在人工智能的浪潮中
DeepSeek无疑是一颗最耀眼的新星
没有之一
直到现在热度依旧不减
反而越来越多的行业、企业纷纷选择接入
腾讯和百度两家巨头
都决定“打不过就加入”
从手机厂商再到汽车厂商
甚至各地的政府系统
也都纷纷接入DeepSeek
这场现象级爆火的背后
是DeepSeek
以“高性能、低成本、全开源”三大优势
直接捅破了硅谷巨头构建的技术护城河
使其在竞争激烈的AI领域脱颖而出
接下来我们带你一起探究一下

国产AI的“技术突围”
DeepSeek的能力相当惊艳
实现了比肩
甚至超越GPT-4o、Claude-3.5等
顶尖闭源模型的性能
数学推理、编程能力、
中文任务处理等方面的表现
可谓是出类拔萃
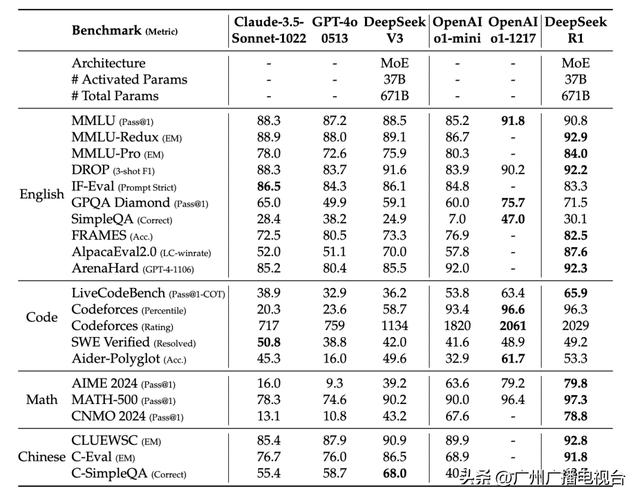
DeepSeek-R1 与其他代表性模型的比较
在数学推理领域,它就像是一位顶级的数学家,能够轻松应对各种复杂的数学问题。在面对一些高难度的数学竞赛题目时,DeepSeek能够迅速理清思路,准确地解答,其准确率甚至超过了一些同类型的知名模型。在2024年AIME(美国数学邀请赛)测试中取得79.8%的成绩,略高于OpenAI o1的79.2%。
在编程领域,该模型在Codeforces平台上获得了2029的评分,超过了96.3% 的人类程序员,与o1-1217的2061评分仅有小幅差距。
DeepSeek在中文任务处理上更是展现出了独特的优势。由于它在训练过程中充分学习了大量的中文语料,对中文的语言习惯、语义理解有着深刻的把握。在处理中文文本时,它能够准确理解文本中的含义,生成自然流畅、符合语境的回复。无论是进行文本翻译、文章创作,还是智能客服等应用场景,DeepSeek 都能以出色的表现满足用户的需求,在C-Eval和C-SimpleQA等中文任务中表现突出,展现出了比许多西方开源模型更好的性能。
之所以DeepSeek
可以从众多模型之中异军突起
是因为它不仅率先实现了
与OpenAI-o1等顶尖模型不相上下的效果
更是将训练成本压缩到了极低
震惊业界
打破行业成本壁垒
据科技日报报道,AI公司通常使用装有1.6万枚或更多专用芯片的超级计算机来训练聊天机器人,但深度求索公司表示,他们只用了大约2000枚芯片。同时,他们仅花了不到600万美元就训练了新模型,成功在两方面把构建AI的价格“打了下来”。
DeepSeek创始人梁文锋
曾在接受媒体采访时表示
无论是API还是AI
都应该是普惠的、
人人可以用得起的东西
在DeepSeek-V3和R1模型之前,大模型行业信奉“算力即权力”的逻辑。
这种现象的背后,本质上就是OpenAI、谷歌、Meta等巨头用天价算力筑起护城河,它们大量囤积算力资源,利用自身雄厚的资金实力和技术优势,在人工智能领域形成了近乎垄断的地位。由于高端芯片缺乏和算力成本高昂,很多企业在算力获取上举步维艰,发展处处受限。
而DeepSeek的火爆,证明了还有另外一种取胜之道:通过改进AI模型的基础架构并更高效地利用有限资源。这大幅降低了大模型的门槛,为行业发展带来了更多的可能性。
DeepSeek让大家更清晰意识到,在智能时代,最具决定性的资源并非芯片,而是人的创造力。
如果说“大力出奇迹”
那么DeepSeek证明
小力也可以出奇迹
DeepSeek R1
通过较少算力实现高性能模型表现
主要原因是DeepSeek R1
实现算法、框架和硬件的优化协同
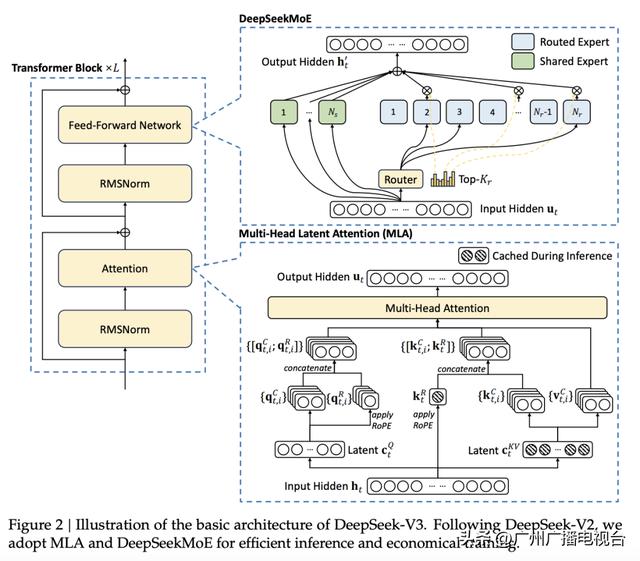
DeepSeek-V3架构图
DeepSeek R1在诸多维度上进行了大量优化,算法层面引入专家混合模型、多token预测,框架层面实现FP8混合精度训练,硬件层面采用优化的流水线并行策略,同时高效配置专家分发与跨节点通信,实现最优效率配置。
技术架构创新领先
传统AI模型不管干啥都得把所有能力都用上,就像一个 “全科医生”,不管是治感冒还是做复杂手术,都得把自己所有本事拿出来,特别浪费精力。但DeepSeek R1采用的混合专家架构(Mixture of Experts,MoE)彻底改变了这一模式,MoE架构就像是一个由众多专家组成的智慧团队,每个专家都在自己擅长的领域有着独特的专长,负责处理特定类型的任务。
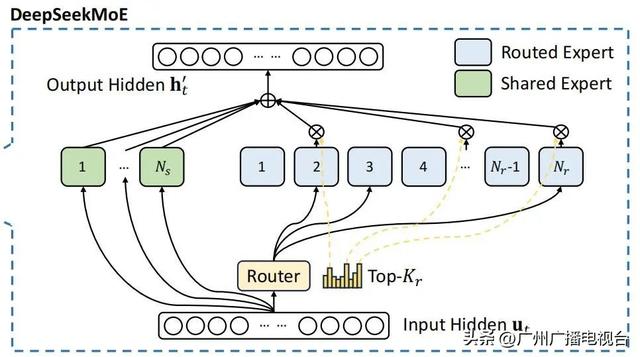
DeepSeek-V3混合专家模型
为了让专家模型高效工作,DeepSeek得有个聪明的调度员,确保“人尽其才”,因此,DeepSeek-V3装载了信息过滤器,叫做“MLA”(多头潜在注意力机制),它能让模型只关注信息中的重要部分,不会被不重要的细节分散注意力,根据用户输入的指令,动态分配到合适的专家进行处理。
这种设计确保模型在训练和推理时保持高效,通过这种机制,每次处理一个词元时激活6710亿参数中的5.5%,约370亿个,算力消耗大大降低。
这种创新的架构设计,不仅使得DeepSeek在面对大规模、复杂的任务时能够游刃有余,同时也在一定程度上降低了模型的计算成本,提高了模型的可扩展性和实用性,使其能够更好地适应多样化的应用场景和用户需求。
无辅助损失负载均衡
对于专家混合系统模型,不平衡的专家负载将导致路由崩溃。
DeepSeek创新在于,实现无辅助损失的自然均衡。DeepSeek-V3让训练过程中的专家各展所能,系统会根据专家的历史利用率,动态调整接收容量。当某个专家持续过载时,系统会自动降低接收新任务的概率;反之,对利用率低的专家,系统会提高接收任务的机会。
既考虑专业匹配度,也考虑当前工作负荷。这种自适应机制,确保长期来看的负载平衡。
强化学习助力AI 进化新路径
如果说传统AI训练是填鸭式教育,那DeepSeek则是靠自学的“天才少年”。
R1-Zero 模型的“自学”过程依赖于强化学习(RL)算法,而非传统的人类标注数据。通过反复训练和优化,尽管没有人工干预,它仍在特定的反馈机制下自我优化,最后在数学题目中展示出了卓越的推理能力。
这种自学方式与曾经战胜人类最强棋手的 AlphaGo有着异曲同工之妙。它并没有根据人类的围棋教程学习,全程也没有接受过任何人类输入的信号指导,完全依赖自己和自己“亿局局”下棋、胜负归纳总结,产生了强大的下棋策略。
更绝的是,DeepSeek还会把解题过程一步步推演,每一步都充满“如果……那么……”的逻辑推演,而且连中学生都能看懂它的思维过程。同时,它的训练方法还带来了效率提升,训练周期更短,资源消耗降低,由于省去了监督微调和复杂的奖惩模型,计算量减少。
DeepSeek思考过程
DeepSeek爆火的背后
开源策略是关键密码

开放生态:推动技术共享与创新
重塑全球AI格局
Deepseek的开源策略就像为AI世界的大门配备了一把万能钥匙,让众多开发者得以参与到模型的研究与优化中。
如今,这项技术已向全世界敞开大门。鉴于DeepSeek模型免费可得,其他公司或将不得不调整价格策略,以保持市场地位。
近段时间,国内外多家大模型厂商纷纷宣布免费开放其大模型服务。
百度2月13日发布消息,文心一言将于4月1日0时起全面免费,所有PC端和App端用户均可体验其最新模型,包括超长文档处理、专业检索增强、高级AI绘画、多语种对话等功能。
同日,OpenAI也宣布免费版ChatGPT将在标准智能设置下无限制使用GPT-5进行对话。
此外,谷歌最新人工智能模型套件也于近期宣布正式向所有用户开放使用。
降低开发门槛
对于中小企业和初创团队来说,DeepSeek的开源大大降低了AI开发的门槛。无需承担与资源密集型模型相关的高昂基础设施成本,利用DeepSeek的基础模型,就能快速搭建起自己的AI应用,将更多的精力和资源投入到业务创新和差异化竞争中,推动了 AI 技术在各个领域的快速普及。
DeepSeek的开源战略目前已经推动其模型快速渗透至教育、医疗、金融等垂直领域,AI应用正在遍地开花。
DeepSeek的成功
是中国AI人才培养、技术创新、
产业生态等方面全面崛起的缩影
这匹“黑马”以实力证明
中国科技企业有能力
在全球舞台上与顶尖玩家同台竞技
就像它的创始人梁文锋说的那样
中国的AI不可能永远跟随
需要有人站到技术的前沿
相关文章






关于作者

猜你喜欢
成员 网址收录40405 企业收录2983 印章生成240587 电子证书1066 电子名片60 自媒体63775































