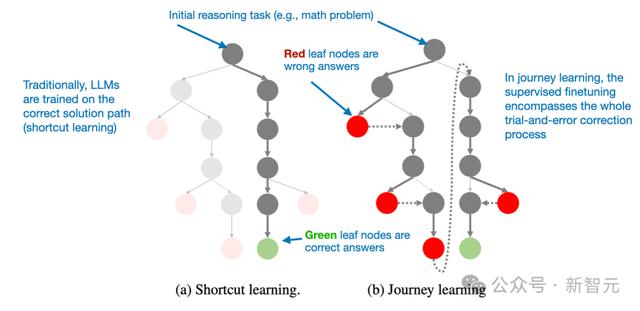
超越传统SFT:旅程学习旅程学习被视作捷径学习的替代方案。捷径学习是传统的指令微调方法,模型仅通过正确的解题路径来训练。
旅程学习不仅包括正确的解题路径,还包括错误的解题路径,让模型从错误中学习。
这种方法和TinyZero在纯RL训练中展现的自我验证能力有相通之处,不过它完全依靠SFT来优化模型。让模型接触错误推理路径及修正过程。
旅程学习或许有助于加强自我纠错能力,提升推理模型的可靠性。
论文链接:https://arxiv.org/abs/2410.18982
这一方向对于未来的研究极具吸引力,特别是在低预算的推理模型开发场景中,RL方法可能由于计算成本过高而难以落地。
当前在推理模型领域正有诸多有趣的研究,Sebastian充满期待地表示:相信在未来几个月,还会看到更多令人兴奋的成果!
相关文章









关于作者

猜你喜欢
成员 网址收录40398 企业收录2981 印章生成236772 电子证书1047 电子名片60 自媒体48699































