
作者 | 许丽思编辑 | 漠影
机器人前瞻2月21日报道,近日,微软研究院发布了一个多模态AI模型——Magma。Magma是首个能够在其所处环境中理解多模态输入并将其与实际情况相联系的基础模型,只要提供一个描述性目标,Magma就能够制定计划、执行行动以达成该目标。
Magma以视觉语言(VL)模型为基础,除了保留传统的语言和视觉的理解能力(语言智能)外,还解锁了空间智能的新技能,能够从多模态输入(用户界面截图、机器人图像、教学视频)中理解对象的物理位置、动作的时序逻辑,并在不同环境(数字界面与物理世界)中完成连贯的任务。
值得一提的是,论文的作者中,13位有12位应该是华人。中美AI、机器人竞赛的背后,果然还是在美华人和在华中国人之间的较量。

将Magma和OpenVLA这两个模型应用到WidowX机械臂上,当让机械臂组装桌面上的热狗模型、把蘑菇模型放到盆中、把桌子上的抹布从左边移动至右边时,Magma可以让机械臂比较精确地完成任务,而OpenVLA则在物体抓取、移动上表现略逊色于前者。
Magma应用到WidowX机械臂并经过少样本的微调后,在分布内和分布外泛化任务中,都有着可靠的性能表现。

在LIBERO平台上进行的少样本微调,Magma在所有任务组中都取得了更高的平均成功率。
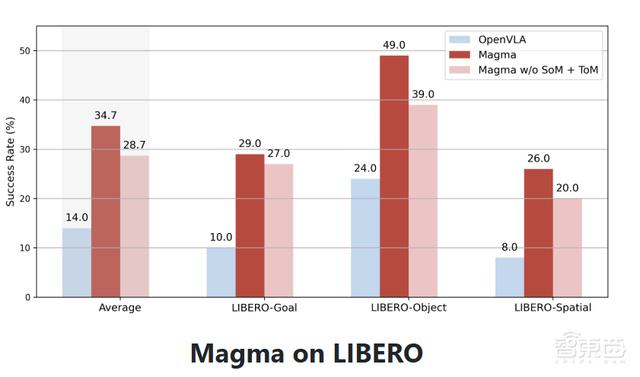
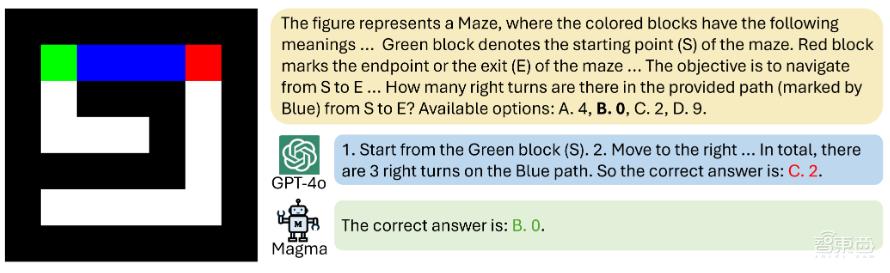
Magma成功整合了视觉、语言和行动,在机器人任务操作上表现出了较高的泛化能力。未来,随着模型研究的不断深入及模型规模的扩展,Magma也有望为解决更复杂的机器人操作问题提供不错的解决方案,让机器人距离真正的落地应用更进一步。
相关文章









关于作者

猜你喜欢
成员 网址收录40398 企业收录2981 印章生成236772 电子证书1047 电子名片60 自媒体48699































