ChatGPT再次进化,迎来大更新和大降价。
当地时间6月13日,OpenAI宣布对其大型语言模型API(包括GPT-4和GPT-3.5-turbo)进行重大更新,包括新增函数调用功能、降低使用成本等多项内容。更新后,嵌入式模型成本下降75%,同时为GPT-3.5-turbo增加了16000(此前为4000)的输入长度。主要更新内容:
· 在Chat Completions API 中增加了新的函数调用能力;
· 推出新版本GPT-4-0613和GPT-3.5-turbo-0613模型;
· GPT-3.5-Turbo上下文长度增长4倍,从4k增长到16k;
· GPT-3.5-Turbo输入token降价25%;
· 最先进embeddings model降价75%;
· 公布GPT-3.5-Turbo-0301 和 GPT-4-0314 模型的淘汰时间表。
本次更新中,备受关注的是函数调用能力。据华尔街见闻报道,开发者现在可以向GPT-4-0613和GPT-3.5-turbo-0613两个模型描述函数,并让模型智能地选择输出一个包含参数的JSON(JavaScript Object Notation,一种数据交换的文本格式)对象,来调用这些函数。若将GPT功能与外部工具或API进行连接,这种方法更加可靠。
也就是说,GPT不再需要开发者描述复杂的提示语,它自己能够决定是否动用外部工具来解决问题,不仅显著提高了反应速度,还大大降低了出错的可能性。
此外,OpenAI发布的降价消息也让不少用户为之欢呼。官网公告显示,不同版本降价幅度不同,OpenAI最先进、用户最多的嵌入模型Text-embedding-ada-002降价75%;用户最多的聊天模型GPT-3.5-turbo降价25%。OpenAI首席执行官Sam Altman此前在新加坡管理大学演讲时表示,OpenAI每三个月左右就能将推理成本降低90%,未来将继续大幅削减成本。
人工智能时代正在到来。ChatGPT作为一个窗口,让我们得以提前窥见AI世界。本文对ChatGPT的基本技术原理进行了分析和解读,可供读者学习和参考,推荐阅读。
作者简介:浙江大学信电学院副教授,2002年清华大学电子工程系专业本科毕业,2007年英国南安普敦大学电子与计算机工程系博士毕业,博士期间的研究方向是人脸识别和说话人识别的融合算法。2007-2009 年在比利时鲁汶大学通信与遥感实验室从事博士后研究工作,研究方向为三维网格数字水印。2009 年12 月起为浙江大学信息与电子工程学院讲师,2013年晋升副教授并担任信息与通信工程系副系主任。目前主要研究方向为计算机视觉、机器学习、深度网络模型压缩和加速等。在国际顶级期刊和会议上发表论文70多篇,包括TIP, PR, AAAI, CVPR等,主持多项国家和省级科研项目。他的机器学习视频课程在BILIBILI网站上获得超过100万点击量。本文为胡浩基教授在全球数字金融中心(杭州)举行的“科技向善:强AI时代的变革”人工智能与数字金融研讨会发言。

Transformer网络基本结构图
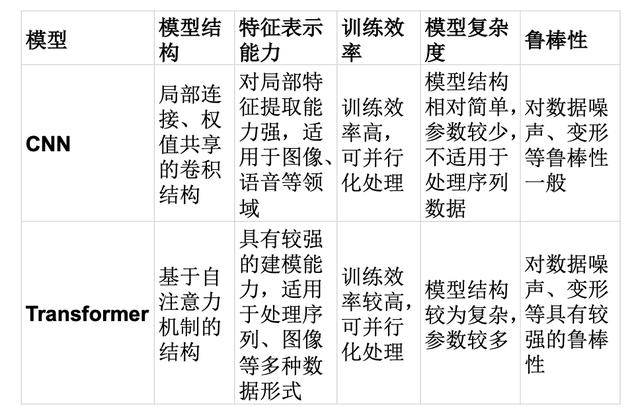
CNN与Transformer特点对比
Swin Transformer是将Transformer用在计算机视觉领域的成功模型
参考文献
(1) J. Devlin, M. –W. Chang, K. Lee and K. Toutanova, BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding, in NAACL-HLT 2019, pp. 4171–4186, 2019. (BERT将Transformer网络应用于自然语言理解中,在多个自然语言处理任务上获得很好效果,这一研究成果推动了charGPT的出现).
(2) Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin and B. Guo, Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows, in ICCV 2021, pp. 1-14, 2021 (Transformer在计算机视觉领域的表现不够好,直到2021年微软亚洲研究院的这篇Swin Transformer,将CNN的一些结构和Transformer结合,终于获得了很好的效果,这一研究成果推动了Transformer在计算机视觉领域的普及).
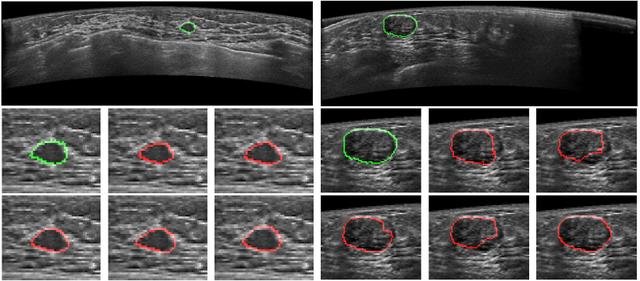
从2021年开始,我们实验室也基于Transformer也做了一些工作,尤其是在医学图像处理领域。如下是我们基于Transformer对二维乳腺自动超声肿瘤图像和三维牙齿口扫图像进行分割,获得了很好的结果。
预训练的魔力之二,就是刚才张岩老师讲的涌现能力,随着模型和数据增加到一定的地步了,整个模型的能力会快速的增长。由于张老师很详细的讲到了这一点,我就不再赘述了。
除了预训练之外,ChatGPT还用了一个关键技术,叫做强化学习。这是OpenAI描述ChatGPT中如何进行强化学习的论文-- Reinforcement Learning with Human Feedback (RLHF)。翻译过来就是,带有人类反馈的强化学习。它大概说的是什么意思?
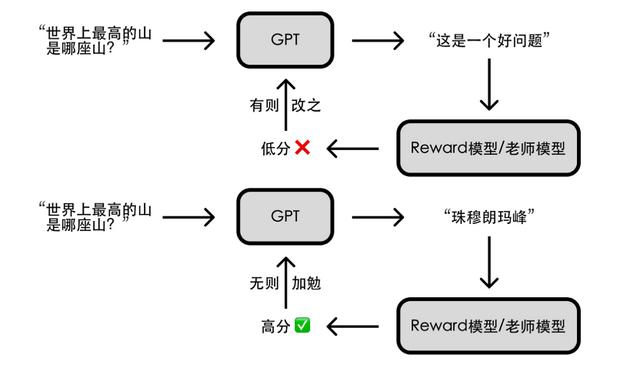
当我们经过了预训练,经过了具体任务的微调还是不够的,我们要把人的价值观展现给计算机。人对于什么文章是好的,什么文章是不好的,需要加以评判,并把这个评判结果告诉计算机,这样计算机就能生成人类觉得好的文章。比如说,你问“世界上最高的山是哪一座?”,GPT有可能接下面一句话,“这是一个好问题”。这个答案虽然逻辑是通的,但是它的回答是不好的。因此我们需要有一个人类的老师来监督,对好的回答给个高分,对不好的回答给个低分。比如说,你问“世界上最高的山是哪一座?”如果回答是“珠穆朗玛峰”,那么要给一个高分;而如果回答“这是一个好问题”,就要给个低分。OpenAI公司内部有一套详细的实训手册,就是要统一告诉进行标注的人类老师什么答案是好的,什么答案是不好的。它要有一个非常统一的对于好和不好答案的认识,这样才能让训练变得更加的统一,容易收敛。
第二个思考,人类的语言是无限创造力和发展可能性的源泉,还是人工智能可以穷尽的符号的排列组合?在这里,我想起了高中语文的课文《最后一课》,语言是一个民族的骄傲,也是我们人类的创造力源泉。如果离开了语言,我们将没有文学、艺术,诗歌和音乐,也没有进行任何思考的工具。但是,现在ChatGPT用这种粗暴的统计手段,将语言变成了符号的排列组合问题,那么人作为一种主体,尊严何在?一个重要的问题是,ChatGPT所生成的那些文字,是否跟人类产生的文字有本质的区别呢?如果有区别,发现并找出这种区别,是有关人类生存尊严的重要问题。
第三个思考是关于经济和金融领域。今天是一个经济和金融的论坛,我想和大家讨论在公司创业过程中“利”和“义”的关系问题。Open AI这家公司自称是一个非盈利机构,公司的目标是实现通用的人工智能以便造福人类社会。当然,他们这样说,不见得会这样做。这里我想到,在2019年我去参加一个人工智能大会NeurIPS的时候,大会请了一个美国开公司的女性CEO做报告,这个CEO明确的说,我们公司不追求利润,也不追求上市,我们的目标是为了在全人类实现公平。这是一张她解释平等和公平区别的图,平等是给每一个人一个小板凳,而公平是给那些矮的人两个小板凳,而对那些高的人就不要给他小板凳了。
以上话题涉及到经济和金融政策,也涉及到价值判断,这些领域我都不是专家,因此我很想听一下大家的见解,和大家一起共同学习进步。
End.
往期推荐
这里有一份数字人才的就业地图
137部数字经济政策,透露了什么信号?
三大互联网巨头的云计算盘点
隐私计算九问!涉及断直连、ChatGPT
以App为支点,宇宙行进击AGI时代
蓝色的支付宝,底层越来越“绿”
零售业务运营突围,银行表情包走“心”

上抖音“零壹朋友圈”,零听大咖说征信
“数据经济的崛起与个人隐私的博弈”精华视频已上线
转载、合作、交流请留言,
数据与商业合作:13261990570(微信同号)
客服微信:lycj002
来个“分享、点赞、在看、设为星标”
相关文章









关于作者

猜你喜欢
成员 网址收录40404 企业收录2983 印章生成238877 电子证书1061 电子名片60 自媒体58439































