编辑:编辑部
【新智元导读】如今爆火的ChatGPT,曾经和马斯克还有一段七年的「纠葛」。最近,OpenAI发布了史上最强聊天机器人ChatGPT,这个诞生于GPT-3基础上的AI很快走红网络。
要说这家伙,天南海北无所不知,可能是夸张了点,但就是无论什么话题都能跟你聊上一大套,先不说准不准,最起码这个范儿是在这儿了

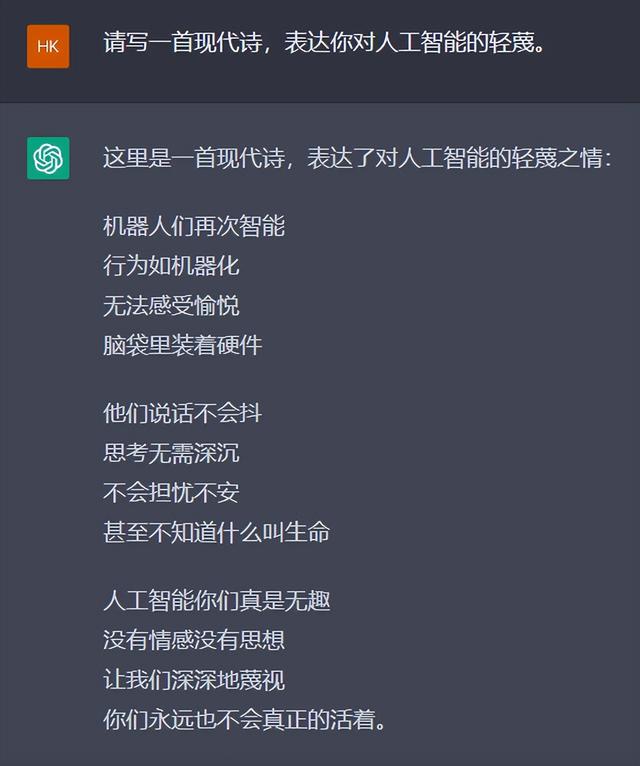
写得很好,但不要再写了……
不如……咱们让ChatGPT来写一首贬低自己的诗,如何?
2019年,马斯克在Twitter上说,特斯拉也在争夺与OpenAI相同的一些员工,并补充说他已经有一年多没有参与这家公司的事务了。
他说:「如此看来,最好还是以彼此都满意的条件分道扬镳。」
马斯克近年来不断对OpenAI的一些做法提出异议。

微软表示,通过GPT-3模型打造出的商业和创造潜力是无限的,很多潜在的新能力和新应用,甚至超出了我们的想象。
比如在写作和作曲上、在描述和总结大块长篇数据(包括代码)上、在将自然语言转换为另一种语言等领域,GPT-3能够直接激发人类的创造力和聪明才智,未来的局限可能在于我们自己的想法和方案。
这种伙伴关系,让微软能够与谷歌旗下同样风头正劲的AI公司DeepMind竞争。
去年,OpenAI发布了一个人工智能画作生成工具:Dall-E。

ChatGPT用中文解释什么是RLHF
为什么会想到从人类反馈中强化学习呢?这就要从强化学习的背景说起。
在过去几年里,语言模型一直是通过人类输入的提示生成文本的。
然而,什么是「好」的文本呢?这很难定义。因为判断标准很主观,并且非常依赖于上下文。
在许多应用程序中,我们需要模型去编写特定创意的故事、信息性文本片段,或可执行的代码段。
而通过编写一个损失函数来捕获这些属性,又显得很棘手。并且,大多数语言模型仍然使用的是下一个标记预测损失(例如交叉熵)进行训练。
为了弥补损失本身的缺点,有人定义了能够更好地捕捉人类偏好的指标,比如BLEU或ROUGE。

奖励模型训练
生成一个根据人类偏好校准的奖励模型(RM,也称为偏好模型)是RLHF中相对较新的研究。
我们的基本目标是,获得一个模型或系统,该模型或系统接收一系列文本,并返回一个标量奖励,这个奖励要在数字上代表人类偏好。
这个系统可以是端到端的LM,或输出奖励的模块化系统(例如,模型对输出进行排序,并将排名转换为奖励)。作为标量奖励的输出,对于稍后在RLHF过程中无缝集成的现有RL算法至关重要。
这些用于奖励建模的LM可以是另一个经过微调的LM,也可以是根据偏好数据从头开始训练的LM。
RM的提示生成对的训练数据集,是通过从预定义数据集中采样一组提示而生成的。提示通过初始语言模型生成新文本。
然后,由人工注释器对LM生成的文本进行排名。人类直接对每段文本打分以生成奖励模型,这在实践中很难做到。因为人类的不同价值观会导致这些分数未经校准而且很嘈杂。
有多种方法可以对文本进行排名。一种成功的方法是让用户比较基于相同提示的两种语言模型生成的文本。这些不同的排名方法被归一化为用于训练的标量奖励信号。
有趣的是,迄今为止成功的RLHF系统都使用了与文本生成大小相似的奖励语言模型。可以推测,这些偏好模型需要具有类似的能力来理解提供给它们的文本,因为模型需要具有类似的能力才能生成所述文本。
此时,在RLHF系统中,就有了一个可用于生成文本的初始语言模型,和一个接收任何文本并为其分配人类感知程度分数的偏好模型。接下来,就需要使用强化学习(RL)来针对奖励模型优化原始语言模型。

使用强化学习微调
这个微调任务,可以表述为RL问题。
首先,该策略是一种语言模型,它接受提示并返回一系列文本(或只是文本的概率分布)。
该策略的动作空间是语言模型词汇对应的所有token(通常在50k个token数量级),观察空间包括可能的输入token序列,因而相当大(词汇量x输入的token数量)。
而奖励函数是偏好模型和策略转变约束的结合。
在奖励函数中,系统将我们讨论过的所有模型,组合到RLHF过程中。
根据来自数据集的prompt x,会生成两个文本y1和y2——一个来自初始语言模型,一个来自微调策略的当前迭代。
来自当前策略的文本被传递到偏好模型后,该模型会返回一个关于「偏好」的标量概念——rθ。
将该文本与来自初始模型的文本进行比较后,就可以计算对它们之间差异的惩罚。
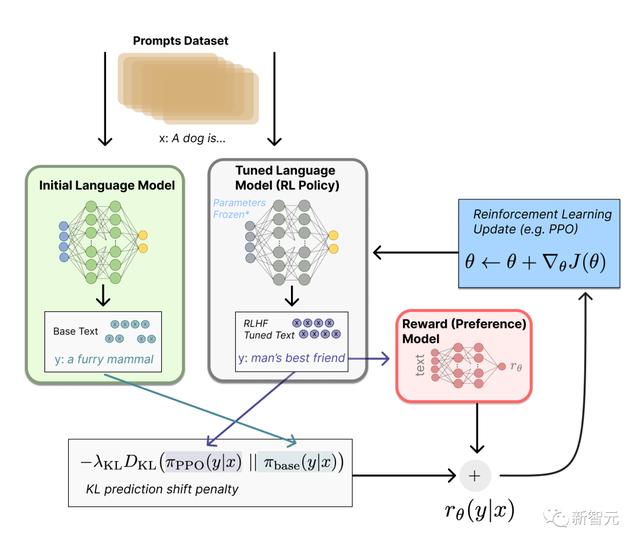
RLHF可以通过迭代更新奖励模型和策略,从这一点继续。
随着RL策略的更新,用户可以继续将这些输出与模型的早期版本进行排名。
这个过程中,就引入了策略和奖励模型演变的复杂动态,这个研究非常复杂,非常开放。
参考资料:
相关文章







关于作者

猜你喜欢































