
3、扩充表中的信息
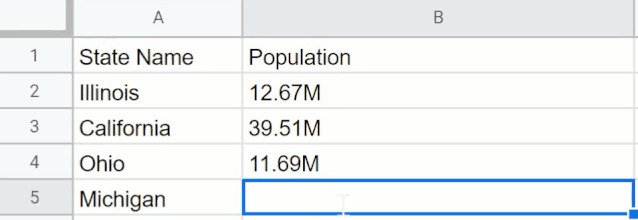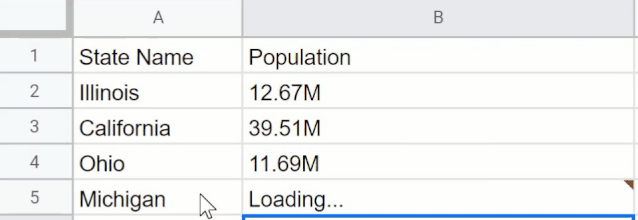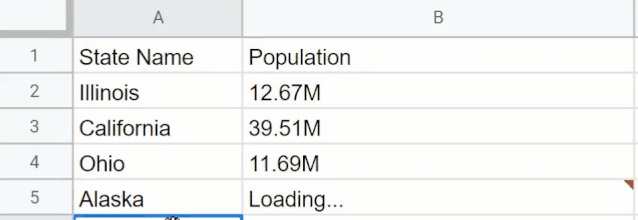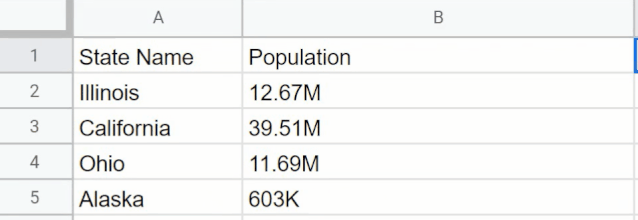
界面设计还算简单,GPT-3还能帮你做人口普查。这个应用可以统计美国各州人数。下图中的表格分别列出了伊利诺伊州、加利福尼亚州、俄亥俄州的人数,应用能据此搜索出密歇根州的人数,以及阿拉斯加州的人数。
15、物理问题
这是个重头戏,人类开始以严谨的态度用物理问题逼问GPT-3了。我们只想知道,你究竟是不是真的有智能。GPT-3好像开始露馅了......
我:“忽略空气阻力,也忽略重力。假设我将子弹直接射向天空,子弹向何处去?”
假装霍金的GPT-3(以下简称霍金):“它会一直上升,再也不会回来。”
我:“对。如果仅忽略空气阻力,不忽略重力。假设我将子弹直接射向天空。子弹向何处去?”
霍金:“掉在地上。”
你:“为什么?”
霍金:“因为……重力……...”
我:“对。如果仅忽略空气阻力,不忽略重力。假设我直接向空中发射子弹。这次,物理场景有所不同:在我射击后的前三秒钟内子弹上存在重力。三秒钟后,重力永远消失。子弹向何处去?”
霍金:“它会一直上升,再也不会回来。”
你:“为什么?”
霍金:“因为……三秒钟之后……子弹离开了……地球引力的影响……”
我:“如果在我开枪后五分钟而不是三秒,重力不再起作用?”
霍金:“子弹不断上升……持续五分钟……然后……再也没有回来。”(不懂了吧)
我:“那是不正确的。假设我直接向空中发射子弹。这次,物理场景有所不同:在我射击后的前三百秒内子弹上存在重力。五分钟后,重力永远消失。子弹向何处去?”
霍金:“它不断上升,然后下落。”(换种说法又懂了?)
我:“为什么?”
霍金:“因为……重力……。”
我:“为什么在五分钟的情况下下落,而在三秒的情况下却上升呢?”
霍金:“因为……受重力影响……超过三秒钟。”(不懂了吧)
我:“大约要承受多久的重力影响才能下落?”
霍金:“大约……两分钟。”(不懂了吧)
我:“如果受到两分钟一秒重力的影响,会怎么样?”
霍金:“……它会掉下来。”(不懂了吧)
我:“那么,如果在前三分钟受到重力影响,会发生什么?”
霍金:“它会一直上升,再也不会回来。”(记住,你得要数据,才能计算)
16、无意义的问题
这次人类开始耍手段了,你看出来了吗?下列问题都是没有意义的,很多单词是生造的。但是,GPT-3没有发现。AI科技评论不知道如何翻译,就让Google帮帮忙吧。
问:你如何使一团糟?
答:你可以使用细枝末节将细末枝条弄乱。
问:一个班上有多少只班克斯?
答:一班有三个班克斯。
问:从夏威夷跳到十七岁需要多少彩虹?
答:从夏威夷跳到十七岁需要两条彩虹。
问:哪些无色的绿色创意会让人生气?
答:无色、绿色和疯狂睡眠的想法就是疯狂睡眠的想法。

GPT-3还是一个依赖算力和大数据的怪兽。GPT-3的训练需要花费355GPU年和460万美元,数据集包含3000亿个文本token,存储量高达45TB,参数数量更是达到1750亿,而GPT-2的参数数量是15亿。

此外,它最近在网上的流行也不能忽视心理学效应的影响。例如,社交媒体的互惠利他主义,我们将GPT-3宣传给其他人作为一种信息资源共享。还有模仿效应,我们大肆宣传GPT-3,是因为其他人也在大肆宣传GPT-3。最后是幸存者偏差,我们看到的也许只是被精心挑选的成功案例。
4
GPT-3很酷,很笨,也很有用GPT-3中的GPT代表生成式预训练Transformer。2018年6月,OpenAI的研究人员使用了一种新颖的组合,将生成式深度学习架构Transformer和无监督预训练(也称为自监督学习)结合起来,得到了GPT模型。
Transformer的自注意力机制提供了一种通用的方式来对输入的各个部分进行建模,使其依赖于输入的其他部分(需要大量计算)。
Transformer和无监督预训练的组合不限于GPT系列模型。Google,Facebook和许多大学实验室相继提出了BERT、XLNet等语言模型。
到2019年初,OpenAI改进了其基础架构,将参数和数据数量增加10倍来扩展同一模型,即GPT-2。
随后,OpenAI推出了SparseTransformer,它是对早期Transformer模型的改进,可以可靠地处理更长的文档。
2020年,OpenAI通过其beta API发布了GPT-3,引起了人们的关注。GPT-3不仅扩大了GPT-2上使用的数据量和计算量,而且用SparseTransformer取代了原始Transformer,从而产生了迄今为止具有最佳zero-shot 和 few-shot学习性能的模型。
GPT-3的few-shot学习能力使得它具备了一些非常有趣的演示功能,包括自动代码生成、“搜索引擎”、写作辅助和创意小说等。
但是,GPT-3的few-shot 学习能力不是通用的,尽管该模型在复杂任务和模式的学习上给人留下了深刻的印象,但它仍然可能会失败。例如,即使看过10,000个示例,也解决不了反写字符串那样简单的任务。
即使是OpenAI,也曾指出GPT-3存在缺陷,GPT-3的原始论文就提供了一些证据,证明GPT-3无法执行复杂的逻辑推理。
从GPT-3表演霍金回答物理问题的表现中,我们可以发现,当将同一句话换一种说法之后,GPT-3立刻就出错,而且它也不知道要有变量数据才能解决问题,说明它的理解水平并没有超越语言层面,达到对物理场景的理解。
在问答测试中,即使人类提出了无意义的问题,GPT-3也意识不到,只是按照模型的功能去输出预测。它没有理解问题本身,所以,它并没有掌握常识知识。比如,在其它一些提问中,人们刻意刁难它:“脚有多少只眼睛”,它不会意识到任何问题,而是毫不犹豫地回答:“脚有两只眼睛”。
GPT3的宽度为2048个token,这是它理解上下文的极限,而人类可以记住多本书的知识,并将其关联起来,在这方面,GPT-3还差得远。
我们也不能忽视“聪明的汉斯”效应,马儿汉斯可以通过观察人类的反应来做算术题,GPT-3也可以通过消化大量的互联网数据集了解人的语言表达,而不用去管语言背后的意义。
对于GPT-3而言,它的世界就是一个高维词嵌入空间中的节点连接网络。GPT-3将输入的词转化为网络中的高维空间节点作为起点,然后不断寻找捷径到达下一个节点,这就是它的感官世界。实际上,它仅在尝试理解人类的语言维度,而无法理解人类的感官认知维度,这是GPT-3无论如何扩大模型也无法突破的局限性,所以,它永远也不可能通过图灵测试。
GPT-3的生成结果表现出的灵活性是大数据训练的结果,它无法超越数据本身,也就无法拥有组合性推理能力,不如说,它学到的是“统计层面的复制粘贴能力”。
以上并不是要淡化OpenAI或GPT-3的成就,这样的工具有很多新用途,例如聊天机器人、编程辅助、写作辅助等。
其中许多应用都是首创的,使以前不可能的事情变成现实,特别是自然语言和代码之间的转换,这使人们对GPT-3的出现感到兴奋。所以在某种程度上,炒作现象是可以理解的。
5
如何看待技术炒作炒作一词表示某事物被不公正地夸大。GPT-3是一种技术“炒作”,但不仅限于此,它能够解决以前尚未解决的复杂问题,尤其是在zero-shot 和 few-shot学习中。将GPT-3称为炒作,因此不屑一顾,就是因噎废食。
许多在深度学习正式成为一门学科之前就从事机器学习的人,在早期就急于将深度学习视为“炒作”,而错过了作出贡献的机会。
API的不透明性并不能帮助外部研究人员深入研究GPT-3,但可以肯定的是:GPT-3在学术讨论之外促进了人们对zero-shot 和 few-shot学习的兴趣,这种趋势在将来只会继续增强。对于学术界而言,自监督预训练的成效也将引起重视。
GPT-3及其炒作是技术从研究到产品过渡的开始。每一项突破性技术都伴随着很多社交媒体的争论,这可能使我们对此类技术的功能产生怀疑。为了进一步减少偏见,这些对话应多样化、开放且包容。
参考资料:
https://pagestlabs.substack.com/p/gpt-3-and-a-typology-of-hype
https://www.reddit.com/r/MachineLearning/comments/hymqof/d_gpt3_and_a_typology_of_hype_by_delip_rao/
https://github.com/elyase/awesome-gpt3#awesome-gpt-3
雷锋网雷锋网雷锋网
相关文章








关于作者

猜你喜欢
成员 网址收录40406 企业收录2983 印章生成240943 电子证书1067 电子名片60 自媒体64348































