机器之心专栏
张傲,费豪,姚远,吉炜,黎力,刘知远,Chua Tat-Seng
机构:新加坡国立大学,清华大学
最近的多模态(对话)大模型将基于文本的 ChatGPT 的强大能力扩展到了多模态输入,实现强大的多模态语义理解,比如 GPT-4、BLIP-2、Flamingo 等。但对于很多研究者来说,训练一个多模态 GPT 代价非常昂贵。本文来自新加坡国立大学和清华大学的研究者提出了一个名为 VPGTrans 框架,以极低成本训练高性能多模态大模型。

图 2:VL-Vicuna 的交互实例
一、动机介绍
1.1 背景
2023 年是 AI 元年,以 ChatGPT 为代表的大语言模型 (LLM) 大火。LLM 除了在自然语言领域显示出巨大的潜力之外,也开始逐渐辐射到其他相关领域。比如,LLM 在多模态理解领域掀起了一股从传统预训练视觉语言模型 (VLM) 到基于大语言模型的视觉语言模型 (VL-LLM) 的变革。通过为 LLM 接入视觉模块,VL-LLM 可以继承已有 LLM 的知识,零样本泛化能力,推理能力和规划能力等。相关模型有 BLIP-2 [1],Flamingo [2],PALM-E 等。
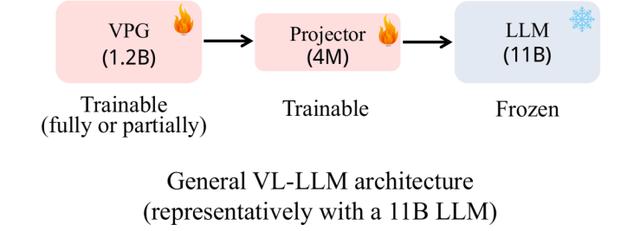
图 3:常用的 VL-LLM 架构
现有的常用的 VL-LLM 基本采取图 3 所示的架构:在一个基座 LLM 基础上训练一个视觉 soft prompt 生成模块 (Visual Prompt Generator, VPG),以及一个进行维度变换的线性层 (Projector)。在参数规模上,LLM 一般占主要部分 (比如 11B),VPG 占次要部分 (比如 1.2B),projector 最小 (4M)。在训练过程中,LLM 参数一般不会被更新,或者仅仅更新非常少量的参数。可训练参数主要来自于 VPG 和 projector。
1.2 动机
实际上,即便基座 LLM 的参数冻结不训,但由于 LLM 的大参数量,训练一个 VL-LLM 的关键开销依然在于加载基座 LLM。因此训练一个 VL-LLM 依然无法避免极大的计算代价。比如,要得到 BLIP-2(基座 LLM 为 FlanT5-XXL)需要付出超过 600 个小时的 A100 训练时长。如果租用亚马逊的 A100-40G 机器,大概需要将近 2 万元人民币的费用。既然从零训练一个 VPG 代价如此昂贵,那么我们开始思考能否把一个已有的 VPG 迁移到新的 LLM 上来节省开销。
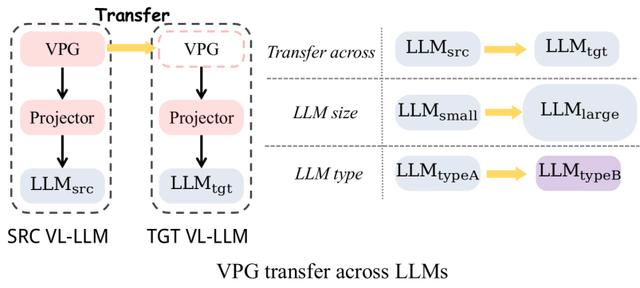
的 projector 的初始化。通过这个初始化,我们可以将 projector 的 warm-up 训练由 3 个 epoch 减为 2 个 epoch。
(4) projector 可以在超大学习率下快速收敛:我们进一步实验发现,projector 由于其参数量较少,可以使用 5 倍的正常学习率进行训练而不崩溃。通过 5 倍学习率的训练,projector warm-up 可以进一步被缩短到1个 epoch。
(5) 一个附加发现:虽然 projector warm-up 很重要,但仅训练 projector 是不够的。尤其在 caption 任务上面,仅仅训练 projector 的效果要比同时训练 VPG 的效果差一截 (图 5 绿线在 COCO Caption 和 NoCaps 均远低于蓝线)。这也就意味着,仅仅训练 projector 会导致欠拟合,无法充分对齐到训练数据。
2.2 我们所提出的方法
表 1:我们的 VPGTrans 的相比于从头训练在各个数据集的加速比
如表 1 所示,我们测试了在不同迁移类型下,VPGTrans 在不同数据集上的加速比。VPGTrans 在某指定数据集 A 上的加速比是通过从头训练达到 A 上最佳效果 a 的轮数除以 VPGTrans 在 A 上效果超过 a 的最小训练轮数得到。比如,从头在 OPT-2.7B 上训练 VPG,在 COCO caption 达到最佳效果需要 10 个 epoch,但从 OPT-125M 迁移 VPG 到 OPT-2.7B,仅需 1 个 epoch 就能达到该最佳效果。则加速比为 10/1=10 倍。我们可以看到,无论是在 TaS 还是在 TaT 场景下,我们的 VPGTrans 都可以实现稳定的加速。
3.2 有趣的发现
我们选取了一个比较有趣的发现进行了说明,其他更多更有意思的发现请参照我们的论文。
TaS 场景下,越小的语言模型上训练的 VPG,迁移起来效率越高,最后模型效果越好。参考表 1,我们可以发现 OPT-1.3B 到 OPT-2.7B 的加速比要远小于 OPT-125M、OPT-350M 到 OPT-2.7b 的加速比。我们尝试提供了一个解释:一般越大的语言模型,由于其文本空间的维度更高,会更容易损害 VPG (VPG 一般都是类似于 CLIP 的预训练模型) 本身的视觉感知能力。我们通过类似于 linear probing 的方式进行了验证:
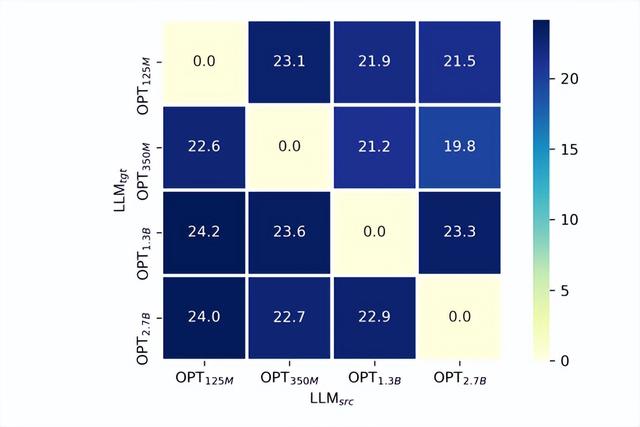
图 8:仅训练 linear projector 层的跨 LLM 大小迁移 (模拟 linear probing)
如图 8 所示,我们进行了 OPT-125M,350M,1.3B,2.7B 之间的跨 LLM 大小的迁移。在实验中,为了公平对比不同模型大小下训练过的 VPG 的视觉感知能力,我们固定住 VPG 的参数仅仅训练 linear projector 层。我们选取了 COCO Caption 上的 SPICE 指标作为视觉感知能力的衡量手段。不难发现,对于每一个给定的
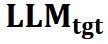
表3:VL-LLaMA 的效果展示
同时,我们的 VL-Vicuna 可以进行多模态对话。我们和 MiniGPT-4 进行了简单的比较:

五、总结
在这项工作中,我们对 VPG 在 LLM 之间的可迁移性问题进行了全面调查。我们首先探讨了最大化迁移效率的关键因素。基于关键观察,我们提出了一种新颖的两阶段迁移框架,即 VPGTrans。它可以在显著降低训练成本的同时,实现相当或更好的性能。通过 VPGTrans,我们实现了从 BLIP-2 OPT-2.7B 到 BLIP-2 OPT-6.7B 的 VPG 迁移。相较于从零开始连接 VPG 到 OPT 6.7B,VPGTrans 仅需 10.7% 训练数据和不到 10% 的训练时长。此外,我们展示并讨论了一系列有趣发现及其背后的可能原因。最后,我们通过训练 VL-LLaMA 和 LL-Vicuna,展示了我们的 VPGTrans 在定制新的 VL-LLM 方面的实际价值。
相关文章




关于作者

猜你喜欢
成员 网址收录40406 企业收录2984 印章生成241596 电子证书1079 电子名片61 自媒体64547































