大家好,我是运营黑客。
自从OpenAI官方全面放开「插件系统」之后,又掀起了一波ChatGPT学习、使用的热潮。
尤其是「联网插件」的放开,更是解除了ChatGPT的最后一道封印,让它可以实时调取最新的数据了。
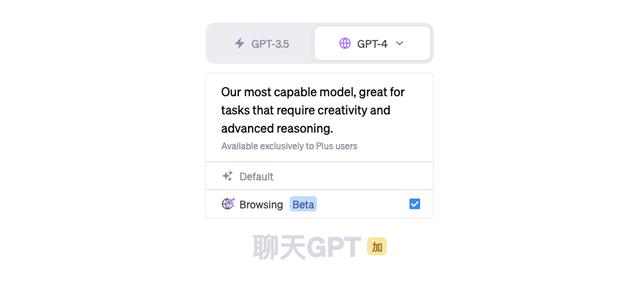
相比于传统版本的ChatGPT,在联网之后,它增加了哪些新的功能呢?
经过这两天的体验,我们总结了「联网版ChatGPT」的6大新增功能:
1. 搜索(query: str, recency_days: int)联网之后,ChatGPT可以在搜索引擎中发出查询并显示结果。
2. 点击(click: id: str)ChatGPT可以打开给定id的网页并显示它,将显示结果中的ID映射到一个URL。
3. 引用(quote: start: str, end: str)ChatGPT联网之后,可以通过起始子字符串“开始”和结束子字符串“结束”指定一个开放网页的文本范围,并记录它们的数据。
4. 返回(back())在联网时,ChatGPT调取的数据,支持返回到前一页并显示它。
5. 滚动(scroll: amt: int)ChatGPT可以在打开的网页中,向上或向下滚动给定的数量。
6. 打开URL(open_url: url: str)打开给定的URL并显示它。
4. 更新知识库限制:
尽管ChatGPT可以通过浏览器工具查找和引用最新的信息,但它不能根据这些信息更新自己的基础知识库。在2021年9月之后的知识并不会永久存储在ChatGPT的模型中。
5. 翻译和理解限制:
虽然ChatGPT可以访问非英文的网页,但它的理解和翻译能力可能会受到限制,特别是对于那些没有被大量训练的语言。
6. 内容解析限制:
对于复杂的可视化、图像或者嵌入式视频,我无法解析其内容。我只能处理和理解文本内容。
7.无法强行爬取网页内容:
有些网站的管理员设定了一些规则来限制爬虫或者自动化工具访问他们的网站,这些规则通常在一个叫做 "robots.txt" 的文件中指定。这个文件告诉爬虫哪些部分的网站可以访问,哪些部分不能访问。

以下是一些常见的限制:
① robots.txt文件:这是一个位于网站根目录的文件,它指定了哪些网页或网站区域是爬虫可以访问的,哪些是不允许访问的。如果robots.txt文件指定了不允许爬虫访问的区域,ChatGPT将会遵守这些规则,不会访问那些区域。
② Crawl-delay指令:这是在robots.txt文件中指定的一个指令,它告诉爬虫在连续请求网站的页面之间需要等待的时间。这是为了防止爬虫在短时间内发送过多的请求,从而对网站服务器造成过大的负载。
③ Noindex标签:这是一个可以在HTML页面中找到的标签,它告诉搜索引擎不要将该页面纳入搜索结果。虽然这不是一个针对爬虫的直接限制,但是它通常表示网站管理员不希望该页面被广泛访问。

④ AJAX和JavaScript:有些网页的内容是通过JavaScript或者AJAX动态生成的。这意味着,你需要执行JavaScript或者触发某些事件才能获取页面的完整内容。由于ChatGPT不能执行JavaScript或者触发事件,所以可能无法获取这些页面的全部内容。
⑤ 登录或付费壁垒:有些网站或网页需要登录或付费才能访问。ChatGPT不能进行这种类型的交互,因此无法访问这些内容。
⑥ CAPTCHAs:这是一种设计用来防止自动化工具访问网站的机制。如果一个网站使用了CAPTCHA,ChatGPT也将无法继续访问该网站。
6大新增功能 7个边界,这就是目前我们对「联网版ChatGPT」的整体测试结果,如果有些网页内容它无法读取、识别,大概率是触发了上面提到的「边界行为」。

相关文章









关于作者

猜你喜欢
成员 网址收录40394 企业收录2981 印章生成234927 电子证书1036 电子名片60 自媒体46925































